Améliorer mes compétences Cloud - Semaine 8 - DevOps
Je suis relativement nouveau dans le monde DevOps, ayant brièvement travaillé avec Azure DevOps au travail. Cette semaine, j’ai appris comment DevOps transforme le paysage du développement et du déploiement. J’ai eu l’occasion d’utiliser GitHub Actions pour la première fois et de l’intégrer avec IaC et AWS. Ce fut une expérience vraiment amusante !
Comme je l’ai mentionné dans mes articles précédents, je viens d’un background en cloud computing et en ingénierie logicielle, donc tout au long de mon parcours d’apprentissage, je marquerai les nouveaux concepts avec le hashtag #nouveau. Cela permettra de mettre en évidence ce qui est nouveau pour moi et d’offrir aux lecteurs une idée plus claire de l’endroit où ils pourraient trouver une valeur ajoutée, qu’ils revisitent des concepts familiers ou qu’ils rencontrent de nouveaux éléments.
Restez à l’écoute car je continue de documenter mon processus d’apprentissage et de partager des points à retenir pratiques de chaque module !
1 - Un monde avant DevOps
2 - Qu’est-ce que DevOps
3 - CI/CD
4 - Intégration Continue
5 - Livraison et Déploiement Continus
6 - Pipeline CI vs CD
7 - Stratégies de Déploiement
8 - GitHub Actions
9 - Premier Workflow GitHub Actions
10 - Projet | Pipeline CICD pour une fonction Lambda
11 - Projet | Tester un modèle CloudFormation IaC en utilisant GitHub Actions
1 - Un monde avant DevOps
Avant l’avènement de DevOps, les pratiques traditionnelles de développement et d’exploitation des logiciels étaient fortement cloisonnées, ce qui entraînait des processus lents et lourds. Ces silos ont créé des barrières de communication entre les équipes, entraînant des retards de publication, des systèmes défaillants et des clients mécontents.
Équipes cloisonnées
À l’ère pré-DevOps, les équipes de développement, de test (QA) et d’exploitation travaillaient en isolement les unes des autres :
- Les développeurs écrivaient du code pendant des mois, se concentrant uniquement sur l’ajout de nouvelles fonctionnalités.
- Les équipes QA testaient le code pendant des mois, identifiant les bogues et les problèmes potentiels.
- Les opérations étaient chargées de déployer d’importantes versions, souvent surprises par le volume des changements et le nombre de nouvelles fonctionnalités qu’elles devaient gérer.
Ce flux de travail disjoint a entraîné une mauvaise collaboration, des problèmes de communication et des goulets d’étranglement opérationnels.
Processus lents et barrières de communication
Le manque de communication entre les équipes de développement, de QA et d’exploitation a conduit à des cycles de publication inefficaces et lents :
- Les équipes de développement travaillaient en isolement pendant de longues périodes, parfois des mois, avant de remettre leur code à la QA.
- Les tests QA prenaient une autre période importante, car les testeurs devaient traiter des centaines de mises à jour et de fonctionnalités regroupées dans une seule version.
- Les équipes d’exploitation, souvent ignorantes de ce qui arrivait, étaient prises au dépourvu par les déploiements importants, rencontrant des difficultés inattendues lors des déploiements en production.
Cycles de publication inefficaces
Les publications étaient souvent lentes, risquées et sujettes aux échecs. Les caractéristiques courantes du monde pré-DevOps comprenaient :
- Publications peu fréquentes et importantes : Les publications étaient regroupées avec des centaines de changements, souvent programmées à des mois, voire des années d’intervalle.
- Risque élevé d’échec : Chaque publication comportait un risque élevé de casser les systèmes existants, car il était difficile de tester tous les changements en une seule fois.
- Difficultés de retour en arrière : Lorsqu’une publication échouait, revenir à une version stable précédente était souvent difficile et long, entraînant des temps d’arrêt et l’insatisfaction des clients.
Un processus manuel
Le monde pré-DevOps reposait fortement sur des processus manuels, ce qui contribuait à l’inefficacité et aux risques globaux :
- Déploiements manuels : Les équipes devaient suivre des listes de contrôle exhaustives pour chaque déploiement, ce qui prenait du temps et était sujet aux erreurs humaines.
- Environnements incohérents : Les environnements de développement, de test et de production différaient souvent, ce qui entraînait des problèmes difficiles à tracer et à corriger.
- Difficultés de suivi des versions : Sans automatisation, il était difficile de s’assurer que chaque environnement utilisait la bonne version du logiciel, ce qui augmentait encore la probabilité d’échecs.
Les équipes d’exploitation, chargées de maintenir les systèmes en bon état de fonctionnement, étaient souvent placées dans une situation difficile :
- Déploiements bloqués : Les équipes d’exploitation retardaient ou bloquaient carrément les nouveaux déploiements pour éviter le risque d’interruptions ou de pannes du système.
- Culture d’aversion au risque : L’innovation passait au second plan par rapport à la stabilité - la peur de casser les systèmes de production étouffait le rythme de développement de nouvelles fonctionnalités.
- Dépendance aux systèmes hérités : Les organisations s’accrochaient souvent aux systèmes hérités pour éviter les risques associés à la mise à jour vers de nouvelles versions, ce qui, à son tour, ralentissait leur capacité à innover.
Manque de communication
Le manque de collaboration et de communication entre les développeurs, la QA et les opérations a exacerbé les problèmes :
- Développeurs déconnectés de la production : Les développeurs avaient peu de visibilité sur la façon dont leur code fonctionnait dans des environnements réels. Ils se concentraient sur l’ajout de nouvelles fonctionnalités et traitaient rarement de l’impact de leur code en production.
- Opérations prises au dépourvu par les nouvelles fonctionnalités : Les équipes d’exploitation étaient souvent prises au dépourvu par les changements introduits par les nouvelles versions. Sans une compréhension claire de ce qui était déployé, elles avaient du mal à gérer la complexité accrue.
- Clients laissés en attente : Les utilisateurs finaux devaient attendre de longues périodes pour recevoir de nouvelles fonctionnalités ou des corrections de bogues. En raison du manque de communication et de retour d’information entre les équipes, l’insatisfaction des clients augmentait à mesure que les délais de réponse pour résoudre les problèmes augmentaient.
Le besoin d’un changement
La combinaison de processus lents, d’une mauvaise communication et d’efforts manuels a conduit à :
- Cycles de publication lents : Les organisations mettaient souvent des mois ou des années pour publier des mises à jour, avec des centaines de changements regroupés dans chaque déploiement.
- Risque élevé d’échec : La taille et la complexité de chaque publication augmentaient les risques de casse lors du déploiement, ce qui rendait difficile la fourniture de systèmes stables.
- Manque d’innovation : Dans un effort pour éviter les risques, les équipes hésitaient à adopter de nouvelles technologies ou pratiques, ce qui entraînait une stagnation et une incapacité à répondre à l’évolution des demandes des clients.
Sans mécanismes de retour d’information efficaces entre le développement, les opérations et le client :
- Améliorations lentes : Les bogues mettaient beaucoup de temps à être corrigés, et les nouvelles fonctionnalités mettaient encore plus de temps à être déployées.
- Clients mécontents : Les utilisateurs finaux étaient frustrés par les longs délais de résolution des problèmes, ce qui entraînait une mauvaise expérience client.
L’ère pré-DevOps était caractérisée par des processus lents, inefficaces et risqués qui ont conduit à des équipes déconnectées et à des clients frustrés. L’approche traditionnelle, centrée sur les silos et les processus manuels, ne pouvait plus suivre la demande de publications plus rapides et plus fiables.
Cela a ouvert la voie à DevOps, un changement culturel et technologique conçu pour combler le fossé entre les équipes de développement et d’exploitation, permettant des publications plus rapides, plus sûres et plus collaboratives. En introduisant l’automatisation, le retour d’information continu et la collaboration interfonctionnelle, DevOps a transformé la façon dont les organisations livraient des logiciels, rendant les publications plus fréquentes, efficaces et fiables.
2 - Qu’est-ce que DevOps
Définition
DevOps est un ensemble de pratiques qui combine le développement logiciel (Dev) et les opérations informatiques (Ops) dans le but de raccourcir le cycle de vie du développement des systèmes et de fournir des logiciels de haute qualité en continu. DevOps représente un changement culturel qui privilégie la collaboration, l’automatisation et le partage des responsabilités entre les équipes de développement et d’exploitation traditionnellement cloisonnées.
À la base, DevOps consiste à briser les barrières entre le développement et les opérations, en créant un pont qui permet un flux de valeur continu du développement au déploiement. Il est important de noter que si les outils sont essentiels, DevOps concerne avant tout les personnes et les processus. En favorisant la collaboration, l’automatisation et le retour d’information continu, DevOps permet aux équipes de fournir de meilleurs logiciels plus rapidement, de manière plus fiable et plus efficace.
Principes de DevOps
DevOps est guidé par un ensemble de principes fondamentaux qui mettent l’accent sur la livraison continue, l’itération rapide et un état d’esprit axé sur le client.
Collaboration
DevOps encourage la communication ouverte et le partage des responsabilités dans toute l’organisation, des développeurs aux opérations et au-delà. L’objectif est de favoriser une culture où les équipes travaillent ensemble vers des objectifs communs plutôt que de travailler en silos.
Briser les murs entre les équipes améliore la transparence et encourage la compréhension mutuelle des objectifs et des processus.
Automatisation
L’automatisation est un principe clé de DevOps, visant à réduire l’intervention manuelle, minimisant ainsi les erreurs et accélérant les processus. Elle couvre tout, des tests et de l’intégration au déploiement et à la surveillance.
