
Améliorer mes compétences Cloud - Semaine 6 - AWS Avancé
Cette semaine, j’ai pu beaucoup apprendre sur les services principaux d’AWS comme EC2, IAM, et S3. J’ai aussi utilisé l’Infrastructure as Code (IaC) pour la première fois afin de déployer des ressources dans le cloud. L’IaC a été un véritable tournant pour moi, surtout par rapport à l’approche plus manuelle ClickOps, où je me sentais souvent dépassé en essayant de me souvenir de ce que j’avais déployé et où se trouvaient mes ressources. Il était facile de perdre le fil ou de manquer quelque chose d’important. Avec l’IaC, tout est clairement défini dans le code, ce qui facilite grandement le suivi, la gestion et la mise à jour des ressources.
Pour mettre en pratique ce que j’ai appris, j’ai déployé une instance EC2 en utilisant CloudFormation pour tester et renforcer ma compréhension de ces concepts.
1 - IaC
2 - AWS CloudFormation
3 - AWS Compute
4 - NOTES/IAM
5 - EC2 Storage
6 - ELB (Elastic Load Balancing)
7 - S3
8 - RDS (Relational Database Service)
1 - IaC
Qu’est-ce que l’IaC ?
Infrastructure as Code (IaC) est une pratique qui permet aux développeurs et aux équipes d’opérations de gérer et de provisionner l’infrastructure par le biais du code plutôt que par des processus manuels. Au lieu d’utiliser une interface graphique comme le portail Web AWS (ClickOps) ou l’interface de ligne de commande (CLI) pour configurer les ressources, l’IaC vous permet de définir votre infrastructure dans le code, qui peut être stocké dans le contrôle de version, partagé entre les équipes et déployé automatiquement.
Il existe de nombreux outils IaC tels que : AWS CloudFormation, Terraform, Pulumi…
Principaux avantages de l’IaC
Contrôle de version
En utilisant l’IaC, les définitions d’infrastructure peuvent être stockées dans des systèmes de contrôle de version (comme Git). Cela permet aux équipes de suivre les changements au fil du temps, de collaborer plus efficacement et de revenir aux versions précédentes en cas de problèmes.
Collaboration et automatisation
L’IaC facilite la collaboration entre les équipes, permettant à plusieurs développeurs de travailler simultanément sur les changements d’infrastructure. De plus, les outils d’automatisation peuvent s’intégrer à l’IaC pour déployer automatiquement l’infrastructure en fonction du code, réduisant ainsi le besoin d’intervention manuelle.
- Intégration CI/CD: Les changements d’infrastructure peuvent être appliqués automatiquement dans le cadre d’un pipeline d’intégration continue/déploiement continu (CI/CD), ce qui simplifie le processus de développement et de déploiement.
Cohérence et fiabilité
L’IaC garantit que les environnements sont cohérents entre le développement, les tests et la production. Puisque l’infrastructure est définie dans le code, la même infrastructure peut être déployée dans plusieurs environnements sans erreur humaine.
- Exemple: Que vous déployiez dans un environnement de développement ou un environnement de production, l’IaC garantit que chaque environnement est configuré exactement de la même manière, ce qui réduit les incohérences et les problèmes potentiels causés par les configurations manuelles.
Configuration et mise à l’échelle plus rapides
L’IaC permet de configurer rapidement l’infrastructure. En quelques lignes de code, des environnements entiers peuvent être créés, répliqués ou mis à l’échelle automatiquement. Ceci est particulièrement utile pour la mise à l’échelle automatique ou le déploiement d’une infrastructure complexe avec plusieurs services.
- Automatisation: Au lieu de configurer manuellement des serveurs, des bases de données et des réseaux un par un, vous pouvez les définir dans l’IaC et les déployer avec une seule commande.
Intégration avec DevOps
L’IaC s’intègre de manière transparente aux pratiques DevOps, ce qui facilite la gestion du code et de l’infrastructure de manière unifiée. Il permet de tester et d’examiner les changements d’infrastructure comme le code logiciel, alignant la gestion de l’infrastructure sur les principes agiles de développement et de livraison continus.
2 - AWS CloudFormation
Définition
AWS CloudFormation est la solution native Infrastructure as Code (IaC) d’Amazon Web Services. Elle vous permet de définir, de provisionner et de gérer les ressources AWS à l’aide de code, offrant ainsi une manière déclarative de configurer l’infrastructure. En définissant les ressources dans un modèle CloudFormation, vous pouvez automatiser le processus de déploiement de l’infrastructure dans un environnement AWS sans configurer manuellement chaque service via la console AWS ou l’interface de ligne de commande (CLI).
