
Améliorer mes compétences Cloud - Semaine 7 - Terraform
1 - Principes fondamentaux de Terraform
2 - Terraform vs CloudFormation
3 - Exemple simple de Terraform
4 - Commandes Terraform
5 - Fichiers de configuration Terraform
6 - Architecture Terraform
7 - Projet - 5 - Déployer un VPC avec Terraform
8 - Projet - 6 - Déployer une application Next-Js avec Terraform
1 - Principes fondamentaux de Terraform
Terraform, développé par HashiCorp, est l’un des outils Infrastructure as Code (IaC) les plus largement utilisés. Il permet aux utilisateurs de construire, modifier et contrôler la version de l’infrastructure sur plusieurs fournisseurs de cloud, environnements sur site et même des configurations hybrides. Terraform simplifie la gestion de l’infrastructure en permettant aux développeurs et aux équipes d’exploitation de définir leur infrastructure en code, en utilisant une approche déclarative.
À la base, Terraform utilise HCL (HashiCorp Configuration Language) pour décrire l’état souhaité de l’infrastructure. Cela facilite la gestion de l’infrastructure de manière cohérente et prévisible.
Principales caractéristiques
Approche déclarative
Terraform adopte un modèle de configuration déclaratif, ce qui signifie que les utilisateurs définissent ce à quoi l’infrastructure doit ressembler, et Terraform détermine automatiquement comment mettre en œuvre ces changements. Cela réduit la complexité de la gestion de l’infrastructure en abstraisant les processus sous-jacents nécessaires pour atteindre l’état souhaité.
- Exemple : Vous spécifiez que vous avez besoin d’une instance EC2 dans AWS, et Terraform gère le provisionnement, la configuration et la connexion à d’autres ressources.
Indépendant du cloud
Terraform est indépendant du cloud, ce qui signifie qu’il peut fonctionner avec un large éventail de fournisseurs de cloud, notamment AWS, Azure, Google Cloud Platform (GCP), IBM Cloud, et bien d’autres. Il peut également être utilisé pour l’infrastructure sur site (par exemple, VMware) ou les environnements hybrides. Cela permet aux équipes de gérer les ressources sur plusieurs clouds en utilisant un seul ensemble d’outils cohérent.
Gestion de l’état
Terraform suit l’état actuel de l’infrastructure grâce à des fichiers d’état. Ces fichiers stockent des informations sur les ressources que Terraform gère, ce qui lui permet de comprendre ce qui a déjà été provisionné et les modifications à apporter lors des mises à jour.
- Exemple : Si une nouvelle ressource est ajoutée à la configuration, Terraform compare le fichier d’état avec l’infrastructure réelle et ne crée que la nouvelle ressource sans perturber les ressources existantes.
Architecture modulaire
Terraform encourage l’utilisation de modules réutilisables, qui sont des ensembles de configurations prédéfinis qui peuvent être réutilisés dans plusieurs projets. Cela permet de maintenir la cohérence, de réduire la duplication de code et d’améliorer la gestion d’une infrastructure complexe. Les modules facilitent le partage des meilleures pratiques et la gestion de l’infrastructure à grande échelle.
Fournisseurs et plugins
Fournisseurs
Les fournisseurs sont les composants principaux qui permettent à Terraform de gérer les ressources d’infrastructure sur différentes plateformes. Les fournisseurs agissent comme le pont entre Terraform et les plateformes externes comme AWS, Azure et GCP. Chaque fournisseur offre un ensemble de ressources et de sources de données avec lesquelles Terraform peut interagir. Ils sont responsables de l’exécution des appels d’API pour interagir avec les services cloud et d’exposer ces services en tant que ressources gérables dans les configurations Terraform.
Comment fonctionnent les fournisseurs ?
Lors de la configuration d’un fournisseur dans Terraform, les plugins de fournisseur nécessaires sont automatiquement téléchargés et installés pendant la phase terraform init. Terraform s’assure que la bonne version du fournisseur est utilisée, garantissant ainsi la compatibilité avec le cœur de Terraform.
Le registre de fournisseurs de Terraform contient des fournisseurs officiels et contribués par la communauté, ce qui facilite la découverte et l’utilisation d’un large éventail de fournisseurs.
Configurer un fournisseur :
provider "aws" {
region = "us-west-2"
access_key = "my-access-key"
secret_key = "my-secret-key"
}Définir des ressources :
resource "aws_instance" "example" {
ami = "ami-0fjezofijzf"
instance_type = "t2.micro"
}Plusieurs fournisseurs dans une seule configuration
Terraform vous permet de configurer plusieurs fournisseurs dans un seul fichier de configuration. Ceci est particulièrement utile lorsque vous devez gérer des ressources sur différentes régions ou plateformes cloud.
provider "aws" {
alias = "west"
region = "us-west-1"
}
provider "aws" {
alias = "east"
region = "us-east-1"
}
resource "aws_instance" "example_west" {
provider = aws.west
}
resource "aws_instance" "example_east" {
provider = aws.east
}
Concepts clés
Configuration du fournisseur
La configuration du fournisseur vous permet de définir les informations d’identification et les paramètres nécessaires pour que Terraform interagisse avec la plateforme spécifique. Elle comprend :
- les détails d’authentification (par exemple, les clés d’accès, les clés secrètes),
- les paramètres de région
- les options spécifiques au fournisseur.
provider "aws" {
region = "eu-west-3"
access_key = "my-access-key"
secret_key = "my-secret-key"
}Gestion des ressources
Chaque fournisseur définit et gère des types de ressources que vous pouvez spécifier dans les configurations Terraform. Les ressources représentent des composants d’infrastructure spécifiques comme les instances EC2, les compartiments S3, les bases de données, etc.
resource "aws_instance" "example" {
ami = "ami-0fjezofijzf"
instance_type = "t2.micro"
}Sources de données
Les sources de données dans Terraform vous permettent de récupérer et d’utiliser des informations provenant de sources externes ou d’autres configurations. Elles peuvent être utilisées pour référencer des informations que Terraform ne gère pas directement mais dont il a besoin pour la configuration.
data "aws_vpc" "default" {
default = true
}2 - Terraform vs CloudFormation
AWS CloudFormation est un service natif AWS Infrastructure as Code (IaC) qui fournit un moyen déclaratif de définir, de provisionner et de gérer les ressources au sein de l’écosystème AWS. Il utilise des stacks, qui sont des collections de ressources définies dans des modèles de configuration écrits en YAML ou JSON. CloudFormation est spécifique à AWS, ce qui le rend profondément intégré aux services AWS, mais limité en termes de portabilité en dehors d’AWS.