En automatisant les tâches répétitives, les équipes peuvent se concentrer sur un travail à plus forte valeur ajoutée tout en assurant des processus cohérents et reproductibles.
Amélioration continue
DevOps adopte un état d’esprit de croissance où les équipes sont encouragées à apprendre de leurs échecs, à apporter des améliorations progressives et à abandonner la peur du changement.
Les équipes affinent continuellement leurs processus, leurs outils et leurs techniques en fonction des commentaires et des données de performance, ce qui permet des itérations rapides.
Centricité client
Dans une culture DevOps, les clients sont prioritaires. L’objectif est de fournir de la valeur aux utilisateurs finaux efficacement en publiant continuellement de nouvelles fonctionnalités, des mises à jour et des corrections de bogues.
L’accent est mis sur les boucles de rétroaction client pour s’assurer que le logiciel s’améliore et évolue constamment pour répondre aux besoins des utilisateurs.
Mesure
Les équipes DevOps performantes mesurent et surveillent leurs performances en utilisant des mesures et des données pour guider les améliorations.
La prise de décision basée sur les données est une pierre angulaire de DevOps, permettant aux équipes d’évaluer l’impact des changements, de surveiller l’état du système et de s’assurer de l’alignement sur les objectifs commerciaux.
Avantages
L’adoption de DevOps offre de nombreux avantages aux organisations, rendant le développement logiciel plus rapide, plus fiable et plus évolutif.
Délai de commercialisation plus rapide
En adoptant la livraison continue et l’automatisation, les équipes DevOps peuvent réduire considérablement le temps entre l’idée et la production. Les publications fréquentes garantissent que les nouvelles fonctionnalités et les améliorations sont livrées plus rapidement.
Meilleure collaboration
DevOps améliore la communication et la collaboration entre les départements traditionnellement cloisonnés, ce qui conduit à des équipes plus cohésives et à des transferts plus fluides entre le développement, les tests et les opérations.
Fiabilité améliorée
Les pratiques DevOps telles que les tests et l’intégration continus aident les équipes à détecter et à corriger les problèmes dès le début du cycle de développement. Cela conduit à des publications plus stables et à un degré de confiance plus élevé dans les déploiements en production.
Sécurité améliorée
Avec l’intégration de DevSecOps (développement, sécurité et opérations), la sécurité devient partie intégrante du processus de développement dès le début. Cela garantit que les vulnérabilités de sécurité sont traitées plus tôt et plus efficacement.
Évolutivité accrue
Les pratiques DevOps facilitent la gestion et l’adaptation des systèmes complexes. L’automatisation permet aux équipes d’augmenter l’infrastructure et les services à la demande, garantissant que les systèmes peuvent gérer le trafic ou la charge de travail accrus efficacement.
Productivité des développeurs accrue
- En automatisant les tâches répétitives telles que les tests, la construction et le déploiement, CI/CD libère les développeurs pour qu’ils puissent se concentrer sur l’écriture de code plutôt que de passer du temps sur des processus manuels.
Produits de meilleure qualité
Les boucles de rétroaction continues, les tests automatisés et la surveillance constante aident les équipes à s’assurer que le logiciel répond aux attentes des utilisateurs. La nature itérative de DevOps permet aux équipes de réagir rapidement aux changements et de fournir des logiciels de meilleure qualité.
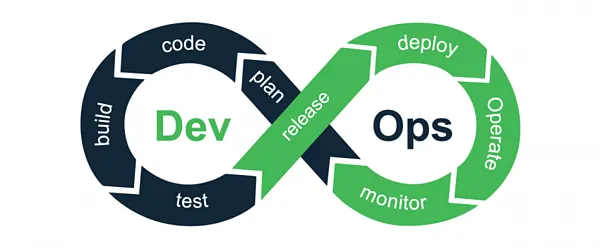
Cycle de vie DevOps
Le cycle de vie DevOps est souvent représenté comme une boucle continue qui reflète les processus de base de développement, d’intégration, de déploiement, d’opérations et de rétroaction. Ce cycle de vie est conçu pour permettre une itération rapide et une amélioration continue.
Étapes clés du cycle de vie DevOps :
-
Planifier : Les équipes collaborent pour définir de nouvelles fonctionnalités, des mises à jour et des améliorations en fonction des besoins de l’entreprise et des commentaires des clients.
-
Coder : Les développeurs écrivent le code pour les nouvelles fonctionnalités ou les corrections de bogues. Le code est stocké dans des systèmes de contrôle de version comme Git.
-
Construire : Les outils de construction automatisés compilent le code en un format déployable (par exemple, des binaires ou des images de conteneur).
-
Tester : Des tests automatisés (unitaires, d’intégration, de régression) sont exécutés pour s’assurer que le code fonctionne comme prévu.
-
Publier : Une fois testé, le code est publié en production via un processus automatisé.
-
Déployer : La nouvelle version de l’application est déployée dans l’environnement de production à l’aide d’outils tels que Jenkins, Kubernetes ou AWS CodeDeploy.
-
Exploiter : Le système est surveillé en production pour s’assurer qu’il fonctionne correctement. Les équipes gèrent également la mise à l’échelle, le dépannage et l’optimisation des performances au cours de cette phase.
-
Surveiller : La surveillance et les boucles de rétroaction sont essentielles pour identifier les problèmes en temps réel, assurer la santé du système et capturer des informations pour une amélioration continue.
-
Commentaires et amélioration continue : Les commentaires des clients et les données de performance du système sont analysés, ce qui permet d’améliorer et de mettre à jour le logiciel à l’avenir.
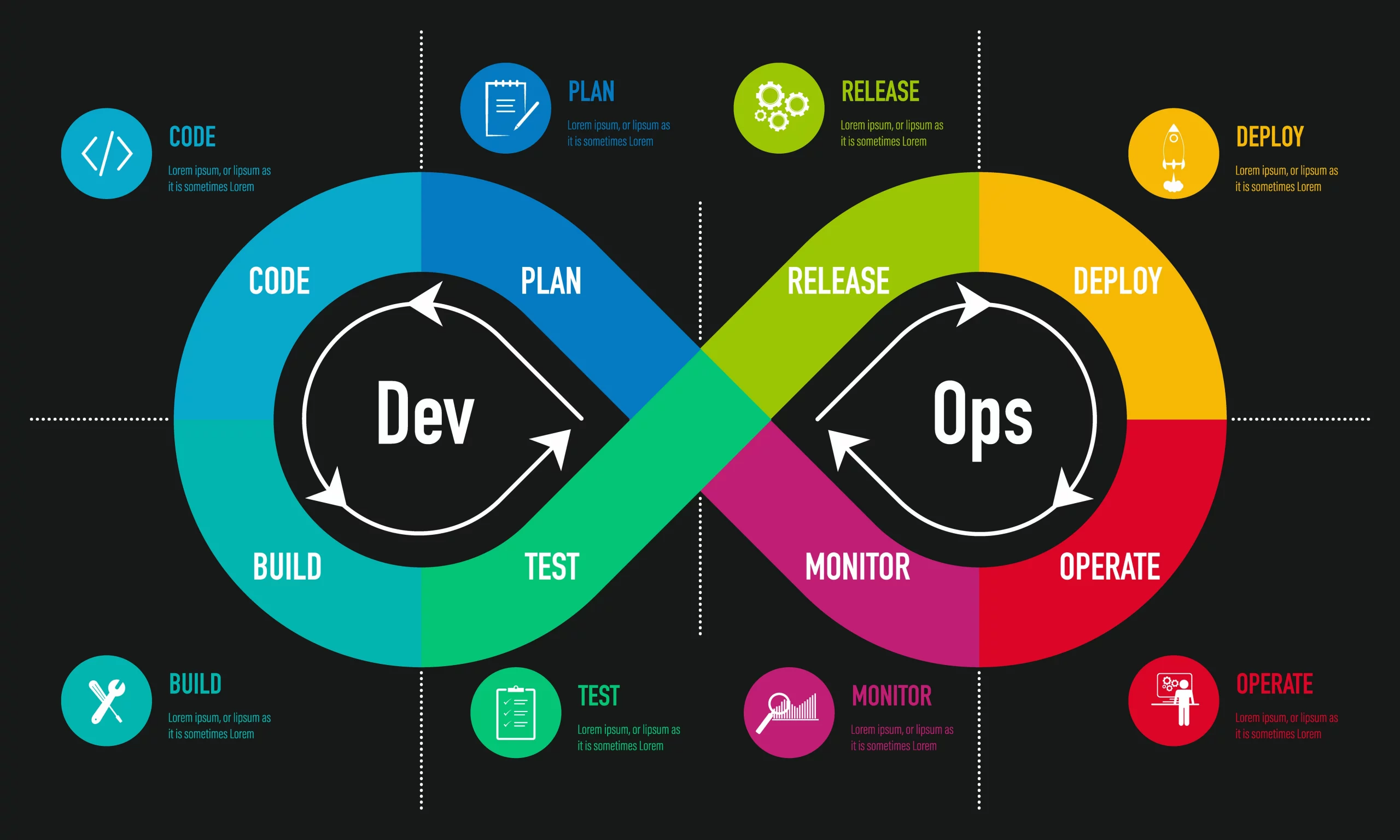
3 - CI/CD
Intégration continue (CI)
L’intégration continue (CI) est la pratique consistant à automatiser l’intégration des modifications de code de plusieurs développeurs dans un référentiel partagé plusieurs fois par jour. Chaque modification est automatiquement testée pour s’assurer qu’elle ne casse pas le logiciel. CI aide à identifier les bogues tôt et à s’assurer que la base de code est toujours dans un état déployable.