Essentiellement, CloudFormation agit comme un plan détaillé pour votre infrastructure, avec l’ensemble de l’architecture définie dans un seul fichier en utilisant JSON ou YAML.
Concepts clés
Modèles
Un modèle est le fichier qui contient la configuration des ressources AWS que vous souhaitez créer. Le modèle spécifie quelles ressources sont nécessaires, comment elles doivent être configurées et les relations entre elles. Les modèles sont écrits en JSON ou YAML, et ils servent de base à la création et à la gestion des ressources dans AWS.
- Structure du modèle: Chaque modèle contient plusieurs sections, notamment :
- Ressources: Le cœur du modèle, spécifiant les ressources AWS à créer (par exemple, instances EC2, compartiments S3, VPC).
- Sorties (facultatif) : Valeurs de retour de la pile, telles que les ID de ressources ou les URL.
- Paramètres (facultatif) : Permettent des valeurs d’entrée pour personnaliser le modèle au moment de l’exécution.
Piles
Une pile est un ensemble de ressources AWS définies par un modèle CloudFormation. Les piles vous permettent de regrouper les ressources et de les gérer comme une seule unité. Vous pouvez créer, mettre à jour et supprimer des piles entières à la fois, ce qui simplifie le processus de gestion de plusieurs ressources.
Au lieu de gérer séparément les services AWS individuels (comme EC2, S3 et RDS), vous pouvez tous les définir dans une seule pile et les créer, les mettre à jour ou les supprimer en une seule action.
La suppression d’une pile supprimera automatiquement toutes les ressources qui lui sont associées, ce qui facilitera grandement la gestion des ressources et garantira qu’il ne reste rien.
Ensembles de modifications
Les ensembles de modifications vous permettent de prévisualiser l’impact des modifications apportées à votre infrastructure avant qu’elles ne soient appliquées. Cette fonctionnalité est utile lors de la mise à jour des piles, car elle offre la possibilité d’examiner les modifications potentielles et d’éviter les conséquences imprévues, telles que la suppression de ressources ou les erreurs de configuration.
Avant de mettre à jour une pile existante pour ajouter une nouvelle instance EC2, les ensembles de modifications vous permettent de voir comment la mise à jour affectera l’infrastructure actuelle.
Comment fonctionne AWS CloudFormation ?
L’utilisation d’AWS CloudFormation implique de définir votre infrastructure à l’aide de code (modèles), puis de déployer cette infrastructure sous forme de piles. Le flux de travail suit généralement les étapes suivantes :
Il est possible de trouver les propriétés et le nom des types en utilisant la Documentation d’AWS CloudFormation. Voici un exemple pour les Sous-réseaux.
Étape 1 - Créer un modèle
La première étape de l’utilisation de CloudFormation consiste à définir votre infrastructure dans un modèle. Voici un exemple de modèle CloudFormation simple écrit en YAML pour créer un compartiment S3 :
# CloudFormationTemplateVersion
# Description
AWSTemplateFormatVersion: "2010-09-09" # Version prise en charge du modèle
Description: "Modèle CloudFormation pour créer un compartiment S3" # Ce que fait ce modèle
Resources: # Ressources à créer
S3Bucket: # Nom logique de la ressource doit être unique dans le modèle
Type: "AWS::S3::Bucket"
Properties:
BucketName: "my-issam-s3-bucket-yaml" # nom unique globalement en minuscules dans les compartiments AWS S3
Étape 2 - Créer une pile
Une fois le modèle prêt, vous pouvez déployer l’infrastructure en créant une pile. Cette pile provisionnera toutes les ressources spécifiées dans le modèle. Vous pouvez créer une pile en utilisant l’AWS CLI :
aws cloudformation create-stack --stack-name [name-of-the-stack] --template-body file://[name-of-the-file]Cette commande prendra le modèle et créera les ressources définies dans la pile CloudFormation.
Étape 3 - Mettre à jour la pile
Lorsque vous devez modifier votre infrastructure, vous pouvez modifier le modèle et mettre à jour la pile :
aws cloudformation update-stack --stack-name [name-of-the-stack] --template-body file://[name-of-the-file]Cela met à jour les ressources de la pile pour refléter les modifications apportées au modèle.
Étape 4 - Vérifier l’état de la pile
Après avoir créé ou mis à jour une pile, vous pouvez vérifier son état à l’aide de la commande suivante :
aws cloudformation describes-stacks --stack-name [name-of-the-stack]Cela affichera l’état actuel de la pile, tel que CREATE_COMPLETE ou UPDATE_IN_PROGRESS.