Terraform, d’autre part, est un outil IaC indépendant du cloud développé par HashiCorp. Il vous permet de provisionner et de gérer l’infrastructure sur plusieurs fournisseurs de cloud et environnements, tels que AWS, Azure, GCP et les systèmes sur site, en utilisant une approche déclarative et HCL (HashiCorp Configuration Language).
| Outil | Portabilité | Gestion des ressources | Avantages | Inconvénients |
|---|---|---|---|---|
| CloudFormation | Natif AWS | Stacks | Géré | Verrouillage AWS, Beaucoup de code à écrire |
| Terraform | Indépendant du cloud | Fichiers d’état | Indépendant du cloud et grande communauté | Courbe d’apprentissage, Gestion d’état complexe, Licences et n’est plus Open-source. |
| Dans CloudFormation, nous parlons de propriétés et dans Terraform, nous parlons de paramètres de ressources. |
3 - Exemple simple de Terraform
1. Configurer Terraform pour AWS :
main.ts
provider "aws" {
region = "eu-west-3"
}2. Initialiser la configuration Terraform
terraform init3. Planifier pour afficher les modifications apportées à l’infrastructure
terraform plan4. Appliquer les modifications à l’infrastructure
terraform applyÀ mon avis, nous obtenons de meilleurs résultats de Terraform que de CloudFormation :
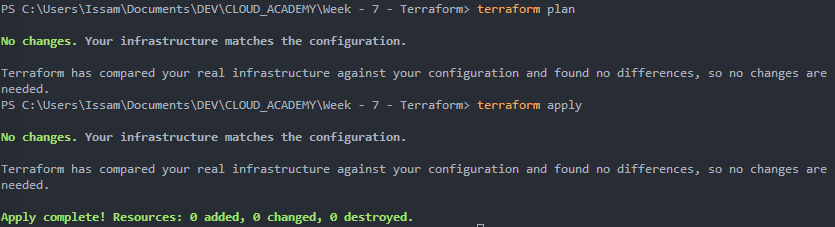
4 - Commandes Terraform
Commandes de base
Init
Initialise une nouvelle configuration Terraform ou une configuration existante :
# Télécharge les plugins de fournisseur nécessaires et configure le backend pour le stockage des fichiers d'état
terraform initPlan
Compare l’état actuel et l’état souhaité dans les fichiers de configuration et détermine les actions à entreprendre pour atteindre l’état souhaité en créant un plan d’exécution :
# Affiche les modifications que Terraform apportera à l'infrastructure avant de les appliquer
terraform planApply
Applique les modifications à l’infrastructure et exécute les actions proposées dans le plan :
# Crée, modifie ou supprime des ressources selon les besoins
terraform applyShow
Affiche l’état actuel des ressources d’infrastructure dans un format lisible par l’homme :
terraform showOutput
Récupère les valeurs de sortie définies dans la configuration Terraform (adresses IP, métadonnées…) :
terraform outputDestroy
Supprime toutes les ressources gérées par la configuration Terraform :
terraform destroyFmt
Formate les fichiers de configuration Terraform selon les conventions de style canoniques :
terraform fmtValidate
Vérifie la syntaxe des fichiers de configuration Terraform et s’assure qu’ils sont correctement formatés :
terraform validateFlux de travail typique
En général, nous faisons :
1 - Planifier
terraform plan2 - Appliquer
terraform apply3 - Observer
terraform show
terraform output5 - Fichiers de configuration Terraform
Nous utilisons des fichiers .tf pour écrire notre configuration en utilisant HCL. On peut trouver 5 éléments dans les modèles de configuration :
- provider
- resource
- variable
- datasource
- output
# Fournisseurs - Définissent avec quels fournisseurs de cloud ou services Terraform interagira
provider "aws" {
region = "us-west-2"
}
# Ressources - Définissent les composants d'infrastructure qui seront créés
resource "aws_instance" "example" {
ami = "ami-0c55b159cbfafe1f0"
instance_type = var.instance_type # "t2.micro"
tags = { # métadonnées
Name = "ec2-instance"
}
}
# Variables - Permettent de rendre la configuration plus flexible et réutilisable
variable "instance_type" {
description = "Le type d'instance à créer"
default = "t2.micro"
}
# Sorties - Retournent des données de la configuration à l'utilisateur
output "instance_id" {
