
Concevoir une Architecture pour une Application E-commerce
Ce projet a pour but de concevoir une application e-commerce simple en commençant par une architecture monolithique, puis en la refactorant en microservices, et enfin en proposant une approche serverless pour certaines fonctionnalités. L’idée, c’est de mieux comprendre les avantages, les défis, et les cas d’usage de chaque style architectural.
Super expérience d’apprentissage : c’était hyper formateur. En bossant directement sur la conception et la mise en œuvre, j’ai pu mieux capter les vraies problématiques derrière la construction d’un système scalable et résilient.
1 - Besoins
2 - Partie 1 : Architecture Monolithique
3 - Partie 2 : Architecture Microservices
4 - Partie 3 : Architecture Serverless
5 - Comment choisir ?
Besoins
Fonctionnalités Clés
L’application doit permettre les opérations suivantes :
- Afficher les articles : catalogue produit
- Acheter des articles : panier + gestion des commandes
- Inscription et connexion utilisateur
Exigences de l’Architecture
Pour être efficace et s’adapter aux besoins des utilisateurs, l’architecture doit être :
- Scalable : pouvoir gérer des millions d’utilisateurs et de requêtes en simultané.
- Résiliente : tolérante aux pannes, dispo en permanence.
- Économe : optimiser les ressources pour équilibrer coûts et performances.
- Sécurisée : garantir la sécurité des données et bloquer tout accès non autorisé.
Partie 1 : Architecture Monolithique
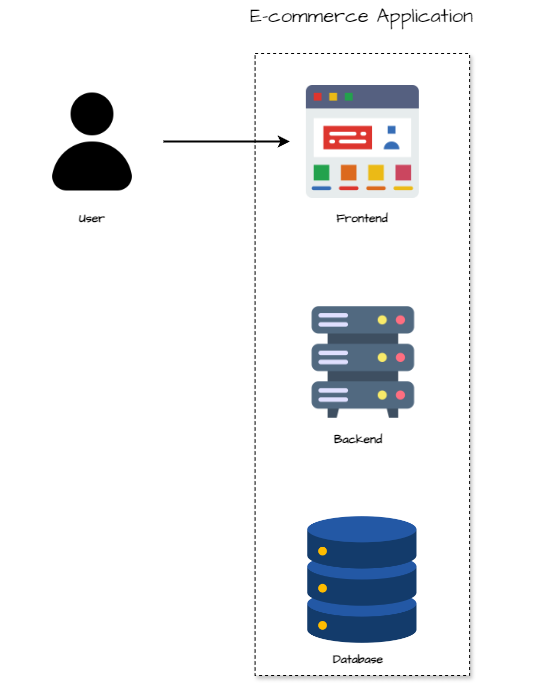
Composants
L’architecture monolithique suit un modèle en couches où toutes les fonctionnalités sont regroupées dans une seule unité de déploiement. Voici un aperçu de sa structure :
- UI Layer : Contient tous les éléments front-end, c’est l’interface utilisateur (web ou mobile).
- Business Logic Layer : Regroupe toute la logique métier de l’application (gestion utilisateurs, catalogue produits, panier, commandes).
- Data Interface Layer : Une interface unique vers la base de données, qui contient toutes les tables (utilisateurs, produits, paniers, commandes).
Workflow
-
UI Layer : Peut être une appli web ou mobile.
- L’utilisateur navigue dans le catalogue, gère son panier, passe commande…
-
Business Logic Layer : C’est le cœur fonctionnel de l’appli :
- User Management Module : Gère l’inscription, la connexion, et les profils.
- Product Catalog Module : Gère les produits, catégories, filtres, etc.
- Shopping Cart Module : Gère l’ajout, la suppression ou la mise à jour des produits dans le panier.
- Order Processing Module : Gère la création de commande, le paiement et le suivi.
-
Database :
- Une seule base de données stocke toutes les données de l’application.