Étape 5 - Supprimer la pile
Pour supprimer toutes les ressources associées à une pile, vous pouvez utiliser la commande suivante :
aws cloudformation delete-stack --stack-name [name-of-the-stack]Projet - Déployer un VPC
Déploiement
L’objectif de ce projet était de redéployer une architecture VPC complète en utilisant AWS CloudFormation. L’objectif était de créer un hôte bastion pour accéder en toute sécurité à une instance EC2 dans un sous-réseau privé et de pinguer une autre instance EC2 dans un sous-réseau privé différent situé dans une zone de disponibilité (AZ) différente. Cette configuration avait été précédemment effectuée à l’aide de ClickOps (configuration manuelle via la console AWS), mais maintenant, l’objectif est de l’automatiser à l’aide de CloudFormation pour plus d’efficacité et de reproductibilité (Version ClickOps).
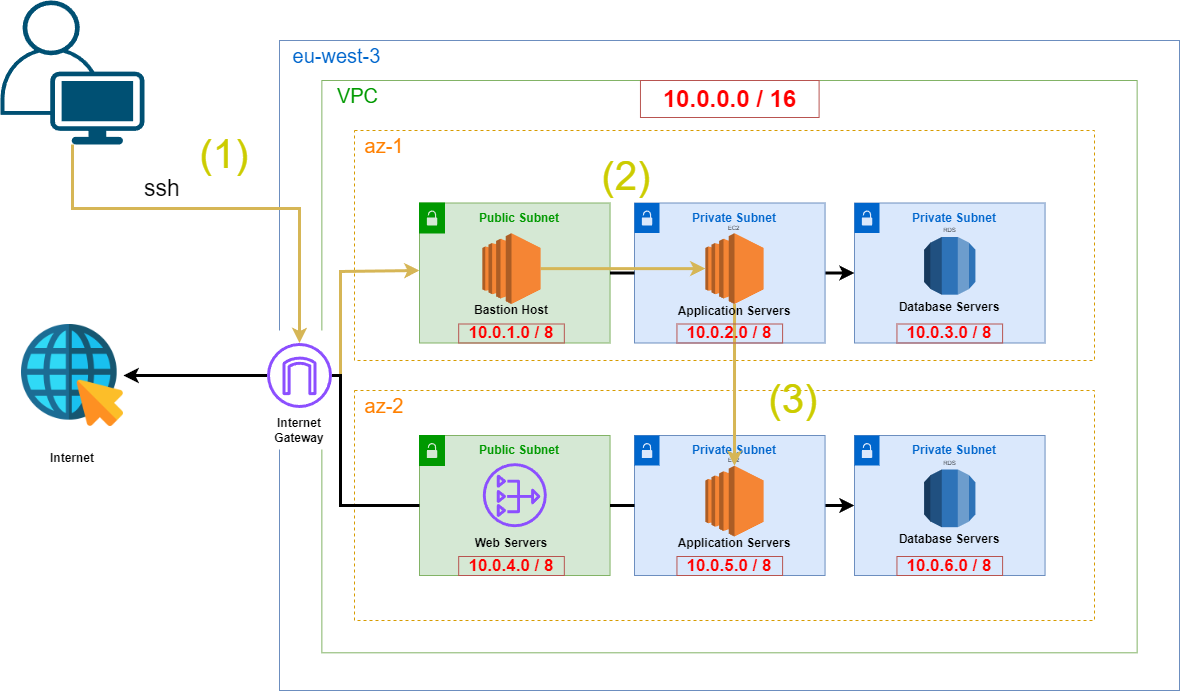
Vous pouvez trouver le code complet du modèle CloudFormation ici.
Par exemple, voici comment déployer un VPC :
AWSTemplateFormatVersion: "2010-09-09"
Description: "Modèle CloudFormation pour créer un VPC"
Resources:
MyVPC:
Type: "AWS::EC2::VPC"
Properties:
CidrBlock: "172.16.0.0/16" # Plage d'adresses IP pour le VPC
EnableDnsSupport: "true" # Autoriser les ressources du vpc à communiquer avec les serveurs dns amazon
EnableDnsHostnames: "true" # Autoriser les ressources du vpc à recevoir des noms d'hôte dns
Tags:
- Key: Name
Value: MyVPCVoici comment déployer une instance ec2 :
# Bastion Host EC2
BastionHost:
Type: AWS::EC2::Instance
Properties:
InstanceType: t2.micro # Type d'instance de notre instance EC2
ImageId: ami-0cb0b94275d5b4aec # ID d'image machine Amazon, un modèle qui contient la configuration logicielle (OS). Un plan pour notre instance EC2. Une image qui fournit le logiciel requis pour configurer et démarrer une instance Amazon EC2
KeyName: bastion # Nom de la paire de clés pour se connecter à l'instance
SubnetId: !Ref PublicSubnet1A
SecurityGroupIds:
- !Ref BastionSG
Tags:
- Key: Name
Value: BastionHostNous devons obtenir le keyname qui fait référence à une paire de clés que nous avons précédemment créée et téléchargée. Il est nécessaire pour ssh à nos instances ec2.