description = "L'ID de l'instance EC2"
value = aws_instance.example.id
}
# Sources de données - Définissent les sources de données qui seront utilisées pour récupérer des informations qui ne sont pas définies dans la configuration
data "aws_ami" "example" {
most_recent = true
owners = ["self"]
tags = {
Name = "app-server"
Tested = "true"
}
}6 - Architecture Terraform
Terraform est structuré autour d’un flux de travail simple, mais puissant, qui exploite les fournisseurs pour interagir avec les API de différentes plateformes (telles que AWS, Azure ou Google Cloud). Terraform est conçu pour gérer l’infrastructure de manière cohérente, évolutive et déclarative. Cette architecture offre une flexibilité pour la gestion d’environnements complexes tout en simplifiant la gestion des ressources grâce à des configurations et des modules réutilisables.
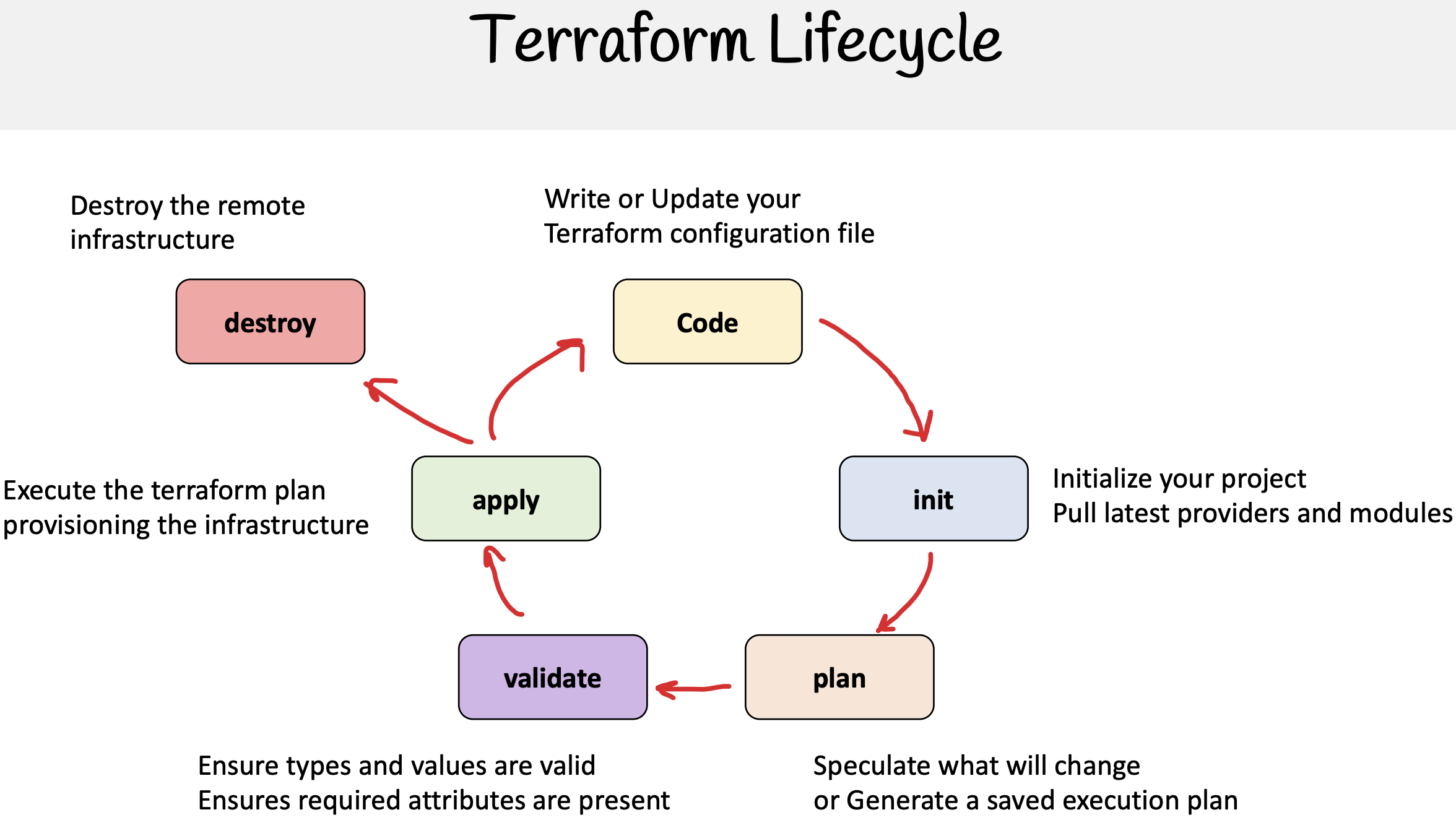
Flux de travail Terraform
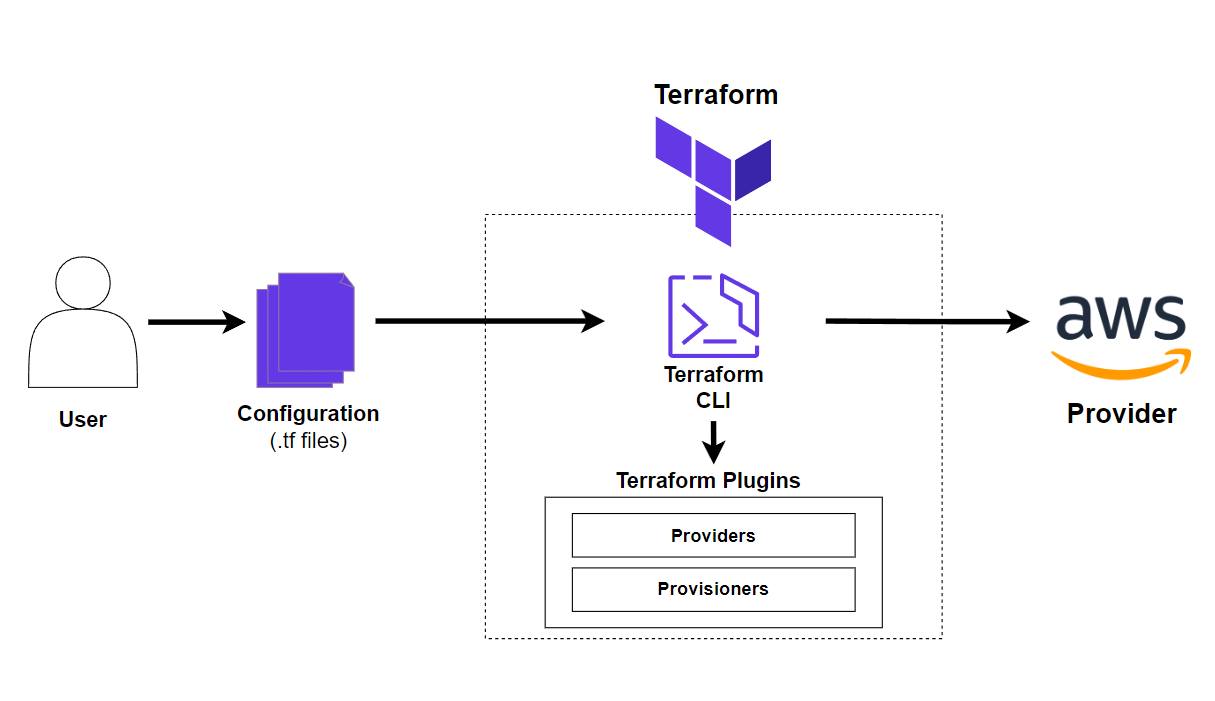
Le flux de travail Terraform suit un ensemble clair d’étapes qui permettent un processus transparent, de la définition de l’infrastructure à son déploiement et à sa validation :
1. Définir
- Nous écrivons des fichiers de configuration en utilisant HCL (HashiCorp Configuration Language) qui décrivent l’infrastructure souhaitée. Ces fichiers spécifient les ressources dont nous avons besoin, comment elles doivent être configurées et les dépendances entre elles.
2. Init
- Nous initialisons le projet Terraform dans le répertoire de travail en utilisant la commande
terraform init. Cette étape télécharge les plugins de fournisseur nécessaires et configure la configuration du backend, y compris les fichiers d’état.
3. Planifier
- Terraform génère un plan d’exécution en utilisant la commande
terraform plan, qui montre les modifications que Terraform apportera à l’infrastructure. Il s’agit d’une étape cruciale pour examiner les modifications potentielles avant de les appliquer.
4. Appliquer
- En utilisant la commande
terraform apply, nous appliquons les modifications de configuration à l’infrastructure en fonction du plan créé précédemment. Terraform effectuera les appels d’API nécessaires via les fournisseurs définis pour créer, mettre à jour ou supprimer des ressources selon les besoins.
5. Valider
- Après le déploiement, l’infrastructure est validée pour s’assurer que les ressources ont été correctement configurées et qu’elles répondent aux critères attendus. La validation peut être effectuée manuellement ou par le biais d’outils automatisés.
Structure du projet Terraform
Terraform encourage l’utilisation des meilleures pratiques et une organisation de projet structurée pour simplifier la gestion de l’infrastructure et améliorer la collaboration.
Modules
Les modules dans Terraform permettent la réutilisation et le partage des configurations. Ils respectent le principe DRY (Don’t Repeat Yourself), permettant aux équipes d’éviter de dupliquer du code sur plusieurs projets.
Ils sont réutilisables et partageables. Principes DRY.
Structure des fichiers du projet
Un projet Terraform typique suit une approche structurée pour l’organisation des fichiers. Nous voulons utiliser des conventions de nommage pour faciliter la compréhension de notre projet. Nous séparons les environnements et nous utilisons toujours main.ts, outputs.tf et wariables.tf pour la cohérence. Il est préférable de séparer les différentes parties de la configuration dans des fichiers spécifiques, tels que :
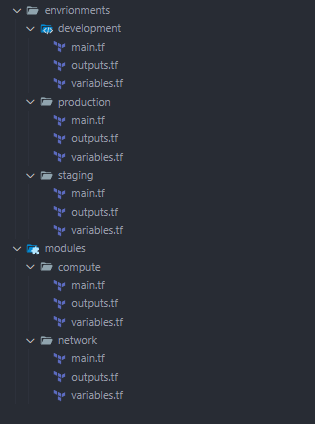
- main.tf : Définit les principales ressources d’infrastructure.