Avantages
- Simplicité : Un seul bloc de code à gérer, plus facile à développer et à comprendre.
- Uniformité : Tout est déployé ensemble, donc moins de composants à coordonner.
- Performances : Les échanges entre modules sont très rapides, car tout tourne dans le même processus.
- Tests simplifiés : Les modules étant intégrés ensemble, on peut tester plus facilement l’ensemble des fonctionnalités.
Inconvénients
- Scalabilité : Pour scaler, il faut répliquer toute l’application. Pas très efficace en termes de ressources.
- Flexibilité limitée : Une modification dans un module peut impacter tout le reste. Le risque de “casser quelque chose” est élevé.
- Déploiement lourd : Même un petit changement nécessite de redeployer toute l’application, ce qui rallonge les cycles et peut générer des coupures.
- Forte dépendance : Tout est fortement couplé, ce qui rend difficile l’évolution ou le développement de nouvelles fonctionnalités de manière isolée.
Partie 2 : Refactorisation en Microservices
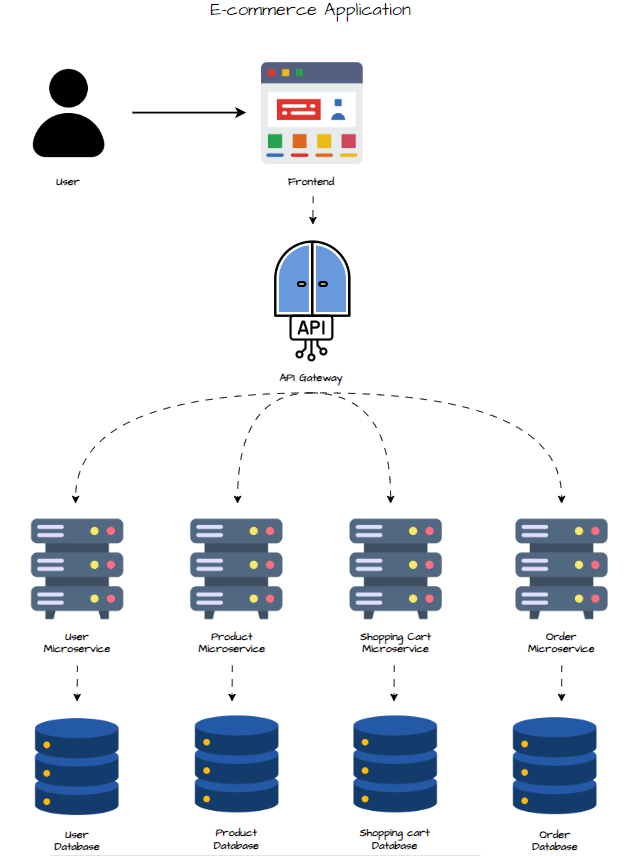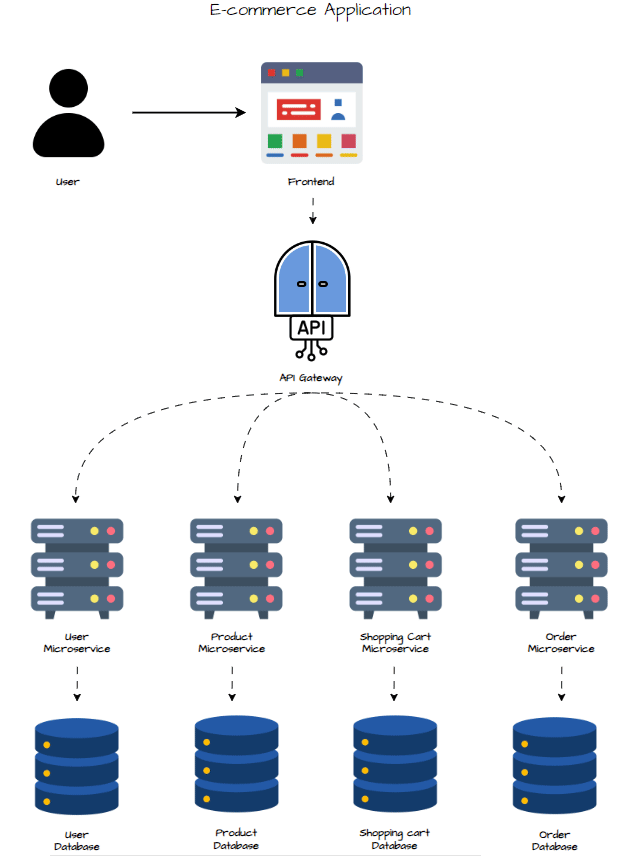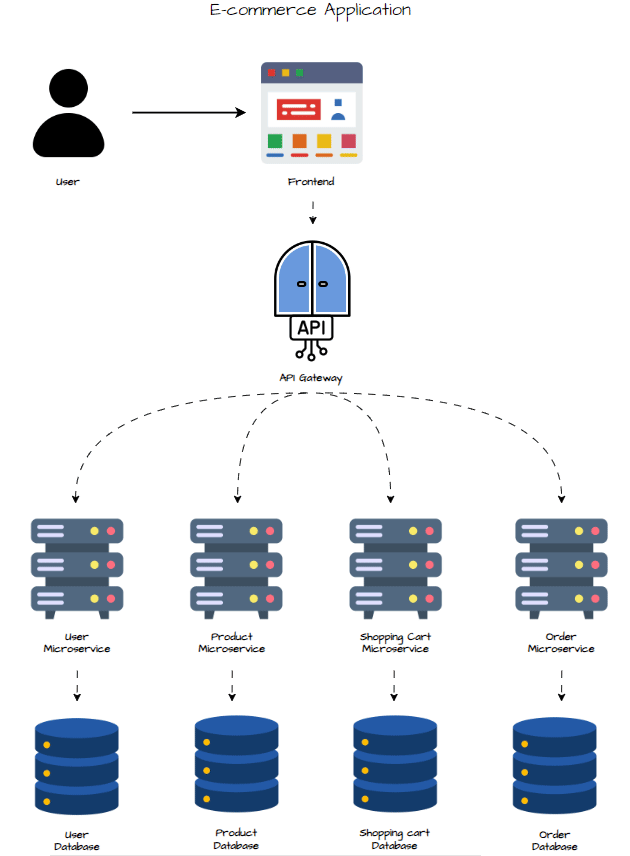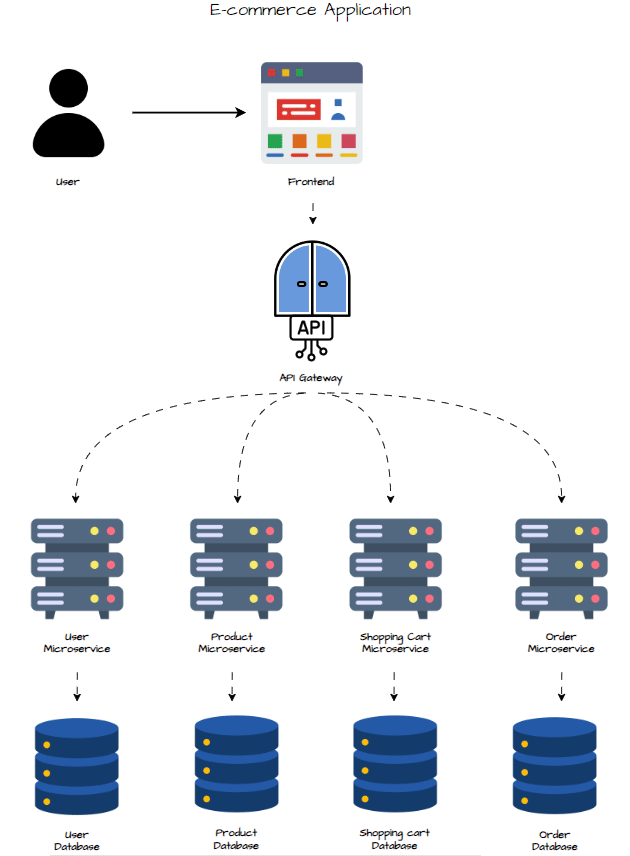
Conception des Microservices
Pour découper l’architecture monolithique, on identifie les fonctionnalités principales qui peuvent être isolées en services indépendants, déployables séparément. L’application e-commerce peut être divisée comme suit :
- User Service : Gère l’inscription, la connexion et les profils utilisateurs.