Vous pouvez trouver l’ID AMI approprié pour votre instance en accédant au tableau de bord EC2 et en sélectionnant l’image machine Amazon pertinente :

Tester la configuration
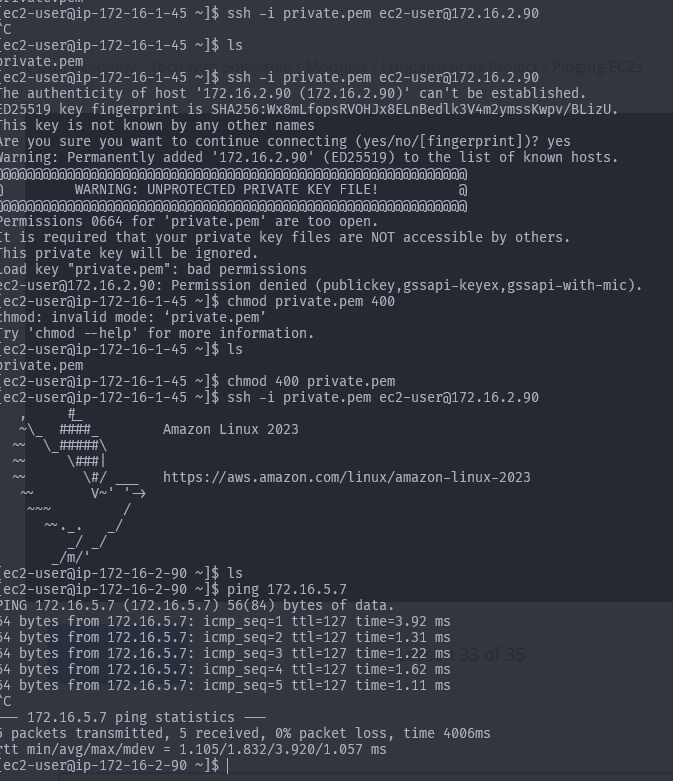
Une fois le VPC et l’hôte bastion déployés, l’étape suivante consiste à tester si l’architecture fonctionne comme prévu en accédant aux instances privées via l’hôte bastion.
- Accéder à l’hôte bastion via SSH
ssh -i bastion.pem ec2-user@[adresse-ip-publique-de-l-instance-ec2]- Copier notre paire de clés pour utiliser ssh
scp -i bastion.pem bastion.pem ec2-user@15.237.184.39:~/private.pem # doit être lancé depuis notre terminal pc et non ec2- Mise à jour des autorisations de fichier Si nous ne pouvons pas utiliser le fichier private.pem dans un environnement linux, nous devons mettre à jour les autorisations :
chmod 400 private.pemVoici ce que nous obtenons :
3 - AWS Compute
Qu’est-ce qu’AWS Compute ?
Le calcul est la puissance que l’ordinateur utilise pour effectuer des tâches. Dans l’environnement cloud, ce sont les serveurs ou les machines virtuelles qui sont l’épine dorsale des systèmes cloud. AWS compute est le terme utilisé pour décrire l’utilisation des ordinateurs aws pour exécuter des sites Web ou des applications.
Services de calcul
Il existe 4 services de calcul AWS populaires :
EC2 : L’un des services de calcul les plus utilisés dans AWS. Il fournit une capacité de calcul redimensionnable, sécurisée dans le cloud, permettant aux utilisateurs d’exécuter des serveurs virtuels, ou instances, à la demande.
Lambda : Service de calcul sans serveur qui permet d’exécuter notre code sans gérer de serveurs. AWS gérera la maintenance, la mise à l’échelle et la journalisation. Les Lambda sont basées sur des événements, ce qui signifie qu’elles peuvent répondre aux changements de données dans un service AWS ou aux requêtes HTTP entrantes.
Beanstalk : AWS Elastic Beanstalk simplifie le processus de déploiement, de gestion et de mise à l’échelle des applications dans le cloud. Beanstalk gère automatiquement le provisionnement de l’infrastructure, l’équilibrage de la charge et la mise à l’échelle, laissant les développeurs libres de se concentrer sur le codage.
ECS : Amazon ECS est un service d’orchestration de conteneurs qui vous permet d’exécuter et de gérer des conteneurs à grande échelle. Les conteneurs sont des unités légères et portables qui regroupent le code d’une application avec ses dépendances, ce qui facilite le déploiement et l’exécution dans n’importe quel environnement.