- Principaux avantages de CI :
- Détection précoce des bogues : En fusionnant le code fréquemment, les équipes peuvent détecter et corriger les bogues tôt, réduisant ainsi le risque de trouver des problèmes tard dans le processus.
- Retour d’information plus rapide : Les développeurs reçoivent rapidement des commentaires des tests automatisés, ce qui leur permet de corriger les problèmes alors qu’ils sont encore frais.
Livraison continue (CD)
La livraison continue (CD) est l’étape suivante après CI, où le code est automatiquement préparé pour la publication dans des environnements de pré-production. CD garantit que l’application est toujours dans un état déployable et que de nouvelles fonctionnalités ou corrections de bogues peuvent être publiées à tout moment avec une intervention manuelle minimale.
- Principaux avantages de CD :
- Cycles de publication plus rapides : La possibilité de déployer du code rapidement et facilement réduit le temps entre le développement et la livraison à l’utilisateur final.
- Risque plus faible : Étant donné que les déploiements sont plus fréquents et de plus petite envergure, il y a moins de risques de pannes majeures du système.
Déploiement continu
Le déploiement continu va encore plus loin que la livraison continue en déployant automatiquement chaque modification qui réussit tous les tests directement en production. Il élimine le besoin d’approbation manuelle dans le processus de déploiement.
- Principaux avantages du déploiement continu :
- Livraison rapide des fonctionnalités : Les nouvelles fonctionnalités et les correctifs sont déployés en production dès qu’ils sont prêts.
- Réduction du travail manuel : Les déploiements entièrement automatisés réduisent le besoin d’intervention humaine, ce qui permet aux équipes de se concentrer sur le développement et l’innovation.
Étapes
Un pipeline CI/CD typique comprend une série d’étapes automatisées qui font passer le code du développement à la production. Ces étapes garantissent que le code est continuellement intégré, testé et déployé.
1. Code
- Les développeurs écrivent et valident le code dans un système de contrôle de version (par exemple, Git). Le pipeline CI/CD est déclenché chaque fois que du code est poussé vers le référentiel.
2. Construire
- Le code est automatiquement compilé et construit en artefacts exécutables (par exemple, des binaires ou des images Docker). Le processus de construction vérifie également tout problème, tel que des dépendances manquantes ou des configurations rompues.
3. Tester
- Des tests unitaires automatisés, des tests d’intégration et des tests fonctionnels sont exécutés pour s’assurer que le code se comporte comme prévu. Si des tests échouent, le pipeline s’arrête et le développeur est averti pour corriger les problèmes avant de continuer.
4. Déployer en pré-production
- Une fois que le code a réussi tous les tests, il est déployé dans un environnement de pré-production. Cet environnement imite l’environnement de production et permet aux équipes d’effectuer des tests supplémentaires, tels que des tests de performance ou des tests de sécurité.
5. Tests d’acceptation
- Dans l’environnement de pré-production, des tests d’acceptation utilisateur (UAT) sont effectués. Cette étape garantit que le logiciel répond aux exigences de l’entreprise et fonctionne comme prévu pour l’utilisateur final.
6. Déployer en production
- Après des tests d’acceptation réussis, le code est déployé dans l’environnement de production. Si le pipeline suit le modèle de déploiement continu, ce déploiement est entièrement automatisé et aucune intervention manuelle n’est requise.
4 - Intégration Continue
Concepts clés de l’intégration continue
L’intégration continue (CI) est une pratique de développement logiciel où les développeurs intègrent fréquemment leur code dans un référentiel partagé. Ce processus est automatisé et suivi de constructions et de tests pour détecter les problèmes d’intégration tôt et maintenir la qualité du code.
Intégration fréquente du code
- Les développeurs valident fréquemment leurs modifications de code dans un référentiel de contrôle de version partagé (par exemple, Git). L’intégration plus fréquente du code réduit le nombre de problèmes d’intégration et permet une détection précoce des bogues.
Constructions et tests automatisés
- Les pipelines CI construisent automatiquement le code et exécutent des tests automatisés chaque fois qu’une modification est poussée vers le référentiel. Cela garantit que les problèmes sont détectés tôt et que le code est toujours dans un état déployable.
Contrôle de version
- CI s’appuie fortement sur les systèmes de contrôle de version (VCS) comme Git pour suivre les modifications de code et assurer une collaboration appropriée entre les membres de l’équipe. Le contrôle de version permet aux équipes de travailler sur différentes branches, de tester les fonctionnalités indépendamment et d’intégrer ces modifications dans la branche principale.
Tests automatisés
Les tests automatisés sont un aspect clé de CI, permettant aux équipes d’assurer la qualité et la fonctionnalité du code avec une intervention manuelle minimale. Bien qu’aucune application ne soit jamais vraiment exempte de bogues, les tests automatisés aident à détecter et à corriger autant de problèmes que possible avant que l’utilisateur ne les rencontre.
Tests unitaires
- Les tests unitaires vérifient les composants ou fonctions individuels du code en isolement. Ils sont généralement rapides et nombreux et constituent la première ligne de défense contre les bogues.
- Objectif : S’assurer que chaque partie individuelle du code fonctionne comme prévu.
Tests d’intégration
- Les tests d’intégration vérifient comment différents composants ou services interagissent les uns avec les autres. Ces tests garantissent que les dépendances et les interactions entre les modules fonctionnent correctement.
- Objectif : Vérifier que les composants fonctionnent bien ensemble dans un système intégré.
Tests de bout en bout (E2E)
- Les tests de bout en bout simulent les interactions réelles des utilisateurs et testent l’ensemble du flux de l’application, du début à la fin. Les tests E2E sont plus complets mais aussi les plus lents à exécuter. Ceux-ci sont généralement réservés aux tests sur la branche principale ou aux versions majeures.
- Objectif : S’assurer que l’ensemble de l’application, du frontend au backend, se comporte comme prévu pour les utilisateurs finaux.
Outils CI populaires
Le choix dépend de :
- l’infrastructure existante
- les préférences de l’équipe
- les besoins spécifiques du projet
Voici quelques-uns des outils CI les plus populaires, chacun ayant ses propres forces :
Jenkins
- Jenkins est un serveur d’automatisation open-source connu pour son vaste écosystème de plugins. Il est hautement personnalisable, ce qui en fait un choix populaire pour les entreprises qui ont besoin d’adapter l’outil à leurs besoins spécifiques.
- Points forts : Flexibilité, grande communauté, prise en charge étendue des plugins.
GitLab CI
- GitLab CI est une solution CI/CD intégrée à GitLab. Il offre une prise en charge intégrée de Docker et une intégration transparente avec les dépôts GitLab, permettant une automatisation fluide des builds et des tests.
- Points forts : Intégration GitLab, prise en charge intégrée de Docker, configuration simple.
GitHub Actions
- GitHub Actions est la solution CI/CD native de GitHub. Elle est étroitement intégrée aux dépôts GitHub, offrant un moyen simple d’automatiser les workflows et de configurer les pipelines directement à partir de la plateforme GitHub.
- Points forts : Intégration native avec GitHub, automatisation facile des workflows, interface conviviale.
Architecture d’un Pipeline CI
Un pipeline CI est une série d’étapes automatisées qui aident à garantir la qualité du code et une intégration transparente dans la base de code principale. Ces pipelines garantissent que les modifications sont correctement intégrées, testées et signalées avant de passer en production ou dans d’autres environnements.
1. Contrôle de source
- La première étape du pipeline consiste à intégrer les outils CI dans le système de contrôle de source (par exemple, Git). Cela permet à l’outil CI de détecter automatiquement les modifications dans la base de code lorsque les développeurs envoient du code vers le dépôt.
2. Build
- L’étape suivante consiste à compiler le code, à résoudre les dépendances et à créer des artefacts (par exemple, des binaires, des conteneurs) nécessaires au déploiement. Le processus de build est entièrement automatisé et garantit que le code est dans un état déployable.
3. Test
- Après l’étape de build, le pipeline déclenche automatiquement l’étape de test. Des tests unitaires, des tests d’intégration et d’autres tests automatisés sont exécutés pour s’assurer que le code se comporte comme prévu. Si des tests échouent, le pipeline s’arrête et notifie les développeurs.
4. Rapport
- Une fois les tests terminés, le pipeline génère un rapport. L’état des étapes de build et de test est partagé avec l’équipe, garantissant que les bonnes personnes sont notifiées (par e-mail, Slack ou d’autres canaux) du succès ou de l’échec du pipeline.
5 - Livraison et Déploiement Continus
La Livraison Continue (CD) et le Déploiement Continu (CD) sont des pratiques clés au sein de DevOps qui garantissent que les logiciels sont toujours dans un état déployable et peuvent être mis en production de manière fiable et rapide.
Livraison Continue
La Livraison Continue garantit que l’application est toujours dans un état déployable, ce qui signifie que chaque modification de code passe par une série de tests automatisés et est prête à être mise en production à tout moment. Cependant, dans ce modèle, le déploiement en production nécessite une approbation manuelle. Cela fournit une couche de contrôle supplémentaire, permettant aux équipes de décider quand la version est effectuée.
- Aspect clé : Chaque modification est testée et intégrée, mais attend une intervention manuelle avant d’être déployée en production.
Déploiement Continu
Le Déploiement Continu va plus loin dans l’automatisation en déployant automatiquement chaque modification qui passe par toutes les étapes du pipeline en production sans approbation manuelle. Cette pratique garantit que les nouvelles fonctionnalités, les mises à jour et les corrections de bogues sont livrées aux utilisateurs finaux dès qu’elles sont prêtes.