- Product Service : Gère le catalogue produits (listing, recherche, détails…).
- Cart Service : Gère le panier (ajout, mise à jour, suppression d’articles).
- Order Service : Gère les commandes (création, paiement, suivi…).
Chaque microservice possède sa propre base de données pour garantir un faible couplage et une indépendance totale.
Workflow
- UI Layer : L’utilisateur interagit avec l’interface. Celle-ci envoie les requêtes à l’API Gateway.
- API Gateway : Redirige les requêtes vers le bon microservice (User, Product, Cart, Order).
- Microservices : Exécutent leurs opérations en interaction avec leurs propres bases de données. Ils peuvent aussi communiquer entre eux si nécessaire.
- Base de Données : Chaque service interroge sa base au besoin.
- Réponse : Le résultat passe par l’API Gateway pour être renvoyé à l’interface utilisateur.
Avantages
-
Scalabilité : Chaque service peut scaler indépendamment selon sa charge. Si le catalogue produits subit beaucoup de trafic, on scale uniquement le Product Service. Cela permet d’optimiser les ressources et de réduire les coûts.
-
Flexibilité : Chaque service est faiblement couplé, très cohérent, et se concentre sur une fonctionnalité unique. Ça permet aux équipes de développer, tester et déployer de manière indépendante. Chaque service peut même utiliser des technos différentes (langage, base de données…), selon ce qui est le plus adapté.
Inconvénients
-
Complexité de déploiement : Déployer des microservices est plus complexe qu’un monolithe. Chaque service a son propre pipeline CI/CD, sa config, son infra… Il faut une bonne automatisation pour gérer les mises en prod fréquentes.
-
Communication inter-services : Les services doivent souvent communiquer entre eux, ce qui amène des problématiques comme la latence réseau, la découverte de services ou la résilience. Il faut gérer les retries, les fallbacks et les circuit breakers pour que le système reste fiable.
-
Consistance des données : Dans un monolithe, c’est simple car tout le monde utilise la même base. Dans une archi microservices, chaque service a sa base → il faut gérer la synchronisation. Par exemple, quand une commande est passée, il faut que le stock soit mis à jour dans un autre service. On utilise des approches comme la consistance éventuelle, les transactions distribuées ou le Saga pattern — mais ça rajoute de la complexité.