Projet - Déployer une instance EC2
Voici comment déployer une instance ec2 :
# Bastion Host EC2
BastionHost:
Type: AWS::EC2::Instance
Properties:
InstanceType: t2.micro # Type d'instance de notre instance EC2
ImageId: ami-0cb0b94275d5b4aec # ID d'image machine Amazon, un modèle qui contient la configuration logicielle (OS). Un plan pour notre instance EC2. Une image qui fournit le logiciel requis pour configurer et démarrer une instance Amazon EC2
KeyName: bastion # Nom de la paire de clés pour se connecter à l'instance
SubnetId: !Ref PublicSubnet1A
SecurityGroupIds:
- !Ref BastionSG
Tags:
- Key: Name
Value: BastionHost4 - IAM (Identity Access Management)
Qu’est-ce que l’IAM ?
AWS Identity and Access Management (IAM) est un service qui permet un contrôle sécurisé de l’accès aux services et aux ressources AWS. Il vous permet de gérer les utilisateurs, les groupes, les rôles et les politiques pour définir qui a accès à quelles ressources et dans quelles conditions.
Utilisateur IAM
Un utilisateur IAM peut représenter un humain (comme un utilisateur individuel), une organisation ou une application qui interagit avec les services AWS. Chaque utilisateur IAM possède un ensemble unique d’informations d’identification (combinaison de nom d’utilisateur + mot de passe + MFA) utilisé pour l’authentification et pour effectuer des actions spécifiques sur les ressources AWS.
Groupes IAM
Un groupe IAM est une collection d’utilisateurs qui vous permet de gérer les autorisations pour plusieurs utilisateurs simultanément. Au lieu d’attacher des politiques à chaque utilisateur individuellement, vous pouvez attacher une politique à un groupe et tous les utilisateurs du groupe héritent de ces autorisations.
Politiques IAM
Les politiques IAM sont des documents JSON qui définissent quelles actions sont autorisées ou refusées pour des ressources spécifiques. Les politiques peuvent être appliquées aux utilisateurs, aux groupes et aux rôles pour contrôler l’accès aux ressources AWS.
Éléments clés d’une politique :
- Actions: Les actions spécifiques autorisées ou refusées (par exemple,
s3:PutObject,ec2:StartInstances). - Ressources: Les ressources AWS spécifiques auxquelles la politique s’applique (par exemple, un compartiment S3 spécifique, une instance EC2).
- Conditions: Restrictions facultatives en vertu desquelles la politique s’applique (par exemple, n’autoriser l’accès qu’à partir d’une adresse IP spécifique ou pendant certaines heures).
Types de politiques :
-
Politiques gérées
- Politiques gérées par AWS: Politiques pré-construites créées par AWS pour des cas d’utilisation courants, comme un accès complet à S3 ou EC2. AWS gère et met à jour ces politiques, garantissant qu’elles restent sécurisées et à jour.
- Exemple:
AdministratorAccess,AmazonS3ReadOnlyAccess.
-
Politiques en ligne
- Les politiques en ligne sont des politiques qui sont attachées directement à un seul utilisateur, groupe ou rôle et ne sont pas réutilisables ailleurs. Ces politiques sont spécifiques à une entité particulière et ne peuvent pas être réutilisées par d’autres utilisateurs ou groupes.
-
Politiques gérées par le client
- Les politiques gérées par le client sont des politiques que vous créez et gérez vous-même. Ces politiques peuvent être attachées à plusieurs utilisateurs, rôles ou groupes, ce qui les rend beaucoup plus polyvalentes et réutilisables.
Rôles IAM
Un rôle IAM est une entité IAM qui peut être temporairement assumée par des utilisateurs, des applications ou des services AWS de confiance. Les rôles vous permettent de déléguer des autorisations aux ressources sans attribuer d’informations d’identification d’accès à long terme, telles que des clés d’accès.
- Autorisations temporaires : Les rôles accordent des autorisations temporaires pour l’exécution de tâches spécifiques. Une fois le rôle assumé, l’entité obtient les autorisations attribuées au rôle pendant une durée limitée.
- Pas de clés d’accès : Les rôles ne nécessitent pas de clés d’accès permanentes, ce qui les rend plus sûrs pour la délégation d’autorisations.
Bonnes pratiques
Principe du moindre privilège
Le principe du moindre privilège est une bonne pratique de sécurité qui stipule que les utilisateurs ne doivent avoir que les autorisations minimales nécessaires pour accomplir leurs tâches. Cela réduit le risque d’utilisation involontaire ou malveillante des ressources.