- variables.tf : Contient les variables d’entrée pour paramétrer les configurations.
- outputs.tf : Définit les valeurs de sortie que Terraform affichera après l’application de la configuration (par exemple, les ID d’instance, les IP publiques).
- provider.tf : Définit le(s) fournisseur(s) et toutes les configurations nécessaires, comme les informations d’identification et les régions.
Vous pouvez organiser davantage le projet en créant des fichiers spécifiques pour différentes ressources, telles que ec2.tf pour les instances EC2 ou vpc.tf pour les configurations VPC, afin d’améliorer la lisibilité et la maintenabilité.
Fichiers d’état (terraform.tfstate)
Par défaut, Terraform stocke l’état de votre infrastructure localement. Le fichier d’état (terraform.tfstate) suit la correspondance entre l’infrastructure du monde réel et les configurations. Cela permet à Terraform de savoir quelles ressources existent, leurs dépendances et comment les mettre à jour.
- Pourquoi les fichiers d’état sont importants :
- Suivi de l’infrastructure : Le fichier d’état contient l’état actuel de l’infrastructure déployée, afin que Terraform sache quelles modifications apporter.
- Gestion des dépendances : Terraform s’appuie sur le fichier d’état pour gérer les dépendances entre les ressources (par exemple, une instance EC2 dépend d’un VPC).
Fichiers d’état distants
terraform.tfstate
Par défaut, les fichiers d’état sont stockés localement par Terraform. Dans les grandes équipes ou environnements, il est préférable d’utiliser le stockage d’état distant (Terraform Cloud, S3…) pour permettre la collaboration et s’assurer que plusieurs utilisateurs peuvent accéder et mettre à jour l’infrastructure en toute sécurité. Les backends distants offrent également le verrouillage d’état, empêchant plusieurs utilisateurs de modifier l’état simultanément et de provoquer des conflits.
Nous pouvons utiliser S3 et mongodb par exemple car il s’agit d’objets de données json.
Création d’un état distant avec S3
Un exemple de configuration d’un état distant dans Amazon S3, nous pouvons nommer ce fichier comme nous le souhaitons, mais il est de bonne pratique de le nommer state.tf car il est déclaratif et explicite :
# exécuter terraform init pour configurer l'état
terraform {
backend "s3" { # bloc backend pour définir le backend s3
bucket = "terraform-state-bucket-is" # Le compartiment S3 pour stocker le fichier d'état
key = "global/s3/terraform.tfstate" # Le chemin dans le compartiment où le fichier d'état est stocké
region = "eu-west-3" # La région AWS du compartiment S3
dynamodb_table = "s3-tf-table" # Table DynamoDB pour le verrouillage d'état
}
}Avantages de l’utilisation d’un backend distant :
- Collaboration : Plusieurs membres de l’équipe peuvent travailler sur le même projet Terraform sans conflits, car l’état est stocké de manière centralisée.
- Sécurité : Le fichier d’état peut contenir des informations sensibles (comme les ID de ressources et les métadonnées), donc l’utilisation de politiques IAM pour un accès sécurisé à l’état distant garantit la confidentialité.
- Verrouillage d’état : L’utilisation de DynamoDB pour verrouiller le fichier d’état empêche les conditions de concurrence ou les modifications simultanées de l’infrastructure.
- Reprise après sinistre : Le stockage de l’état à distance garantit que l’état peut être restauré en cas de défaillances locales ou de catastrophes.
Considérations importantes pour l’état distant
-
Créer manuellement l’infrastructure d’état :
- Il est important de créer manuellement le compartiment S3 et la table DynamoDB avant de les utiliser comme backends. Si Terraform gérait lui-même l’infrastructure d’état, cela pourrait créer un problème de type œuf ou la poule, où Terraform a besoin d’un état pour gérer les ressources qui fournissent le stockage d’état.
-
Exécution de Terraform Init :
- Après avoir configuré le backend distant, vous devez exécuter
terraform initpour réinitialiser le backend. Cette commande configurera le compartiment S3 et la table DynamoDB comme emplacement d’état distant.
- Après avoir configuré le backend distant, vous devez exécuter
-
Sensibilité du fichier d’état :
- Étant donné que le fichier d’état peut contenir des informations sensibles sur votre infrastructure (telles que les adresses IP, les données utilisateur ou les informations d’identification), il est essentiel de sécuriser l’accès à l’état à l’aide de rôles IAM et d’options de chiffrement dans S3.
7 - Projet | Déployer notre VPC d’avant
Nous avons déjà déployé une architecture VPC en utilisant clickOps & CloudFormation. Vous pouvez trouver le lien ici Maintenant, nous voulons le déployer à nouveau en utilisant Terraform.
1. Définir l’état distant
Nous devons créer un compartiment S3 et une table DynamoDB. Ensuite, créez un fichier state.tf :
terraform { # bloc de niveau supérieur pour définir le comportement de terraform dans notre configuration de backend
backend "s3" { # bloc de backend pour définir le backend s3
bucket = "terraform-state-bucket-is" # nom du compartiment pour stocker le fichier d'état
key = "global/s3/terraform.tfstate" # chemin où stocker le fichier d'état dans le compartiment
region = "eu-west-3"
dynamodb_table = "terraform-locks" # nom de la table dynamodb pour verrouiller le fichier d'état, afin d'éviter les modifications simultanées
}
}Nous voulons exécuter terraform init pour configurer notre état distant. Avant cela, nous devons créer notre compartiment s3 et notre table DynamoDB.
terraform initPour vérifier, j’ai essayé :
terraform planJ’ai rencontré cette erreur :
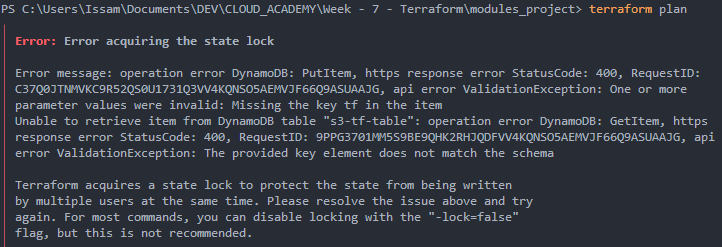
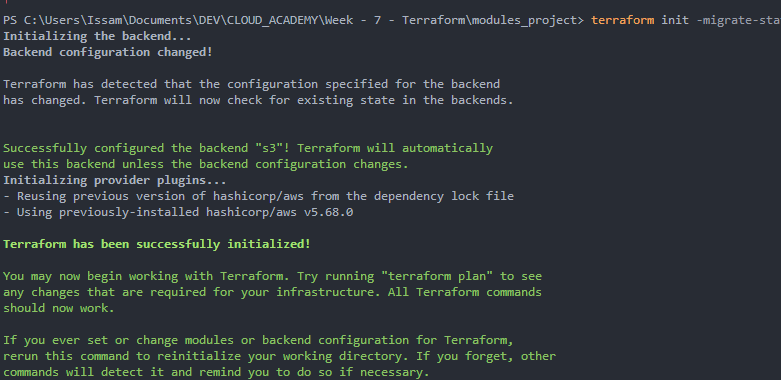
C’était parce que j’ai nommé la clé de partition tf, mais nous devons la nommer LockID. J’ai dû recréer une nouvelle table et modifier le fichier state.tf avec le nom de la nouvelle table.