Partie 3 : Passage en Serverless
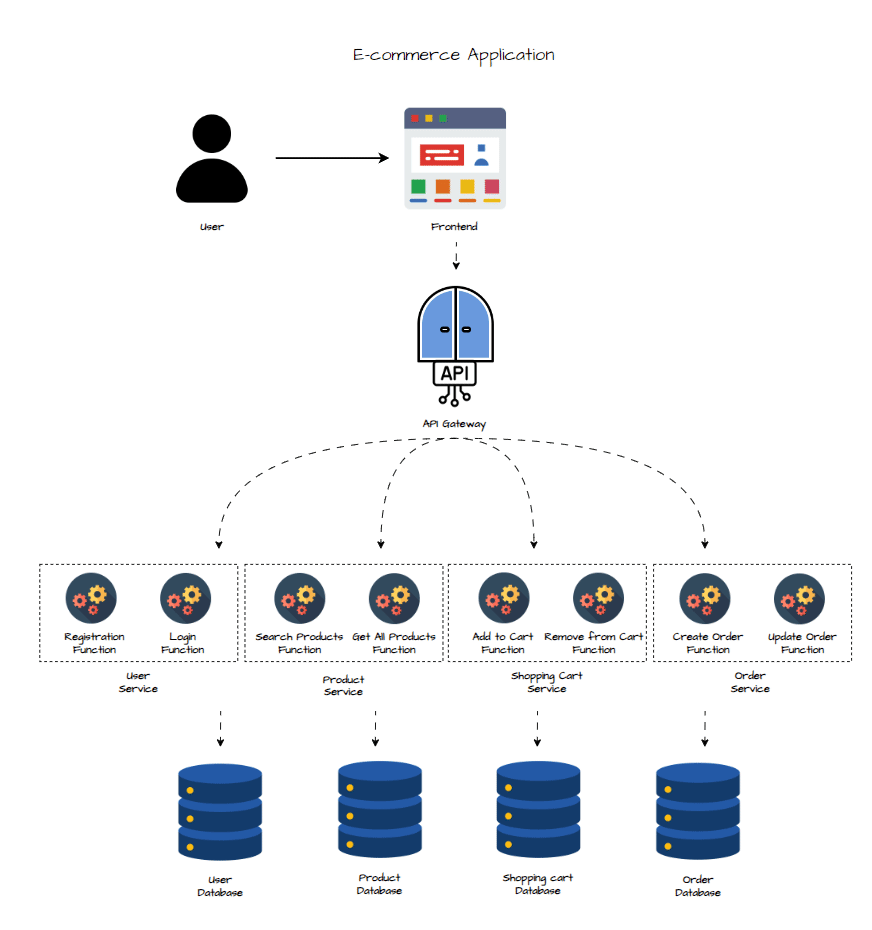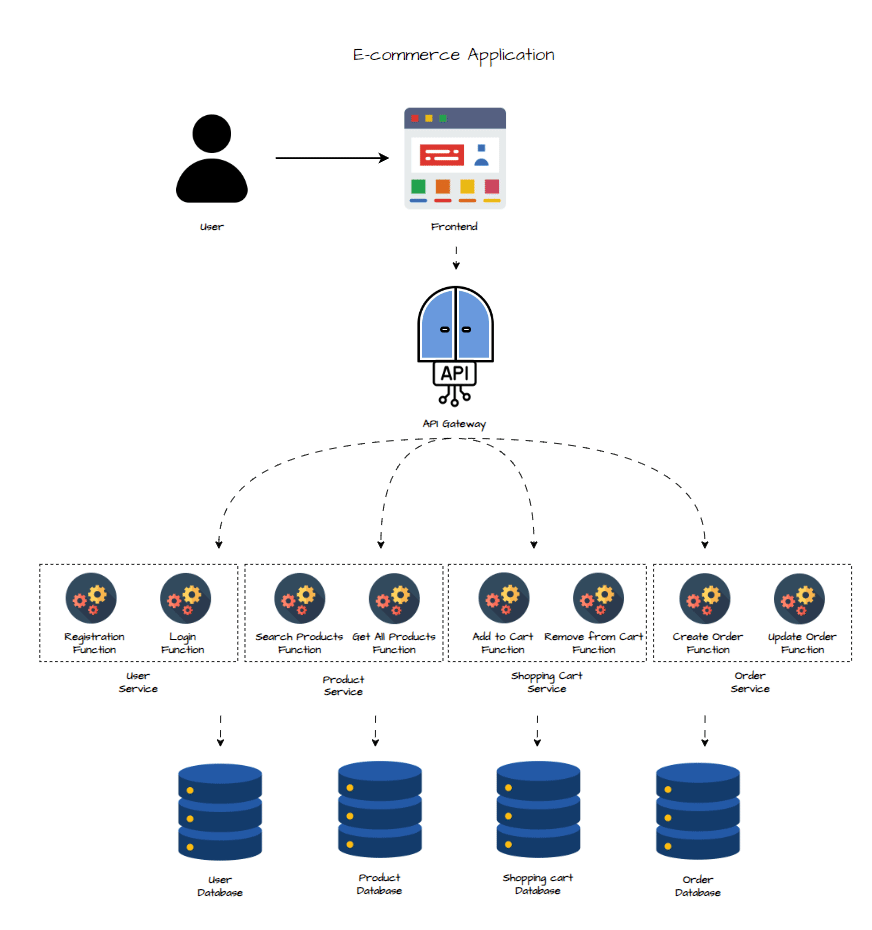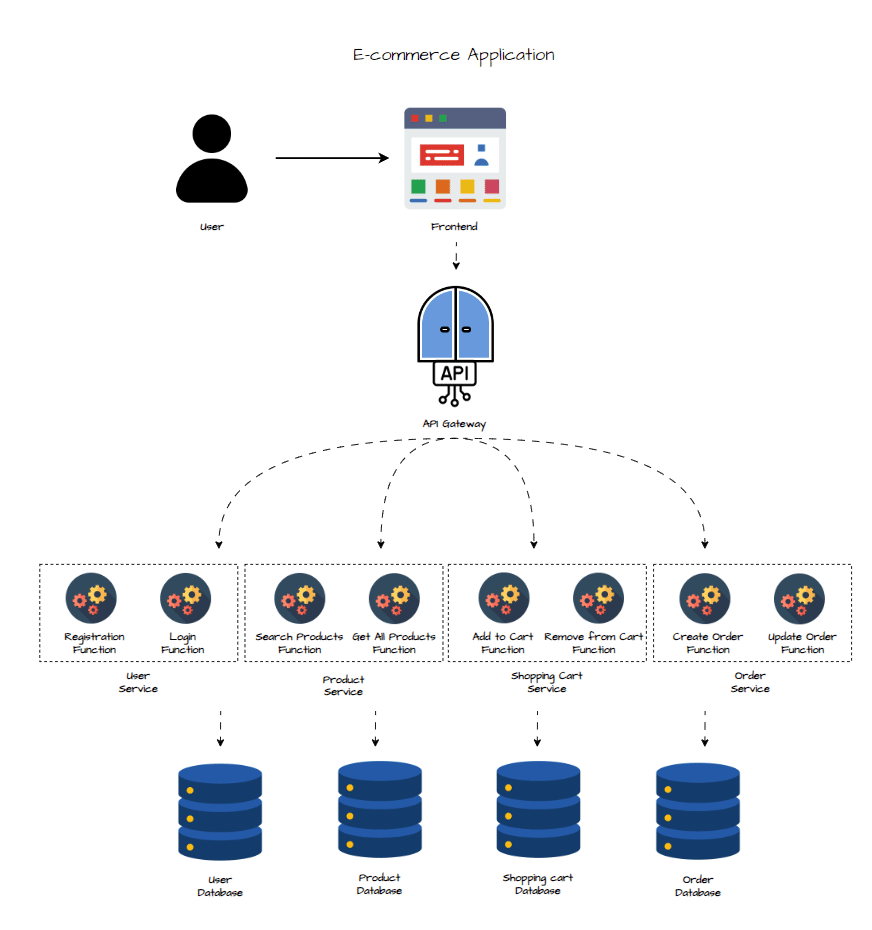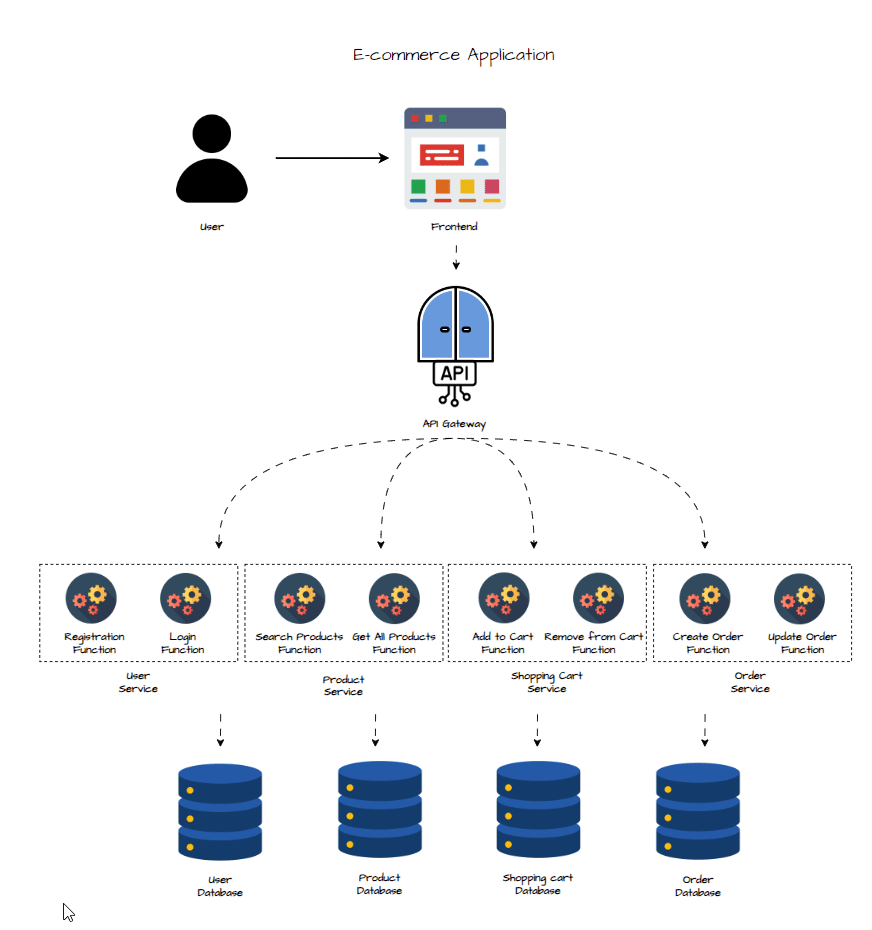
Conception des Fonctions
L’architecture reste globalement similaire à celle en microservices, avec une différence majeure au niveau de la structure du backend. En architecture serverless, le backend est découpé en fonctions unitaires, très ciblées, chacune dédiée à une action précise. Contrairement à une architecture microservices où chaque service regroupe plusieurs fonctionnalités, ici on décompose encore plus : chaque fonction a un seul objectif. Elles sont déclenchées par des requêtes HTTP, en réponse directe aux interactions des utilisateurs avec l’interface.
Dans le schéma plus haut, toutes les fonctions ne sont pas représentées pour simplifier. Voici le détail des fonctions serverless pour chaque service :
1 - Service Utilisateur :
- Registration Function : Gère l’inscription des utilisateurs, enregistre les infos en base.
- Login Function : Authentifie l’utilisateur, génère un token, et gère la session.
- Update User Info Function : Permet à l’utilisateur de modifier ses infos personnelles.
2 - Service Produits :
- Search Products Function : Gère les recherches dans le catalogue selon les filtres de l’utilisateur.
- Get All Products Function : Récupère la liste complète des produits disponibles.
- Add Product Function : Ajoute un nouveau produit au catalogue.
- Remove Product Function : Supprime un produit spécifique du catalogue.
- Delete Product Function : Supprime définitivement un produit de la base.
3 - Service Panier :
- Create Shopping Cart Function : Initialise un nouveau panier pour un utilisateur.
- Add Products to Cart Function : Ajoute des produits au panier.
- Remove Products From Cart Function : Retire certains produits du panier.
- Validate Cart Function : Vérifie le contenu du panier et le stock dispo avant passage en caisse.