Groupes IAM
Au lieu de gérer les autorisations pour les utilisateurs individuels, il est recommandé d’organiser les utilisateurs en groupes. Cela simplifie la gestion en appliquant les autorisations au niveau du groupe plutôt qu’au niveau de l’utilisateur. Les groupes vous permettent de gérer l’accès pour plusieurs utilisateurs simultanément.
Rotation et réémission des informations d’identification
Pour minimiser le risque de compromission des informations d’identification, faites régulièrement pivoter les mots de passe et les clés d’accès.
- Politique de mot de passe : Par exemple, appliquez une modification de mot de passe tous les 60 jours.
- Surveillance de l’activité des utilisateurs : AWS fournit des journaux et des métriques pour surveiller l’activité des utilisateurs, tels que la dernière connexion et la dernière utilisation des clés d’accès. Examinez-les régulièrement pour identifier les utilisateurs inactifs ou les activités anormales.
Utiliser des politiques gérées par le client
Si vous avez besoin de politiques personnalisées, utilisez des politiques gérées par le client plutôt que des politiques en ligne, car elles sont plus faciles à gérer, à réutiliser et à auditer.
Projet - Utilisation d’IAM avec CloudFormation
Vous pouvez trouver le modèle complet ici :
- Création d’un utilisateur IAM avec CloudFormation
AWSTemplateFormatVersion: 2010-09-09
Description: "Modèle IAM CloudFormation"
Resources:
MyIAMUser:
Type: AWS::IAM::User
Properties:
UserName: IssamCFN
ManagedPolicyArns:
- arn:aws:iam::aws:policy/AdministratorAccess #Politique d'accès administrateur - Niveau d'accès élevé- Création de la pile CloudFormation
aws cloudformation create-stack --stack-name my-iam-stack --template-body file://iam.yaml- Débogage
Une erreur s'est produite (InsufficientCapabilitiesException) lors de l'appel de l'opération CreateStack : Nécessite des capacités : [CAPABILITY_NAMED_IAM]eCette erreur se produit car la création de ressources IAM (telles que des utilisateurs, des rôles ou des politiques) nécessite une reconnaissance explicite de l’utilisateur pour s’assurer qu’il comprend les implications en matière de sécurité.
Nous devons donc utiliser ceci dans la commande :
aws cloudformation create-stack --stack-name my-iam-stack --template-body file://iam.yaml --capabilities CAPABILITY_NAMED_IAMBien que l’utilisateur IAM soit créé avec succès avec des privilèges d’administrateur, notez que cet utilisateur n’a pas accès à la console de gestion AWS. En effet, nous n’avons pas spécifié de mot de passe dans le modèle CloudFormation.
En général, les mots de passe et autres informations sensibles ne sont pas codés en dur dans l’Infrastructure as Code (IaC) pour des raisons de sécurité. Au lieu de cela, les bonnes pratiques dictent que ces informations d’identification doivent être gérées via :
- AWS Secrets Manager : Pour stocker et gérer en toute sécurité les informations sensibles telles que les mots de passe ou les clés API.
- Politiques IAM : Qui appliquent l’MFA (authentification multi-facteurs) pour l’accès à la console.
5 - Stockage EC2
Il existe 2 types de stockage au sein des instances EC2 :
Amazon EBS
Amazon Elastic Block Store est un disque dur externe que nous pouvons connecter à EC2. Si nous terminons l’instance associée à l’EBS, nos données restent intactes.
Types de volumes EBS :
| Types | Nom | Utilisation |
|---|---|---|
| SSD à usage général | gp2 | Volumes de démarrage, environnements de développement et de test, applications interactives à faible latence |
| SSD IOPS provisionnés | io1 | Charges de travail gourmandes en E/S ==(Grandes bases de données et applications critiques)== |
| HDD optimisé pour le débit | st1 | Charges de travail gourmandes en débit ==(Big Data, entrepôts de données, traitement des journaux)== |
| HDD froid | sc1 | Charges de travail moins fréquemment consultées ==(Sauvegardes et archives)== |
Pour choisir un type de volume, nous devons prendre en compte :
- Exigences de performance
- Besoins de durabilité
- Contraintes budgétaires
Stockage d’instance
Il s’agit d’un stockage temporaire qui permet un accès rapide aux données. Si nous terminons l’instance associée à l’EBS, nos données seront perdues.
6 - ELB (Elastic Load Balancing)
Elastic Load Balancing (ELB) est un service conçu pour distribuer automatiquement le trafic entrant sur plusieurs cibles telles que des instances EC2, des conteneurs Docker ou des adresses IP.
Il permet de distribuer le trafic entre différentes instances ec2 dans différentes AZ. Il augmente la tolérance aux pannes de notre système.