Maintenant, ça marche :
2. Écriture de la configuration
J’ai créé la configuration dans main.tf :
provider "aws" {
region = "eu-west-3"
}
# VPC
resource "aws_vpc" "main" {
cidr_block = "192.168.0.0/16"
tags = {
Name = "main-tf-vpc"
}
}
# Sous-réseau 1
resource "aws_subnet" "subnet1" {
vpc_id = aws_vpc.main.id
cidr_block = "192.168.1.0/24"
availability_zone = "eu-west-3a"
tags = {
Name = "main-tf-vpc-subnet1"
}
}
# Sous-réseau 1
resource "aws_subnet" "subnet2" {
vpc_id = aws_vpc.main.id
cidr_block = "192.168.2.0/24"
availability_zone = "eu-west-3b"
tags = {
Name = "main-tf-vpc-subnet2"
}
}
# Passerelle Internet
resource "aws_internet_gateway" "igw" {
vpc_id = aws_vpc.main.id
tags = {
Name = "main-tf-vpc-igw"
}
}
# Table de routage
resource "aws_route_table" "rt" {
vpc_id = aws_vpc.main.id
route {
cidr_block = "0.0.0.0/0"
gateway_id = aws_internet_gateway.igw.id
}
tags = {
Name = "main-tf-vpc-rt"
}
}
# Association de la table de routage Sous-réseau 1
resource "aws_route_table_association" "rta1" {
subnet_id = aws_subnet.subnet1.id
route_table_id = aws_route_table.rt.id
}
# Association de la table de routage Sous-réseau 2
resource "aws_route_table_association" "rta2" {
subnet_id = aws_subnet.subnet2.id
route_table_id = aws_route_table.rt.id
}3. Planifier
Nous exécutons :
terraform planNous pouvons examiner tout ce qui sera déployé :
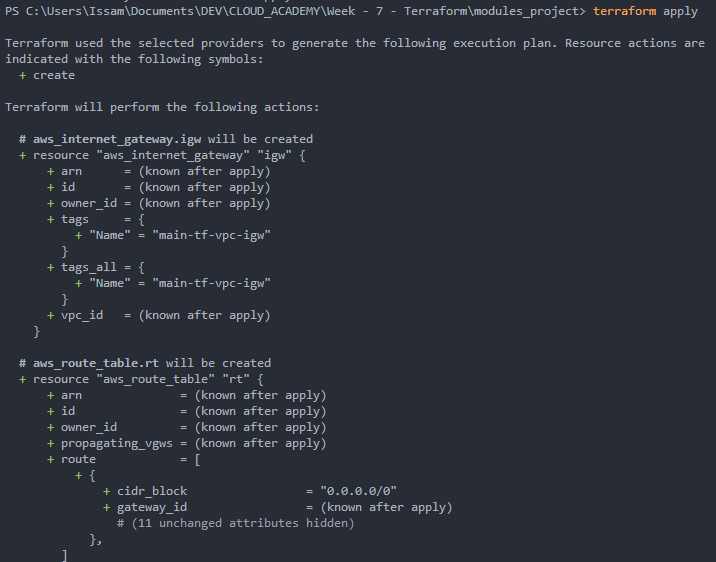
4. Appliquer
Nous pouvons ensuite valider pour laisser Terraform créer les ressources :
terraform apply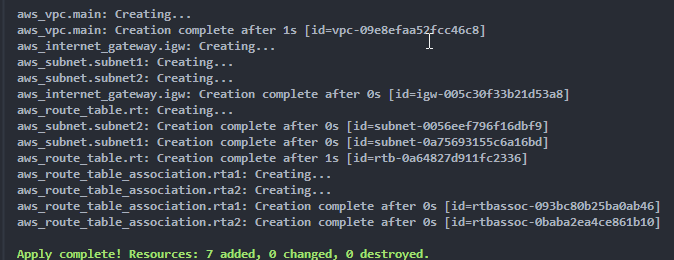
Nous pouvons aller sur le portail AWS pour vérifier que tout a été créé.
5. Nettoyer
Enfin, nous pouvons supprimer les ressources :
terraform destroy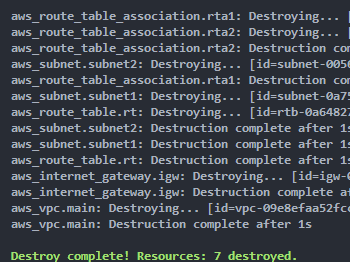
Enfin, nous pourrions conclure que Terraform a une syntaxe moins verbeuse, ce qui le rend plus facile que CloudFormation. De plus, nous avons beaucoup plus d’informations dans l’interface de ligne de commande et nous pourrions directement voir si tout va bien, ce qui est beaucoup mieux et plus visuel.
8 - Projet | Déployer une application Next-Js
[[Contrôle d’accès au compartiment AWS]]
1. Exigences
Aperçu du scénario
Client : James Smith, un concepteur web indépendant
Projet : Déploiement du site web du portfolio
Description du projet : James Smith, un concepteur web indépendant, souhaite présenter son travail et attirer des clients potentiels grâce à un portfolio en ligne. Il a conçu un site web moderne et réactif d’une seule page en utilisant le framework Next.js. James a besoin que ce site web soit hébergé sur une plateforme robuste, évolutive et rentable. De plus, le site web doit être hautement disponible et offrir des temps de chargement rapides pour un public mondial.
Mon rôle : En tant qu’équipe d’ingénieurs cloud, la tâche consiste à déployer le site web du portfolio de James sur AWS en utilisant les principes de l’Infrastructure as Code (IaC) avec Terraform. Ce projet me donnera une expérience pratique avec Terraform, S3 et CloudFront, en imitant un scénario de déploiement réel.
Énoncé du problème
James a besoin que son site web de portfolio soit :
- Hautement disponible : Le site web doit être accessible aux utilisateurs du monde entier avec un minimum de temps d’arrêt.
- Évolutif : Au fur et à mesure que son portfolio gagne en popularité, la solution d’hébergement doit gérer l’augmentation du trafic sans dégradation des performances.
- Rentable : Les coûts d’hébergement doivent être optimisés, en évitant les dépenses inutiles.
- Chargement rapide : Le site web doit se charger rapidement pour les visiteurs, offrant une expérience utilisateur transparente.
Compte tenu de ces exigences, le déploiement du site web à l’aide de services AWS tels que S3 pour l’hébergement statique et CloudFront pour la diffusion de contenu est une solution idéale. L’utilisation de Terraform vous permettra d’automatiser et de gérer l’infrastructure efficacement.