4 - Service Commandes :
- Create Order Function : Crée une commande à partir d’un panier validé, et lance le paiement.
- Update Order Function : Met à jour le statut de la commande et gère le suivi.
Interactions entre Fonctions
Les fonctions peuvent s’appeler entre elles pour créer des workflows plus complexes. Par exemple, la Validate Cart Function du service panier peut appeler la Create Order Function pour créer une commande une fois le panier validé.
Cette approche serverless permet d’avoir des composants ultra modulaires et scalables, où chaque fonction remplit une tâche spécifique de manière autonome. Ça donne un contrôle précis et granulaire sur la logique backend de l’application.
Avantages
-
Scalabilité : Les fonctions serverless scalent automatiquement selon la demande. Lorsqu’une requête HTTP déclenche une fonction, le fournisseur cloud alloue dynamiquement les ressources nécessaires pour y répondre. Ça permet une montée en charge fluide, que ce soit pour un seul utilisateur ou des milliers, sans intervention manuelle. Contrairement aux microservices qui scalent un service entier, ici on scale chaque fonction individuellement, ce qui permet d’optimiser encore plus finement l’usage des ressources.
-
Coût : Le modèle pay-as-you-go fait que tu ne paies que pour le temps d’exécution des fonctions. C’est souvent plus économique que les microservices, où les serveurs doivent rester actifs même s’ils sont sous-utilisés.
-
Gestion Opérationnelle : Le serverless abstrait complètement l’infra. Pas besoin de gérer de serveurs, de patcher ou de scaler à la main — c’est le cloud provider qui s’en occupe. Résultat : les devs peuvent se concentrer sur le code des fonctions sans se soucier de la gestion système. Ça permet des itérations plus rapides, donc un meilleur time-to-market.
Comparaison avec les microservices
-
Granularité : Les microservices découpent l’appli par domaines fonctionnels. Le serverless va encore plus loin en divisant chaque domaine en fonctions ultra ciblées, chacune avec un rôle bien précis.
-
Cycle de vie & État : Un microservice tourne en continu et peut garder un état. Une fonction serverless est éphémère et stateless : elle ne s’exécute que lorsqu’un événement se produit (ex : une requête HTTP).
-
Infrastructure : Les microservices impliquent une gestion d’infra (même en conteneur). En serverless, toute cette gestion est déléguée au fournisseur cloud.
Limites & Défis
-
Cold Starts : Lorsqu’une fonction n’a pas été exécutée depuis un moment, le premier appel peut être lent (on appelle ça un “cold start”). C’est gênant pour les cas très sensibles au temps de réponse.
-
Gestion d’état : Comme les fonctions sont stateless, il faut passer par des services externes (base de données, cache…) pour gérer l’état entre les appels. Ce n’est pas toujours simple.
-
Limites d’exécution : Certaines plateformes imposent des limites (ex : AWS Lambda = 15 min max par exécution), donc ce n’est pas adapté aux traitements longs.
-
Orchestration complexe : Plus on a de fonctions, plus la coordination devient délicate. Il faut bien structurer les workflows et gérer les dépendances pour garder un système cohérent et maintenable.
Comment choisir ?
En conclusion, il n’y a pas d’architecture parfaite. Chaque approche a ses forces selon les besoins du projet. L’important, c’est de choisir celle qui correspond vraiment au contexte.
Alors, quand choisir quoi ?
-
Architecture Monolithique → idéale pour des petits projets stables avec peu de charge. Simple à développer et à déployer, mais peu flexible.
-
Architecture Microservices → parfaite pour des projets complexes à grande échelle. Permet de scaler, tester et déployer indépendamment chaque partie. Demande plus d’efforts en orchestration et monitoring.
-
Architecture Serverless → top pour les charges variables ou imprévisibles, et pour les projets petits à moyens. Moins de gestion infra, bon rapport coût/perf. Mais attention : peut devenir complexe (et cher) à grande échelle avec des charges très constantes.