Types d’équilibreurs de charge Elastic Load Balancers
Nous choisissons le bon type d’équilibreur de charge en fonction de :
- Type de trafic
- Performance
- Architecture de l’application
ALB (Application Load Balancer)
Application Load Balancer (ALB) est optimisé pour le trafic HTTP/HTTPS et est couramment utilisé dans les applications web modernes. Il fonctionne au niveau 7 (la couche application), ce qui permet un routage avancé basé sur le contenu de la requête.
Fonctionnalités :
- Routage basé sur le chemin : Achemine le trafic en fonction des chemins URL (par exemple,
/imagesvers un service,/vidéosvers un autre). - Routage basé sur l’hôte : Achemine le trafic en fonction du nom de domaine (par exemple,
api.example.comvers un service différent dewww.example.com). - Routage vers plusieurs cibles : Peut acheminer les requêtes vers différents services, conteneurs ou équilibreurs de charge en fonction de règles définies.
Idéal pour :
- Systèmes de gestion de contenu
- Architecture de microservices
- Applications basées sur des conteneurs (par exemple, Docker, Kubernetes)
Fonctionnalités avancées : Des règles de routage précises vous permettent de prendre des décisions de routage en fonction du contenu de la requête.
NLB (Network Load Balancer)
Network Load Balancer (NLB) est conçu pour le trafic TCP et fonctionne au niveau 4 (la couche transport). Il est conçu pour gérer des exigences de performance extrêmes, capable de gérer des millions de requêtes par seconde avec une latence ultra-faible.
Fonctionnalités :
- Faible latence : Idéal pour les applications nécessitant une latence de l’ordre de la milliseconde.
- Équilibrage de charge au niveau de la connexion : Achemine les connexions en fonction des données du protocole IP.
Idéal pour :
- Trafic TCP, UDP et TLS
- Serveurs web nécessitant un débit élevé
- Serveurs de cache et bases de données nécessitant un accès rapide et cohérent
Cas d’utilisation :
- Applications hautes performances telles que les jeux en temps réel, le streaming vidéo et les serveurs web à grande échelle.
Auto Scaling
Auto Scaling est un service AWS conçu pour ajuster automatiquement le nombre d’instances EC2 en réponse aux changements de la demande ou de l’utilisation des ressources. En augmentant ou en diminuant dynamiquement le nombre d’instances, Auto Scaling garantit que les applications maintiennent une haute disponibilité et une rentabilité.
Avantages d’Auto Scaling :
- Rentabilité : Réduit automatiquement l’échelle pendant les périodes de faible demande, ce qui permet d’économiser des coûts.
- Tolérance aux pannes améliorée : Auto Scaling peut remplacer les instances défaillantes et maintenir le nombre souhaité d’instances saines.
- Gestion transparente de la charge : Ajoute automatiquement plus d’instances pour gérer l’augmentation du trafic, garantissant des performances élevées même pendant les périodes de pointe.
Composants
Groupes Auto Scaling
Une collection d’instances EC2 qui partagent des caractéristiques similaires et sont traitées comme un regroupement logique pour la mise à l’échelle et la gestion.
Nous définissons un minimum et un maximum d’instances dans le groupe, ce qui permet à AWS de les mettre à l’échelle.
Configurations de lancement ==(Obsolète)==
Il s’agit d’une méthode obsolète pour définir les paramètres des nouvelles instances EC2 lancées dans un groupe Auto Scaling. Il comprend des paramètres tels que :
- Type d’instance
- ID AMI
- Paire de clés
- Groupes de sécurité
- Stockage par blocs associé
Modèle de lancement
Il s’agit de la version améliorée de la configuration de lancement, offrant plus de flexibilité et de fonctionnalités. Les modèles de lancement permettent plusieurs versions et la possibilité de configurer différents types d’instances ou paramètres sous le même ID de modèle.
Politiques de mise à l’échelle
Les politiques de mise à l’échelle définissent comment le groupe Auto Scaling doit ajuster le nombre d’instances en fonction de conditions ou de métriques spécifiques, telles que l’utilisation du processeur ou des métriques personnalisées.
Différents types de politiques :
- Mise à l’échelle du suivi des cibles : Ajuster le nombre d’instances automatiquement pour maintenir une valeur cible pour une métrique spécifique ==par exemple, maintenir l’utilisation moyenne du processeur à 50%==
- Mise à l’échelle par étapes : Augmenter ou diminuer le nombre d’instances en se basant sur des ajustements d’échelle en fonction de la taille du dépassement de l’alarme. ==Par exemple, si l’utilisation du processeur est supérieure à 60 %, ajoutez une instance.==
- Mise à l’échelle planifiée : Augmenter ou diminuer les instances à des points temporels planifiés. Il est approprié pour les changements de charge prévisibles. ==Par exemple, à 9 heures, ajoutez 5 instances pour gérer les heures de pointe
Combinaison d’Auto Scaling et d’ELB
En combinant Auto Scaling avec Elastic Load Balancing (ELB), vous vous assurez que le trafic est réparti uniformément sur toutes les instances EC2 du groupe Auto Scaling. Cela améliore non seulement les performances, mais augmente également la disponibilité de votre application. À mesure que le trafic augmente, Auto Scaling ajoute de nouvelles instances, et ELB commence automatiquement à distribuer le trafic vers ces instances.