- Aspect clé : Les modifications sont automatiquement poussées en production sans aucune approbation manuelle, garantissant un flux constant et rapide de mises à jour.
Concepts clés de la livraison et du déploiement continus
La Livraison Continue et le Déploiement Continu visent à améliorer la livraison de logiciels grâce à l’automatisation, la fiabilité et la vitesse. Voici les concepts de base :
Automatisation du processus de publication
- L’ensemble du pipeline, de l’intégration du code aux tests et au déploiement, est automatisé. Cela réduit les risques d’erreurs humaines et augmente la vitesse de livraison des logiciels.
- La Livraison Continue automatise le processus jusqu’à l’étape de production, mais nécessite une approbation manuelle pour la version finale.
- Le Déploiement Continu automatise l’ensemble du processus, des modifications de code au déploiement en production.
2. Pipeline de déploiement
- Un pipeline de déploiement est l’ensemble des processus automatisés qui prennent le code du développement en passant par les tests et jusqu’à la production. Chaque modification du code est automatiquement testée, validée et, selon le modèle, déployée en production.
- Le pipeline garantit que seules les modifications qui réussissent tous les tests et validations sont mises en production, ce qui augmente la fiabilité des versions.
3. Environnements de type production
- La Livraison Continue et le Déploiement Continu nécessitent un environnement de staging ou de type production où les modifications de code peuvent être testées avant le déploiement. Cela garantit que le code est testé dans des conditions réelles, ce qui réduit le risque de bogues ou de problèmes en production.
4. Surveillance et rétroaction continues
- Une fois le code en production, il est essentiel de surveiller en permanence le système pour détecter tout problème. Des outils de surveillance automatisés sont utilisés pour détecter les goulots d’étranglement de performance, les bogues ou les défaillances.
- La boucle de rétroaction est cruciale, car elle fournit des données qui peuvent être utilisées pour améliorer le logiciel et le pipeline lui-même.
Livraison Continue vs. Déploiement Continu
| Principales différences | Livraison Continue | Déploiement Continu |
|---|---|---|
| Définition | Garantit que le code est toujours dans un état déployable, mais nécessite une approbation manuelle pour les versions en production. | Déploie automatiquement chaque modification qui passe le pipeline en production. |
| Approbation manuelle | Oui, une approbation manuelle est requise avant le déploiement en production. | Non, entièrement automatisé. Les modifications sont déployées directement en production. |
| Fréquence de déploiement | Fréquente, mais pas nécessairement après chaque modification de code. | Peut se produire plusieurs fois par jour, après chaque build réussi. |
| Cas d’utilisation | Équipes qui souhaitent contrôler les versions en production, mais qui automatisent toujours les phases de test et d’intégration. | Équipes qui souhaitent automatiser l’ensemble du pipeline et livrer les modifications dès qu’elles sont prêtes. |
| Risque | Risque plus faible, car les modifications peuvent être examinées manuellement avant la production. | Risque légèrement plus élevé, mais atténué par des versions fréquentes et petites et des tests approfondis. |
6 - Pipeline CI VS CD
CD étend CI pour automatiser l’ensemble du processus de publication des logiciels.
Étape => Déployer dans un environnement qui imite de près celui de la production. Examen => Approbation manuelle
https://blog.openreplay.com/what-is-a-ci-cd-pipeline/
7 - Stratégies de déploiement
Les stratégies de déploiement déterminent comment les nouvelles modifications de code sont publiées dans un environnement de production en direct. Le choix de la bonne stratégie dépend de plusieurs facteurs, notamment :
- La nature de l’application : Quelle est l’importance du temps de fonctionnement et quelle est la sensibilité de l’application aux mises à jour ?
- La tolérance au risque du client : Quelle perturbation la base d’utilisateurs peut-elle tolérer pendant le déploiement ?
- L’architecture de l’infrastructure : L’infrastructure prend-elle en charge plusieurs environnements et peut-elle gérer des mises à jour progressives ?
Chaque stratégie a ses forces et ses compromis, ce qui rend important de choisir la bonne pour votre cas d’utilisation spécifique.
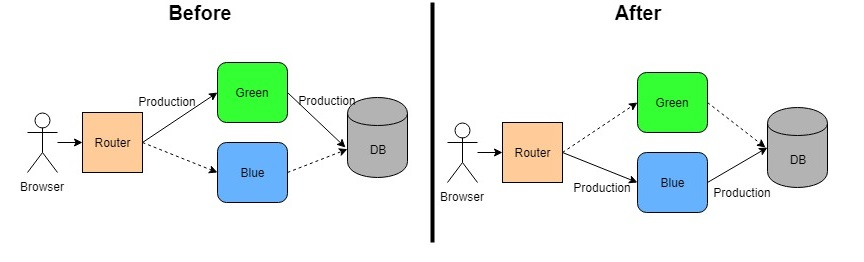
Déploiement Bleu-Vert
 https://dzone.com/articles/blue-green-deployment-for-cloud-native-application
https://dzone.com/articles/blue-green-deployment-for-cloud-native-application
Définition
Basculer entre deux environnements identiques. L'un sert le trafic tandis que l'autre est mis à jour.Le déploiement Bleu-Vert implique de basculer entre deux environnements identiques, bleu et vert, pour le trafic de production. À tout moment, un environnement sert le trafic en direct tandis que l’autre est mis à jour. Une fois que le nouvel environnement est testé et confirmé comme étant stable, le routeur bascule le trafic vers celui-ci.
- L’environnement Bleu sert le trafic de production.
- L’environnement Vert est celui où les mises à jour sont appliquées et testées.
Une fois que l’environnement vert est entièrement préparé et testé, le routeur bascule tout le trafic vers l’environnement vert, ce qui en fait le nouvel environnement en direct. Si des problèmes sont détectés après le basculement, le routeur peut être ramené à l’environnement bleu pour une restauration immédiate.
Avantages
- Zéro temps d’arrêt pendant le déploiement : Étant donné que les deux environnements sont en direct, le basculement du trafic se produit instantanément sans aucune interruption de service.
- Restauration facile : Si des problèmes sont détectés dans le nouvel environnement, vous pouvez revenir à l’environnement d’origine presque immédiatement, minimisant ainsi les temps d’arrêt et les risques.
Inconvénients
- Gourmand en ressources : Nécessite le double de l’infrastructure car vous devez maintenir deux environnements de type production, ce qui augmente les coûts et l’utilisation des ressources.
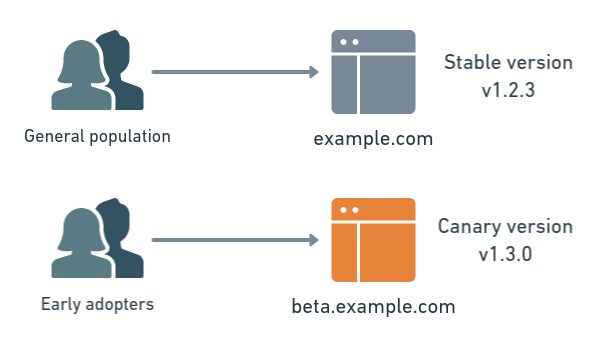
Déploiement Canary
 https://semaphoreci.com/blog/what-is-canary-deployment
https://semaphoreci.com/blog/what-is-canary-deployment
Définition
Publier vers un petit sous-ensemble de serveurs ou d'utilisateurs, puis augmenter progressivementLe déploiement Canary publie de nouvelles modifications vers un petit sous-ensemble d’utilisateurs ou de serveurs en premier. L’idée est d’introduire progressivement la mise à jour. Si tout fonctionne comme prévu, la nouvelle version est progressivement déployée vers plus d’utilisateurs ou de serveurs jusqu’à ce que l’ensemble de la base d’utilisateurs utilise la nouvelle version.
- Initialement, seulement 10 % des utilisateurs ou des serveurs pourraient recevoir la nouvelle version.
- Si aucun problème n’est détecté, davantage de serveurs ou d’utilisateurs sont mis à jour jusqu’à ce que le déploiement à 100 % soit atteint.
Si des problèmes sont détectés au cours de ce déploiement progressif, le déploiement peut être arrêté et la version précédente peut être restaurée, empêchant ainsi le problème d’affecter l’ensemble de la base d’utilisateurs.
Avantages
- Atténuation des risques : Étant donné que seule une petite partie de la base d’utilisateurs ou des serveurs reçoit la mise à jour initialement, cela permet une détection précoce des problèmes avant qu’ils n’affectent tout le monde.
- Rétroaction contrôlée : Cette publication progressive fournit une rétroaction utile de la part des utilisateurs réels sans exposer l’ensemble de l’application à des bogues ou des défaillances potentiels.
Inconvénients
- Déploiement plus lent : La nature incrémentielle des déploiements Canary peut rendre le processus de déploiement global plus lent par rapport aux déploiements Bleu-Vert ou Directs.
- Gestion complexe du trafic : Il peut être difficile de gérer le trafic et d’attribuer dynamiquement différents pourcentages d’utilisateurs ou de serveurs pendant les scénarios de déploiement et de restauration.
Déploiement direct en production

Définition
Déployer les modifications directement en production après avoir réussi tous les tests.Dans le déploiement direct en production, les modifications de code sont déployées directement dans l’environnement de production en direct une fois qu’elles ont réussi tous les tests. Il s’agit d’une approche simple où les modifications sont instantanément appliquées au système de production sans déploiement préalable dans un environnement de staging.
Cette stratégie est souvent utilisée dans les applications plus simples ou lorsque les ressources sont limitées, ce qui en fait la méthode la plus rapide et la plus économe en ressources.