Résultat du projet
À la fin de ce projet, nous devrions avoir :
- Déployé un site web Next.js : Déployé avec succès le site de portfolio Next.js sur AWS.
- Implémenté l’Infrastructure as Code : Utilisé Terraform pour automatiser la création des ressources AWS.
- Configuré la diffusion de contenu globale : Configuré AWS CloudFront pour diffuser le contenu du site web à l’échelle mondiale avec une faible latence.
- Assuré la sécurité et les performances : Appliqué les meilleures pratiques en matière de sécurité et de performances, garantissant un site web rapide et sécurisé pour le portfolio de James.
- Tout déployer sur github : Créer un dépôt github et héberger tous vos fichiers et codes de projet là-bas.
Voici la conception de l’architecture :
**
Nous utiliserions uniquement l’exemple de modèle de nextJS pour simplifier, mais nous pourrions utiliser n’importe quel site web statique.
2. S3 & Cloudfront
L’utilisation d’Amazon CloudFront avec Amazon S3 vous permet de configurer un réseau de diffusion de contenu (CDN) qui améliore les performances, la sécurité et l’évolutivité de votre site web ou de votre application. En diffusant le contenu à partir de serveurs situés plus près de l’utilisateur, CloudFront peut réduire considérablement la latence et améliorer la vitesse à laquelle les données sont diffusées. Je n’ai jamais utilisé de CDN auparavant, j’ai lu la documentation sur son fonctionnement avec S3. C’est assez simple.
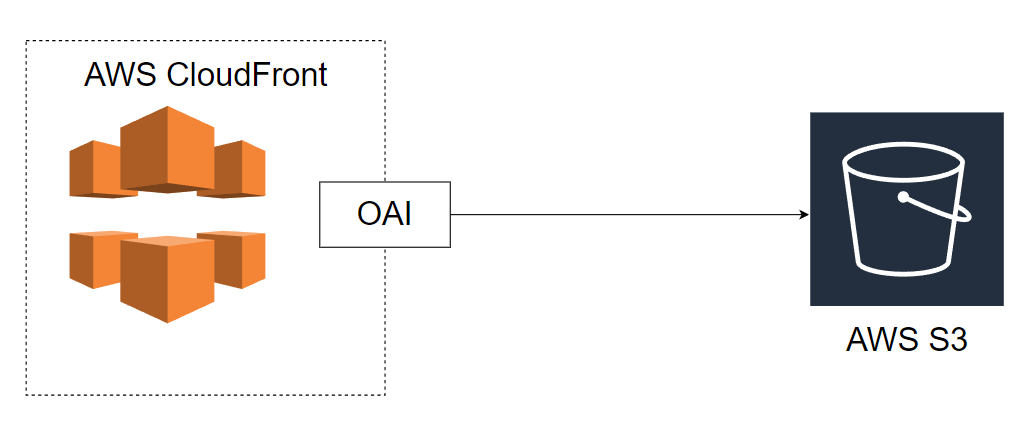
Le diagramme ci-dessus décrit la relation entre le compartiment S3, CloudFront et OAI. Voici comment les composants s’assemblent :
-
Distribution CloudFront :
- Agit comme le point de terminaison public avec lequel les utilisateurs interagissent.
- La distribution est configurée pour utiliser votre compartiment S3 comme origine pour la diffusion de contenu statique (comme
index.htmlou d’autres fichiers).
-
Compartiment S3 :
- Le compartiment stocke le contenu (par exemple, les pages web statiques, les images, les vidéos).
- Il doit être privé pour garantir que personne ne peut accéder directement au compartiment depuis Internet.
-
Identité d’accès à l’origine (OAI) :
- L’OAI est associé à la distribution CloudFront et est l’identité utilisée pour accéder au compartiment S3 privé.
- Cela garantit que seul CloudFront peut accéder à votre compartiment S3, offrant un contrôle d’accès sécurisé.
-
Politique de compartiment :
- Vous devez configurer une politique de compartiment S3 pour autoriser explicitement CloudFront (via l’OAI) à accéder au contenu de votre compartiment S3.
- Cela restreint l’accès public au compartiment et n’autorise que les requêtes provenant de la distribution CloudFront.
Nous avons notre distribution CloudFront configurée avec notre compartiment S3 comme origine. Nous voulons seulement que les gens accèdent à notre fichier index.html dans notre compartiment uniquement à partir de CloudFront. Nous utilisons donc un OAI. L’OAI permet à S3 d’identifier notre distribution CloudFront. Nous devons créer des politiques de compartiment pour autoriser l’accès au compartiment. Ce que nous avons fait plus tôt n’était pas vraiment une bonne pratique car notre compartiment est accessible de n’importe où par n’importe qui.
3. Déploiement
Vous pouvez trouver tout le projet ici.
Pour ce projet, j’autorise d’abord l’accès public par n’importe qui, de n’importe où.