Avantages
- Déploiement le plus rapide : Pas besoin d’environnements supplémentaires ou de gestion complexe du trafic, ce qui en fait le moyen le plus rapide de mettre le nouveau code en production.
- Coûts d’infrastructure inférieurs : Puisqu’il n’y a pas d’environnements parallèles à maintenir, cette méthode nécessite moins de ressources.
Inconvénients
- Risque élevé : Étant donné que les modifications sont mises en ligne immédiatement, tout problème dans le nouveau code peut entraîner des perturbations importantes en production. Il n’y a pas non plus de restauration facile sans temps d’arrêt.
- Pas de filet de sécurité : En cas d’échec, il n’y a pas d’environnement de sauvegarde vers lequel basculer, ce qui rend la récupération plus difficile.
Conclusion
Différentes stratégies conviennent à différents types d’applications, d’infrastructures et de besoins commerciaux. En pratique, de nombreuses entreprises utilisent une combinaison de ces stratégies en fonction de l’échelle et de l’impact de la version.
- Le déploiement Bleu-Vert est idéal pour les versions majeures qui nécessitent un temps d’arrêt nul et un risque minimal de restauration. Il est souvent utilisé pour les systèmes critiques où le temps de fonctionnement est primordial.
- Le déploiement Canary est préférable lorsque vous souhaitez valider le nouveau code avec de vrais utilisateurs et surveiller de près la façon dont il interagit avec l’application. Ceci est généralement utilisé dans les systèmes où l’expérience utilisateur est cruciale et où tout impact doit être minime.
- Le déploiement direct en production est le meilleur pour les petites équipes ou les startups disposant de ressources limitées ou pour les applications qui sont peu risquées et faciles à restaurer en cas de problèmes. C’est rapide, simple et rentable.
| Stratégie | Cas d’utilisation | Avantages | Inconvénients |
|---|---|---|---|
| Bleu-Vert | Versions majeures, systèmes critiques | Zéro temps d’arrêt, restauration facile | Nécessite le double de l’infrastructure, coût des ressources plus élevé |
| Canary | Publication progressive, validation de la rétroaction des utilisateurs | Atténuation des risques, détection précoce des problèmes | Processus plus lent, gestion complexe du trafic |
| Production directe | Petits projets, modifications à faible risque | Rapide, rentable | Risque élevé, pas de restauration facile |
En adaptant la stratégie de déploiement aux besoins spécifiques de votre système et de votre application, les équipes peuvent minimiser les risques tout en garantissant des versions de logiciels rapides et fiables.
8 - GitHub Actions
GitHub Actions est une plateforme d’automatisation qui vous permet d’automatiser l’ensemble de votre flux de travail de développement logiciel directement à partir de vos dépôts GitHub. Il va au-delà d’un simple outil CI/CD, offrant une gamme complète de capacités d’automatisation pour gérer les différentes phases du cycle de vie du développement.
GitHub Actions s’intègre de manière transparente à l’ensemble du processus de développement, vous permettant d’automatiser tout, de la planification et du codage au déploiement et à la surveillance.
Flux de travail logiciel
Planifier
- GitHub Actions peut s’intégrer à des outils tels que Trello ou Jira pour automatiser la gestion des tâches. Il peut créer automatiquement des tâches, mettre à jour les tableaux de projet ou déclencher des notifications en fonction des événements du dépôt, tels que la création de problèmes ou les fusions de demandes d’extraction.
Code
- Automatisez les revues de code à l’aide d’actions prédéfinies pour l’analyse du code et le linting.
- GitHub Actions peut formater automatiquement le code lors de la validation, garantissant ainsi la cohérence et la qualité du code dès le départ.
- Il exécute des linters pour détecter les erreurs potentielles et améliorer la qualité globale de la base de code avant même qu’elle ne soit construite.
Construire
- GitHub Actions compile automatiquement le code, exécute des tests unitaires et crée des artefacts de build. Cela garantit que la base de code est toujours dans un état constructible et que les builds cassés sont détectés rapidement.
- Il prend en charge la construction de projets dans divers langages et frameworks, ce qui permet des configurations flexibles.
Tester
- Automatisez les tests à chaque push ou demande d’extraction, en vous assurant que chaque modification est minutieusement testée avant d’être fusionnée dans la base de code principale. Cela inclut l’exécution de tests unitaires, de tests d’intégration et de tests de bout en bout.
Déployer
- GitHub Actions gère les déploiements automatisés vers différents environnements, ce qui rend le processus cohérent et reproductible. Qu’il s’agisse d’un déploiement vers AWS, Azure, Google Cloud ou des environnements auto-hébergés, GitHub Actions simplifie le processus de publication.
Exploiter
- Aide à gérer l’infrastructure en s’intégrant à des outils tels que Terraform ou Ansible. Il garantit que votre Infrastructure as Code (IaC) est toujours à jour, en maintenant la cohérence entre les environnements.
Surveiller
- GitHub Actions s’intègre à des outils de surveillance pour déclencher des réponses automatisées aux incidents. Il peut créer des problèmes pour les instances signalées, répondre automatiquement aux alertes ou même restaurer les déploiements si nécessaire.
Principales fonctionnalités
CI/CD intégré
GitHub Actions vous permet de créer des pipelines CI/CD complexes directement dans votre dépôt. Vous pouvez automatiser l’ensemble du cycle de vie du développement, de l’intégration du code aux tests et au déploiement, le tout au même endroit.
Automatisation des flux de travail
Automatisez les flux de travail en réponse à des événements spécifiques du dépôt, tels que les demandes d’extraction, les poussées ou la création de problèmes. Ce niveau d’automatisation améliore la productivité en réduisant les tâches manuelles.
Prise en charge multi-environnement
GitHub Actions prend en charge l’exécution de flux de travail sur différents systèmes d’exploitation (Linux, macOS, Windows) et différentes versions de logiciels, ce qui permet des tests complets dans plusieurs environnements.
Actions réutilisables
Utilisez des actions prédéfinies de la GitHub Marketplace ou créez vos propres actions personnalisées pour améliorer l’efficacité du flux de travail. Ces actions réutilisables aident à accélérer le développement en automatisant les tâches répétitives.
Gestion sécurisée des secrets
Stockez et utilisez en toute sécurité des informations sensibles telles que les clés API, les mots de passe et les jetons dans les flux de travail sans les exposer. Les secrets sont chiffrés et ne sont mis à la disposition que des flux de travail qui en ont besoin.
Composants du flux de travail
Les flux de travail GitHub Actions se composent de plusieurs composants clés qui déterminent comment et quand l’automatisation est déclenchée.
Événements
Quand ce flux de travail doit-il s'exécuter ?Les événements sont des déclencheurs qui définissent quand un flux de travail doit s’exécuter. Par exemple, vous pouvez configurer un flux de travail pour qu’il se déclenche :
- Lorsqu’un commit est poussé vers une branche spécifique.
- Lorsqu’une demande d’extraction est ouverte ou fusionnée.
- Sur une base planifiée, comme des builds nocturnes.
Tâches
Les tâches sont un ensemble d’étapes qui s’exécutent sur le même exécuteur. Une tâche représente une unité de travail au sein d’un flux de travail.
- Par exemple, vous pouvez avoir des tâches distinctes pour construire, tester et déployer une application.
- Les tâches peuvent être exécutées séquentiellement ou en parallèle en fonction des dépendances entre elles.
Exécuteurs
Les exécuteurs sont les environnements d’exécution où les tâches s’exécutent. Ils fournissent les ressources informatiques nécessaires (CPU, mémoire, etc.) pour exécuter les flux de travail.
- GitHub propose des exécuteurs auto-hébergés ou des exécuteurs hébergés par GitHub (basés sur le cloud).
- Vous pouvez choisir d’exécuter des flux de travail sur des plateformes spécifiques (Linux, macOS ou Windows).
Étapes
Les étapes sont les tâches individuelles qui s’exécutent dans une tâche. Elles sont exécutées dans un ordre spécifié, et les étapes peuvent partager des données et des artefacts entre elles.
- Des exemples incluent l’extraction du code, la configuration des environnements, l’exécution de commandes et l’enregistrement des artefacts.
- Chaque étape peut utiliser une action ou exécuter une commande shell directement.
Actions
Les actions sont des unités de code réutilisables conçues pour effectuer des tâches spécifiques. Elles agissent comme les éléments constitutifs des flux de travail GitHub et peuvent être créées par n’importe qui ou obtenues sur la GitHub Marketplace.
- Des exemples d’actions incluent l’exécution de tests, le déploiement de code ou l’envoi de notifications.
9 - Exemple de flux de travail GitHub Actions
Le flux de travail doit être défini dans un dépôt GitHub à l’intérieur de .github/workflows/main.yaml
name: My GitHub Actions Workflow
on: [push]
jobs:
testing_github:
runs-on: ubuntu-latest
steps:
- name: Hello
run: echo "Hello, world!"
- name: Display repo name
run: echo "This repo is $GITHUB_REPOSITORY"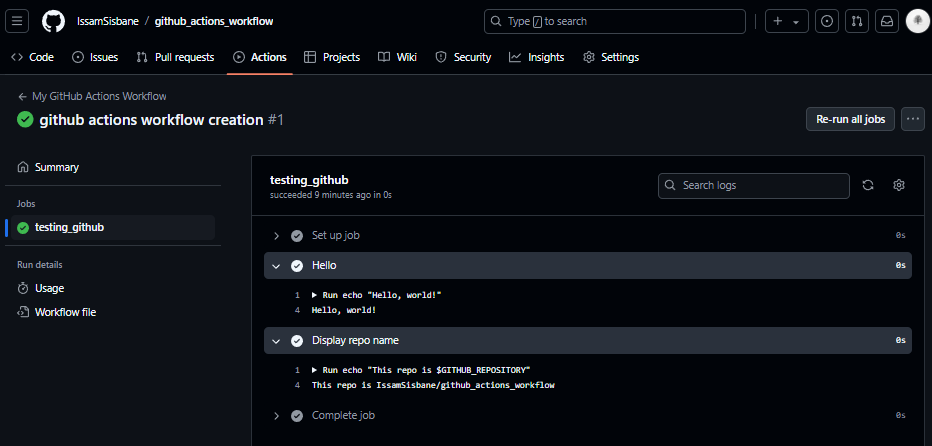
Il s’agit d’un flux de travail très simple, exécutant une commande echo dans le cli de l’exécuteur.
10 - Projet | Pipeline CI/CD pour une fonction Lambda
1 - Aperçu
L’objectif de ce projet est de mettre à jour une fonction Lambda existante lorsque du code est poussé dans un référentiel. Des secrets seront utilisés pour authentifier les actions GitHub auprès d’AWS afin de déployer notre fonction lambda.
Runner :
- Extrait le code du référentiel
- Configure l’environnement python et installe les dépendances
- Configure les identifiants AWS
- Empaquète notre lambda
- Déploie la lambda sur AWS
Nous allons créer la lambda depuis la console AWS pour gagner du temps.
2 - Étapes
1 - Créer un nouveau référentiel GitHub
En utilisant le site web GitHub.
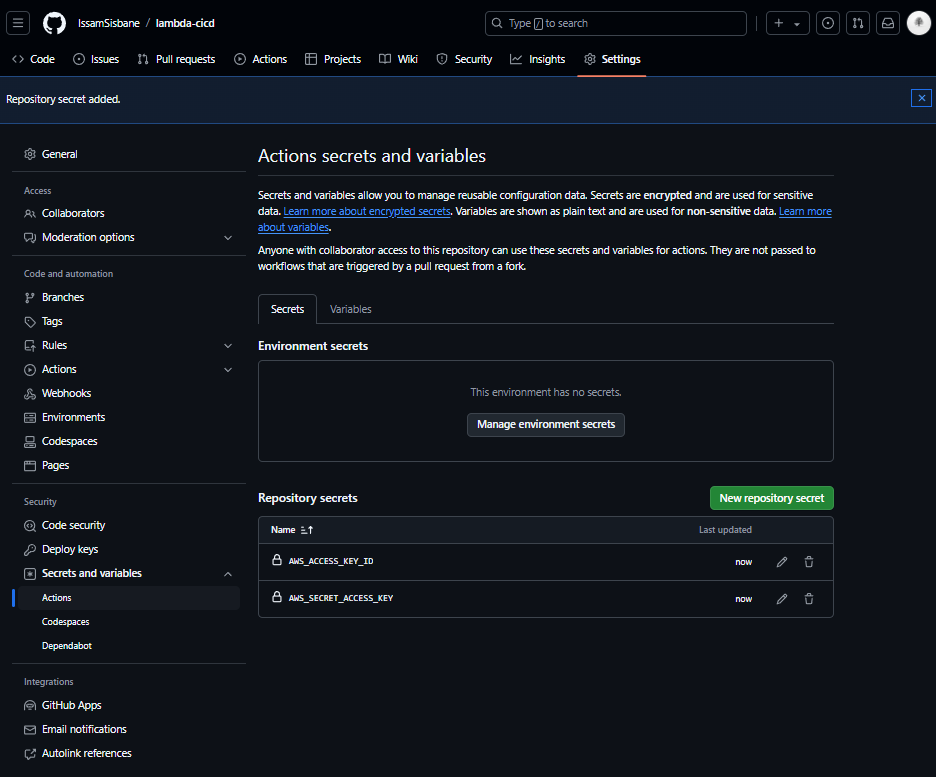
2 - Créer un nouveau secret d’actions
Nous devons stocker en toute sécurité nos identifiants AWS pour authentifier notre pipeline auprès d’AWS.
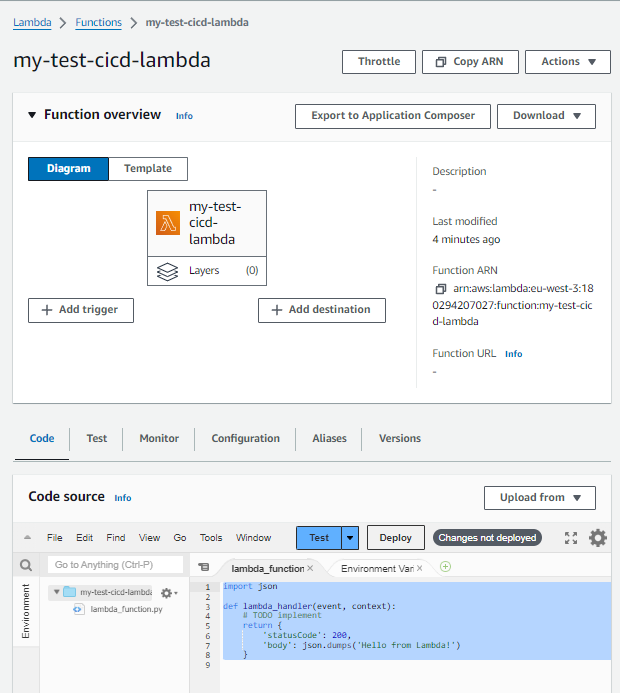
3 - Créer la fonction lambda
4 - Ajouter du code à notre référentiel pour la lambda
Initialement, le code de la lambda imprime simplement “Hello from Lambda” en réponse à une requête HTTP. Nous voulons modifier ce comportement en utilisant notre pipeline pour mettre à jour le code.
import json
def lambda_handler(event, context):
# TODO implement
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}La meilleure pratique consiste à toujours inclure un fichier requirements.txt pour les dépendances python.
Nous ajoutons le code de notre pipeline dans .github/workflows/lambda.yaml
name: Deploy AWS Lambda
on:
push:
branches:
- main
paths:
- "lambda/*"
jobs:
deploy-lambda: # Nom du job
runs-on: ubuntu-latest # Spécifier le runner
steps:
# 1 - Extraire et obtenir le code dans l'environnement du runner
- uses: actions/checkout@v2
# 2 - Configurer l'environnement Python
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: "3.12"
# 3 - Installer les dépendances
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r lambda/requirements.txt
# 4 - Configurer les identifiants AWS
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@v2
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: eu-west-3
# 5 - Zips le code lambda et met à jour la fonction lambda
- name: Deploy Lambda
run: |
cd lambda
zip -r lambda.zip .
aws lambda update-function-code --function-name my-test-cicd-lambda --zip-file fileb://lambda.zipNous pouvons mettre à jour notre code pour :
import json
def lambda_handler(event, context):
# TODO implement
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda changes made from vscode!')
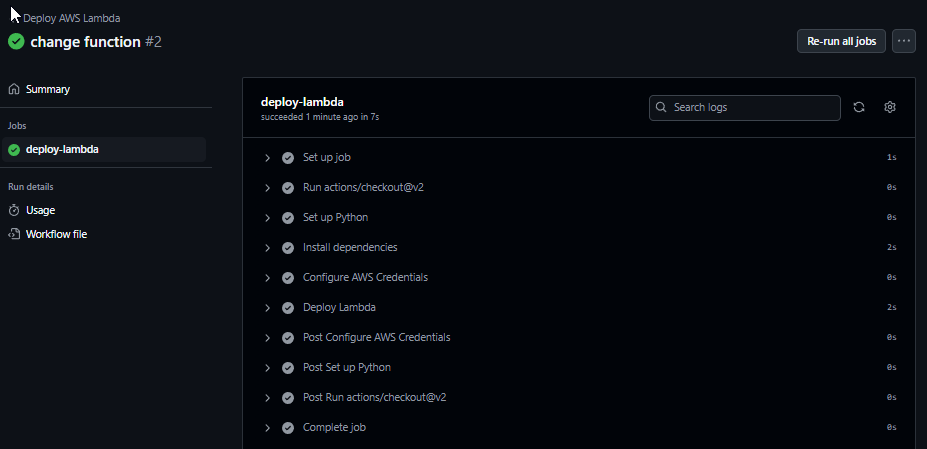
}5 - Commit & Push
Nous commettons et poussons les modifications qui déclencheront le pipeline :
3 - Vérification
Ensuite, si nous allons dans la console AWS, nous pouvons voir que le code a été mis à jour :
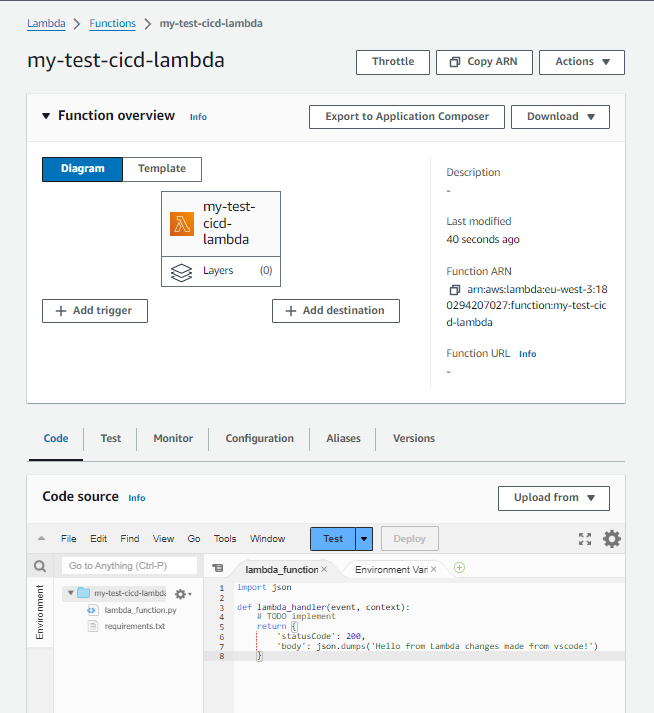
C’est un succès, nous avons mis à jour notre fonction en utilisant le pipeline GitHub Actions. Nous pouvons maintenant supprimer notre fonction.