provider "aws" {
region = "eu-west-3"
}
# Créer un nouveau compartiment S3
resource "aws_s3_bucket" "portfolio_is_bucket" {
bucket = "portfolio-nextjs-is"
tags = {
Name = "portfolio-nextjs-is"
}
}
# Activer les contrôles de propriété du compartiment pour appliquer les autorisations du propriétaire du compartiment
resource "aws_s3_bucket_ownership_controls" "portfolio_is_ownership_controls" {
depends_on = [
aws_s3_bucket.portfolio_is_bucket
]
bucket = aws_s3_bucket.portfolio_is_bucket.id
rule {
object_ownership = "BucketOwnerPreferred"
}
}
# Désactiver le bloc d'accès public pour autoriser l'accès public au compartiment
resource "aws_s3_bucket_public_access_block" "portfolio_is_public_access_block" {
depends_on = [
aws_s3_bucket.portfolio_is_bucket
]
bucket = aws_s3_bucket.portfolio_is_bucket.id
# Définir tout sur false pour autoriser l'accès public au compartiment
block_public_acls = false # Bloquer les ACL publiques
block_public_policy = false # Bloquer les politiques de compartiment publiques
ignore_public_acls = false # Ignorer les ACL publiques
restrict_public_buckets = false # Bloquer l'accès public et inter-comptes aux compartiments
}
resource "aws_s3_bucket_policy" "portfolio-bucket_policy" {
depends_on = [
aws_s3_bucket.portfolio-bucket,
aws_s3_bucket_public_access_block.my_bucket_public_access_block
]
bucket = aws_s3_bucket.portfolio-bucket.id
policy = jsonencode({
Version = "2012-10-17",
Statement = [
{
Sid = "PublicReadGetObject",
Effect = "Allow",
Principal = "*",
Action = "s3:GetObject",
Resource = "${aws_s3_bucket.portfolio-bucket.arn}/*",
},
],
})
# Activer le compartiment pour héberger un site web statique
resource "aws_s3_bucket_website_configuration" "portfolio_is_website" {
depends_on = [
aws_s3_bucket.portfolio_is_bucket
]
bucket = aws_s3_bucket.portfolio_is_bucket.id
index_document {
suffix = "index.html"
}
error_document {
key = "index.html"
}
}
# Créer une identité d'accès à l'origine pour permettre à CloudFront d'atteindre le compartiment
resource "aws_cloudfront_origin_access_identity" "portfolio_is_origin_access_identity" {
comment = "Autoriser CloudFront à atteindre le compartiment"
}
# Créer une distribution CloudFront pour servir le site web statique
resource "aws_cloudfront_distribution" "portfolio_is_cloudfront" {
# Décrit l'origine des fichiers que vous souhaitez que CloudFront distribue
origin {
domain_name = aws_s3_bucket.portfolio_is_bucket.bucket_regional_domain_name
origin_id = aws_s3_bucket.portfolio_is_bucket.id # identifiant unique pour l'origine
s3_origin_config {
origin_access_identity = aws_cloudfront_origin_access_identity.portfolio_is_origin_access_identity.cloudfront_access_identity_path
}
}
enabled = true # activer la distribution cloud front directement après la création
is_ipv6_enabled = true # activer la prise en charge d'IPv6
default_root_object = "index.html" # objet racine par défaut à servir lorsqu'une requête est faite à la racine du domaine
default_cache_behavior {
allowed_methods = ["GET", "HEAD", "OPTIONS"] # Méthodes HTTP que CloudFront traite et transmet à l'origine
cached_methods = ["GET", "HEAD"] # Méthodes HTTP pour lesquelles CloudFront met en cache les réponses
target_origin_id = aws_s3_bucket.portfolio_is_bucket.id
# Transmettre la chaîne de requête à l'origine associée à ce comportement de cache
forwarded_values {
query_string = false
cookies {
forward = "none"
}
}
viewer_protocol_policy = "redirect-to-https" # Les requêtes HTTP et HTTPS sont automatiquement redirigées vers HTTPS
min_ttl = 0 # quantité minimale de temps pendant laquelle vous souhaitez que les objets restent dans un cache CloudFront
default_ttl = 3600 # quantité de temps par défaut (en secondes) pendant laquelle vous souhaitez que les objets restent dans les caches CloudFront
max_ttl = 86400 # quantité maximale de temps (en secondes) pendant laquelle vous souhaitez que les objets restent dans les caches CloudFront
}
# Autoriser CloudFront à utiliser le certificat par défaut pour SSL
viewer_certificate {
cloudfront_default_certificate = true
}
# Définir des restrictions sur la distribution géographique de votre contenu
restrictions {
geo_restriction {
restriction_type = "none"
}
}
tags = {
Name = "portfolio-cloudfront-nextjs-is"
}
}Ensuite, je restreins l’accès. Pour accéder aux fichiers du compartiment, nous devons passer par notre CDN CloudFront.
provider "aws" {
region = "eu-west-3"
}
# Créer un nouveau compartiment S3
resource "aws_s3_bucket" "portfolio_is_bucket" {
bucket = "portfolio-nextjs-is"
tags = {
Name = "portfolio-nextjs-is"
}
}---
title: "Activer les contrôles de propriété du compartiment pour appliquer les permissions du propriétaire du compartiment"
description: "Configuration Terraform pour activer les contrôles de propriété du compartiment, désactiver l'accès public, configurer la politique du compartiment et créer une distribution CloudFront."
lang: fr
---
# Activer les contrôles de propriété du compartiment pour appliquer les permissions du propriétaire du compartiment
resource "aws_s3_bucket_ownership_controls" "portfolio_is_ownership_controls" {
depends_on = [
aws_s3_bucket.portfolio_is_bucket
]
bucket = aws_s3_bucket.portfolio_is_bucket.id
rule {
object_ownership = "BucketOwnerPreferred"
}
}
# Désactiver le blocage de l'accès public pour autoriser l'accès public au compartiment
resource "aws_s3_bucket_public_access_block" "portfolio_is_public_access_block" {
depends_on = [
aws_s3_bucket.portfolio_is_bucket
]
bucket = aws_s3_bucket.portfolio_is_bucket.id