11 - Projet | Tester un modèle CloudFormation IaC à l’aide de GitHub Actions
1 - Aperçu
Ce projet est axé sur la création d’un flux de travail GitHub Actions qui automatise le processus de création d’un bucket S3 à l’aide d’un modèle CloudFormation et de son test dans une Pull Request (PR). L’objectif est de valider si le modèle CloudFormation est correctement écrit et fonctionnel avant de fusionner la PR dans la branche principale.
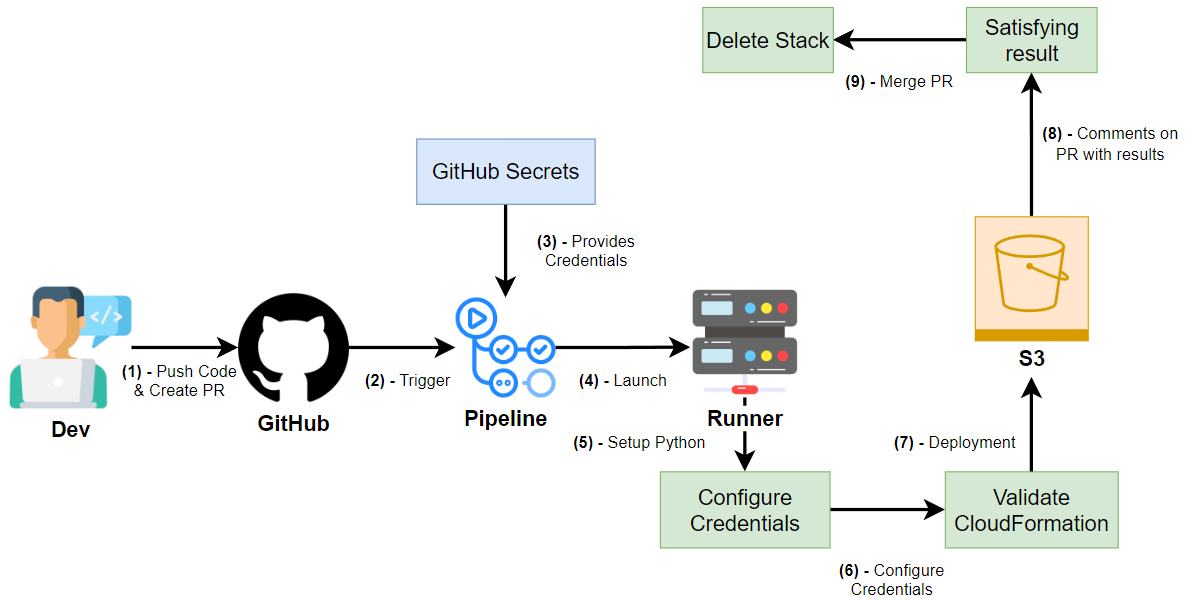
- Une fois que le développeur crée une demande d’extraction pour fusionner dans la branche principale, le flux de travail :
- Utilise le modèle CloudFormation pour créer un bucket S3.
- Publie le résultat des opérations CloudFormation dans la discussion de la PR, ainsi que le nom du bucket.
- Lors de la fusion de la PR, le flux de travail supprimera la pile (et le bucket S3), en nettoyant les ressources.
Ce flux de travail nous permet de tester le code CloudFormation dans la demande d’extraction avant qu’il ne soit fusionné dans la branche principale. Il garantit que le code d’infrastructure fonctionne correctement et empêche les erreurs d’être déployées en production.
Dans un environnement de production, un flux de travail distinct déclenché sur la branche principale gèrerait le déploiement de la pile dans l’environnement de production.
Nous utiliserons le référentiel GitHub comme notre projet précédent.
2 - Étapes
Étape 1 : Création d’une demande d’extraction
Une fois qu’une nouvelle branche est créée, le développeur créera une demande d’extraction (PR). Cela déclenche le démarrage du flux de travail, qui tentera de créer un bucket S3 à l’aide du modèle CloudFormation fourni.
Étape 2 : Gestion des erreurs
Lors de la première exécution du flux de travail, une erreur a été détectée dans le modèle CloudFormation en raison d’une indentation incorrecte.
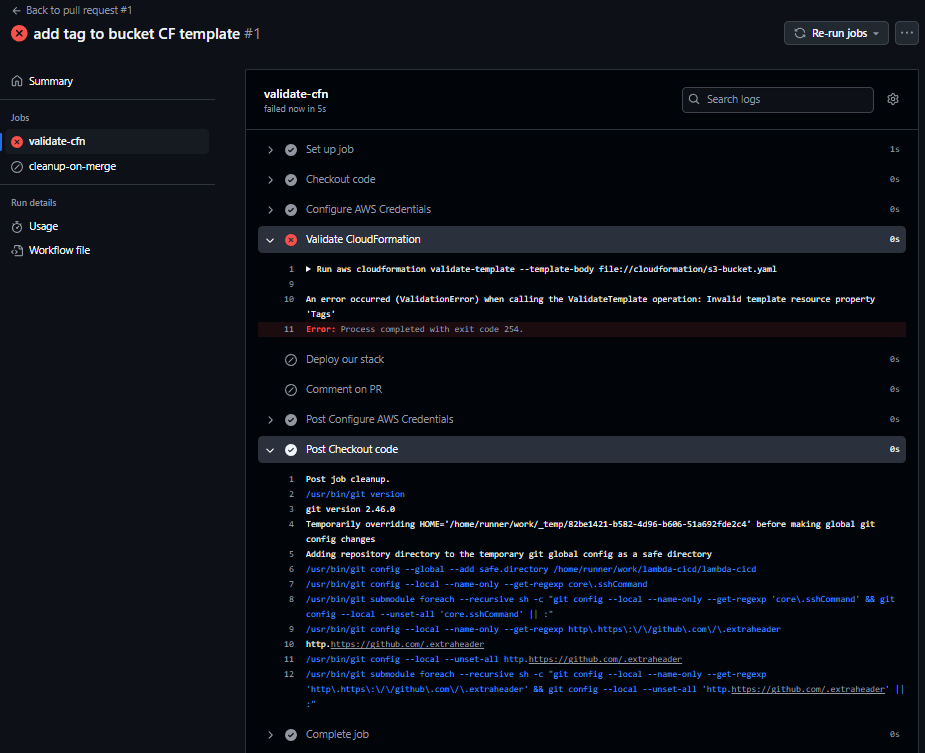
- Les journaux d’erreurs indiquaient un problème dans la structure du modèle, et après avoir corrigé le problème d’indentation, le flux de travail a été déclenché à nouveau.
Étape 3 : Validation et création réussies
Après avoir corrigé l’erreur, le pipeline s’est exécuté sans problème. Le bucket S3 a été créé avec succès, et la discussion de la PR a été mise à jour avec les résultats de la validation, y compris le nom du bucket créé.