# Définir tout sur false pour autoriser l'accès public au compartiment
block_public_acls = true # Bloquer les ACL publiques
block_public_policy = true # Bloquer les politiques de compartiment publiques
ignore_public_acls = true # Ignorer les ACL publiques
restrict_public_buckets = true # Bloquer l'accès public et inter-comptes aux compartiments
}
################################
# Les ACL sont utilisées pour avoir un contrôle plus fin sur les objets dans le compartiment | Pas besoin pour l'instant
# # Définir la liste de contrôle d'accès (ACL) du compartiment sur public-read, autorisant l'accès en lecture public au compartiment
# resource "aws_s3_bucket_acl" "bucket_acl" {
# depends_on = [
# aws_s3_bucket_ownership_controls.bucket_ownership_controls,
# aws_s3_bucket_public_access_block.my_bucket_public_access_block
# ]
# bucket = aws_s3_bucket.portfolio-bucket.id
# acl = "public-read"
# }
################################
# Créer une politique de compartiment pour autoriser l'accès en lecture uniquement depuis CloudFront
resource "aws_s3_bucket_policy" "portfolio_is_bucket_policy" {
depends_on = [
aws_s3_bucket.portfolio_is_bucket,
aws_s3_bucket_public_access_block.my_bucket_public_access_block,
aws_cloudfront_origin_access_identity.origin_access_identity
]
bucket = aws_s3_bucket.portfolio_is_bucket.id
policy = jsonencode({
Version = "2012-10-17",
Statement = [
{
Sid = "PublicReadGetObject",
Effect = "Allow",
Principal = {
AWS = "${aws_cloudfront_origin_access_identity.origin_access_identity.iam_arn}" # L'ARN de l'identité d'accès à l'origine CloudFront
},
Action = "s3:GetObject",
Resource = "${aws_s3_bucket.portfolio_is_bucket.arn}/*",
},
],
})
}
################################
# Autoriser l'accès en lecture public au compartiment depuis n'importe quelle adresse IP | Nous ne voulons pas cela
# resource "aws_s3_bucket_policy" "portfolio-bucket_policy" {
# depends_on = [
# aws_s3_bucket.portfolio-bucket,
# aws_s3_bucket_public_access_block.my_bucket_public_access_block
# ]
# bucket = aws_s3_bucket.portfolio-bucket.id
# policy = jsonencode({
# Version = "2012-10-17",
# Statement = [
# {
# Sid = "PublicReadGetObject",
# Effect = "Allow",
# Principal = "*",
# Action = "s3:GetObject",
# Resource = "${aws_s3_bucket.portfolio-bucket.arn}/*",
# },
# ],
# })
# }
################################
# Activer le compartiment pour héberger un site web statique
resource "aws_s3_bucket_website_configuration" "portfolio_is_website" {
depends_on = [
aws_s3_bucket.portfolio_is_bucket
]
bucket = aws_s3_bucket.portfolio_is_bucket.id
index_document {
suffix = "index.html"
}
error_document {
key = "index.html"
}
}
# Créer une identité d'accès à l'origine pour permettre à CloudFront d'atteindre le compartiment
resource "aws_cloudfront_origin_access_identity" "portfolio_is_origin_access_identity" {
comment = "Permettre à CloudFront d'atteindre le compartiment"
}
# Créer une distribution CloudFront pour servir le site web statique
resource "aws_cloudfront_distribution" "portfolio_is_cloudfront" {
# Décrit l'origine des fichiers que vous souhaitez que CloudFront distribue
origin {
domain_name = aws_s3_bucket.portfolio_is_bucket.bucket_regional_domain_name
origin_id = aws_s3_bucket.portfolio_is_bucket.id # identifiant unique pour l'origine
s3_origin_config {
origin_access_identity = aws_cloudfront_origin_access_identity.portfolio_is_origin_access_identity.cloudfront_access_identity_path
}
}
enabled = true # activer la distribution cloud front directement après la création
is_ipv6_enabled = true # activer la prise en charge d'IPv6
default_root_object = "index.html" # objet racine par défaut à servir lorsqu'une requête est faite vers le domaine racine
default_cache_behavior {
allowed_methods = ["GET", "HEAD", "OPTIONS"] # Méthodes HTTP que CloudFront traite et transfère à l'origine
cached_methods = ["GET", "HEAD"] # Méthodes HTTP pour lesquelles CloudFront met en cache les réponses
target_origin_id = aws_s3_bucket.portfolio_is_bucket.id
# Transférer la chaîne de requête à l'origine associée à ce comportement de cache
forwarded_values {
query_string = false
cookies {
forward = "none"
}
}
viewer_protocol_policy = "redirect-to-https" # Les requêtes HTTP et HTTPS sont automatiquement redirigées vers HTTPS
min_ttl = 0 # quantité minimale de temps pendant laquelle vous souhaitez que les objets restent dans un cache CloudFront
default_ttl = 3600 # quantité de temps par défaut (en secondes) pendant laquelle vous souhaitez que les objets restent dans les caches CloudFront
max_ttl = 86400 # quantité maximale de temps (en secondes) pendant laquelle vous souhaitez que les objets restent dans les caches CloudFront
}
# Autoriser cloudfront à utiliser le certificat par défaut pour SSL
viewer_certificate {
cloudfront_default_certificate = true
}
# Définir des restrictions sur la distribution géographique de votre contenu
restrictions {
geo_restriction {
restriction_type = "none"
}
}
tags = {
Name = "portfolio-cloudfront-nextjs-is"
}
}Nous devons appliquer la configuration en utilisant Terraform. La création de CloudFront peut prendre un certain temps. Ensuite, nous devons simplement construire notre application next-js en utilisant :
npm run buildNous devons copier tout le contenu du dossier out créé vers notre compartiment.
Enfin, nous pouvons confirmer que seuls CloudFront peut accéder aux fichiers S3.
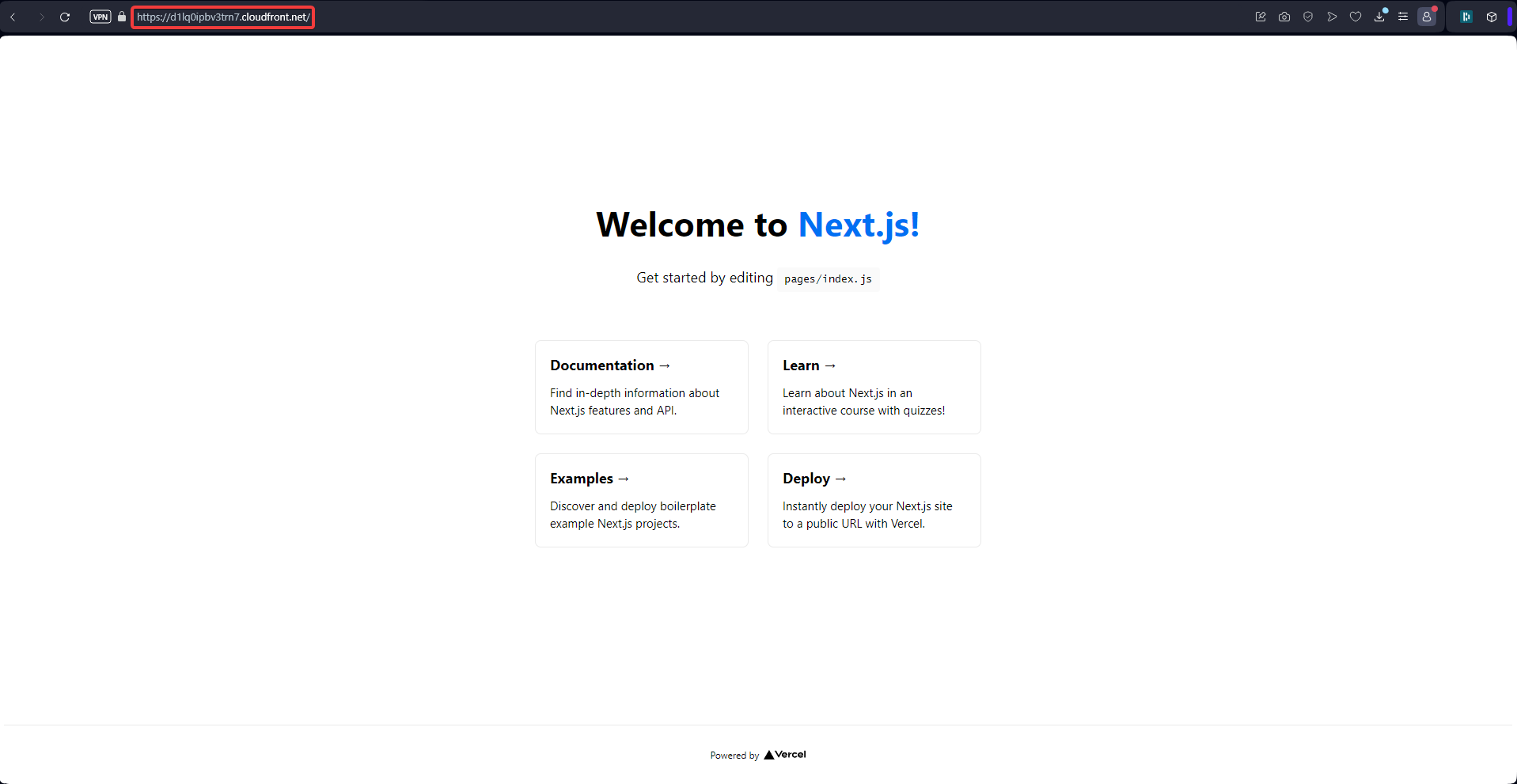
9 - Conclusion | Bonnes pratiques
Écrivez les noms entre guillemets, utilisez un trait de soulignement au lieu d’un tiret et n’incluez pas le type de ressource dans le nom de la ressource :
resource "aws_s3_bucket" "portfolio" {}