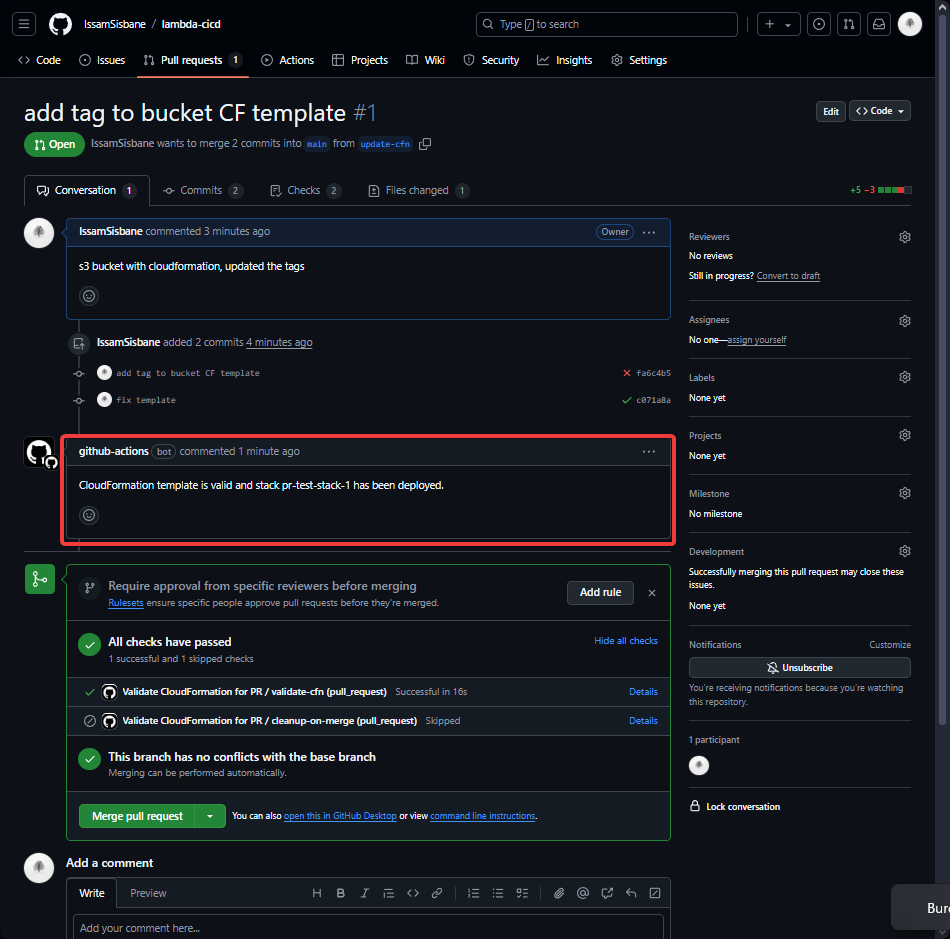
- Pile CloudFormation créée avec succès :
- Bucket S3 créé comme prévu :
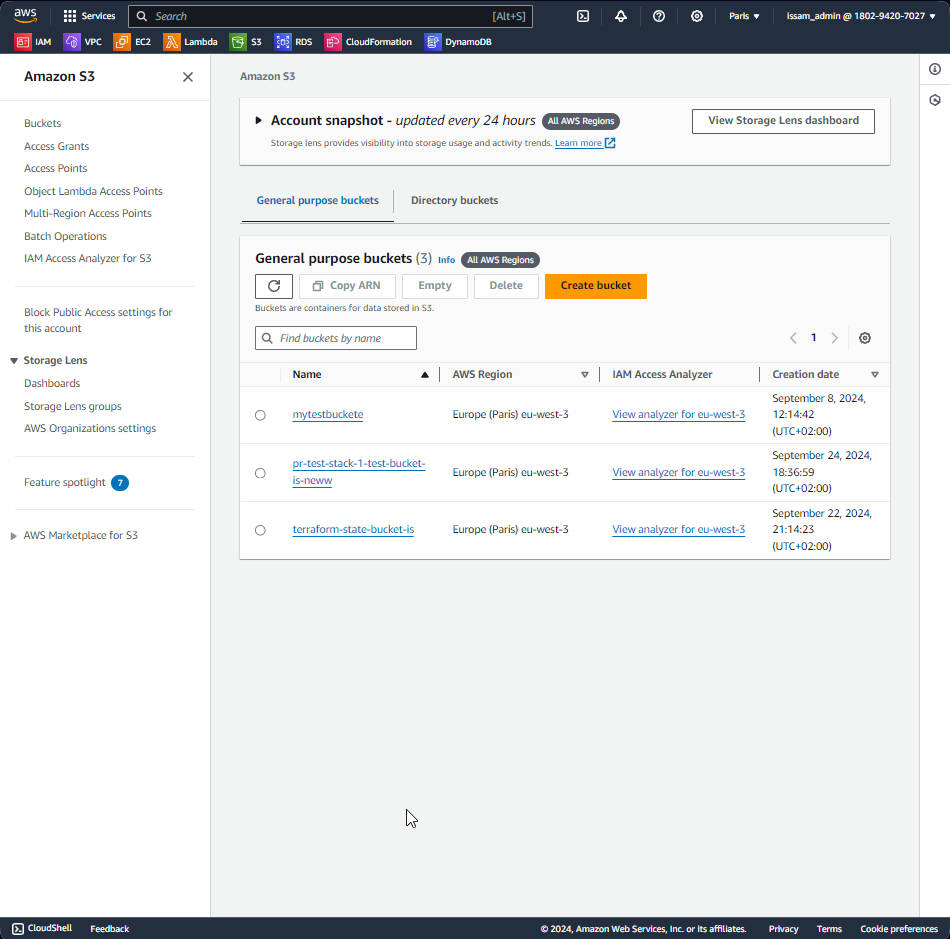
Étape 4 : L’échec du déclenchement du processus de nettoyage
Cependant, nous avons remarqué qu’après avoir fusionné la demande d’extraction, le job de nettoyage (responsable de la suppression de la pile et du bucket S3) ne s’est pas exécuté. Pour résoudre ce problème, nous avons dû mettre à jour la configuration du flux de travail.
Étape 5 : Mise à jour de la configuration du flux de travail
Pour résoudre le problème et garantir que le job de nettoyage s’exécute après la fusion de la PR, nous avons ajouté la configuration suivante au fichier de flux de travail :
on:
pull_request:
paths:
- "cloudformation/**"
types: [opened, synchronize, reopened, closed]Cela garantit que le flux de travail se déclenche sur des événements PR spécifiques (opened, synchronized, reopened et closed) et uniquement pour les fichiers du répertoire cloudformation/.
Étape 6 : Empêcher le job de validation de s’exécuter lors de la fusion
De plus, nous avons mis à jour le job validate-cfn pour éviter d’exécuter la validation CloudFormation lorsque la PR est fusionnée. Nous avons ajouté la condition suivante pour ignorer cette étape lorsque la PR est fusionnée :
jobs:
validate-cfn:
if: github.event.pull_request.merged == falseCela garantit que le job de validation ne s’exécute que pour les PR non fusionnées, empêchant une exécution inutile une fois le code déjà fusionné.
Étape 7 : Exécution réussie du job de nettoyage
Après avoir appliqué les correctifs, le flux de travail s’est exécuté correctement et le job de nettoyage s’est exécuté avec succès après la fusion de la PR. La pile et le bucket S3 ont été supprimés comme prévu.
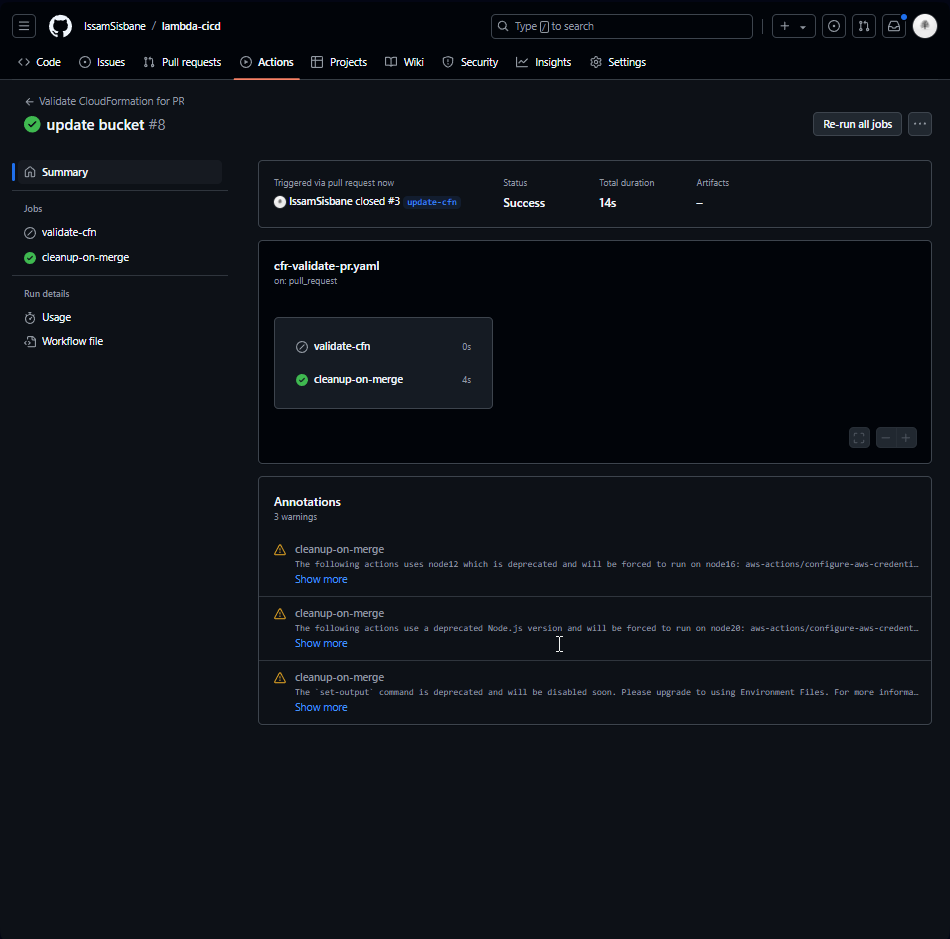
Enfin, tout a fonctionné comme prévu, et les ressources ont été nettoyées une fois la demande d’extraction fusionnée. Après avoir créé une nouvelle branche et créé une demande d’extraction, notre flux de travail a démarré et a trouvé une erreur dans notre modèle Cloudformation.
3 - Conclusion
Ce projet met en valeur la puissance et la flexibilité de GitHub Actions lorsqu’il est combiné avec CloudFormation pour automatiser les tâches d’infrastructure. En intégrant ce flux de travail dans le processus de développement, nous pouvons :
- Valider le code d’infrastructure dans les demandes d’extraction.
- Garantir la justesse de l’infrastructure avant la fusion dans la branche principale.
- Créer et supprimer automatiquement des ressources, en gardant l’environnement propre.
Dans un véritable environnement de production, nous utiliserions probablement une stratégie de déploiement plus robuste avec des flux de travail distincts pour les environnements de pré-production et de production, garantissant un processus de déploiement d’infrastructure fluide et fiable.
Cette configuration démontre également comment l’automatisation des processus de validation d’infrastructure et de nettoyage peut aider à garantir que les modifications d’infrastructure sont sûres, reproductibles et gérables dans différents environnements.
Il était intéressant de voir comment nous pouvons valider IaC avant de fusionner dans la branche principale. Je n’avais jamais pensé à cette méthode auparavant.