- Tolérance aux pannes améliorée : Si une instance tombe en panne, ELB redirige automatiquement le trafic vers des instances saines, tandis qu’Auto Scaling remplace l’instance défaillante.
- Performances améliorées : La mise à l’échelle en fonction de la demande garantit que votre application reste réactive et efficace pendant les périodes de pointe.
Projet - Créer un ALB avec CloudFormation
Nous allons créer un ALB et un groupe Auto Scaling. Le schéma ci-dessous montre ce que nous voulons réaliser :
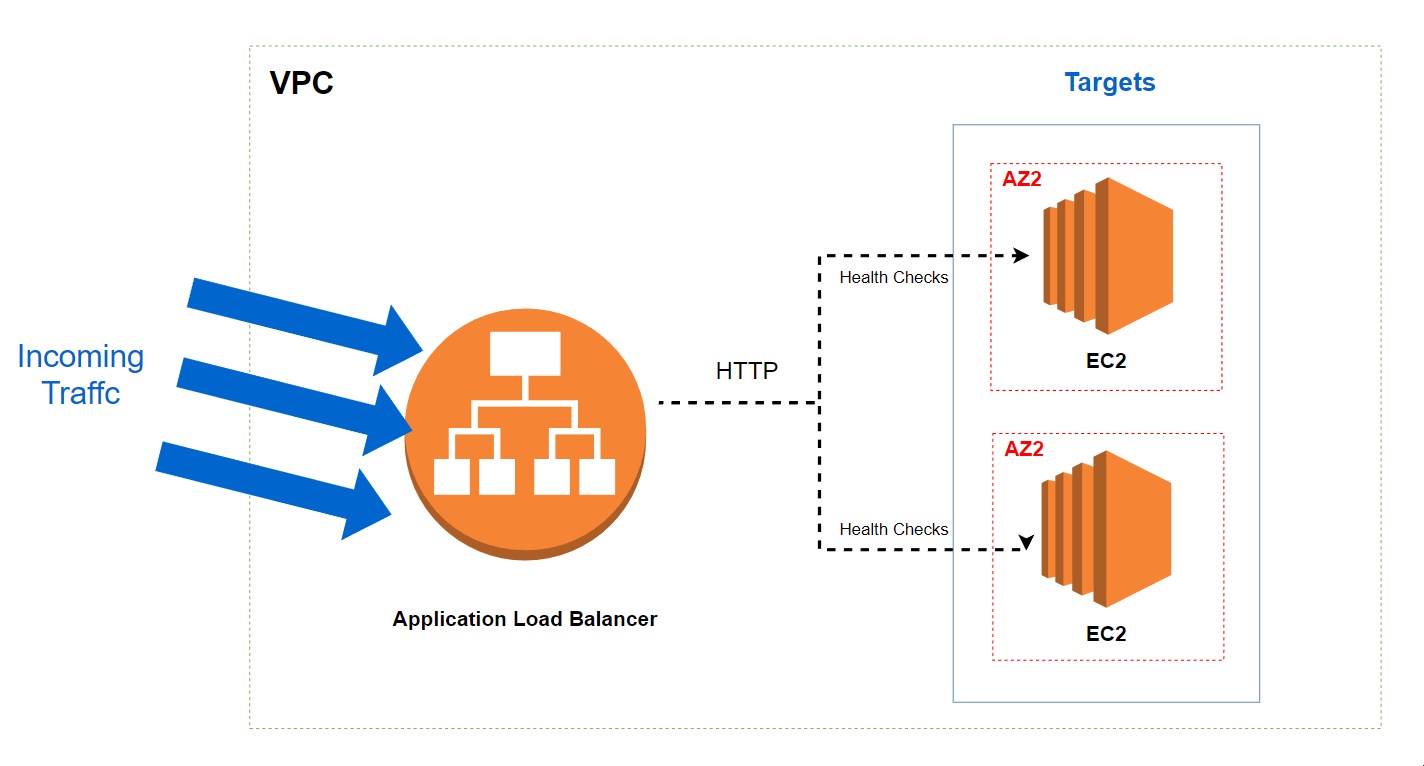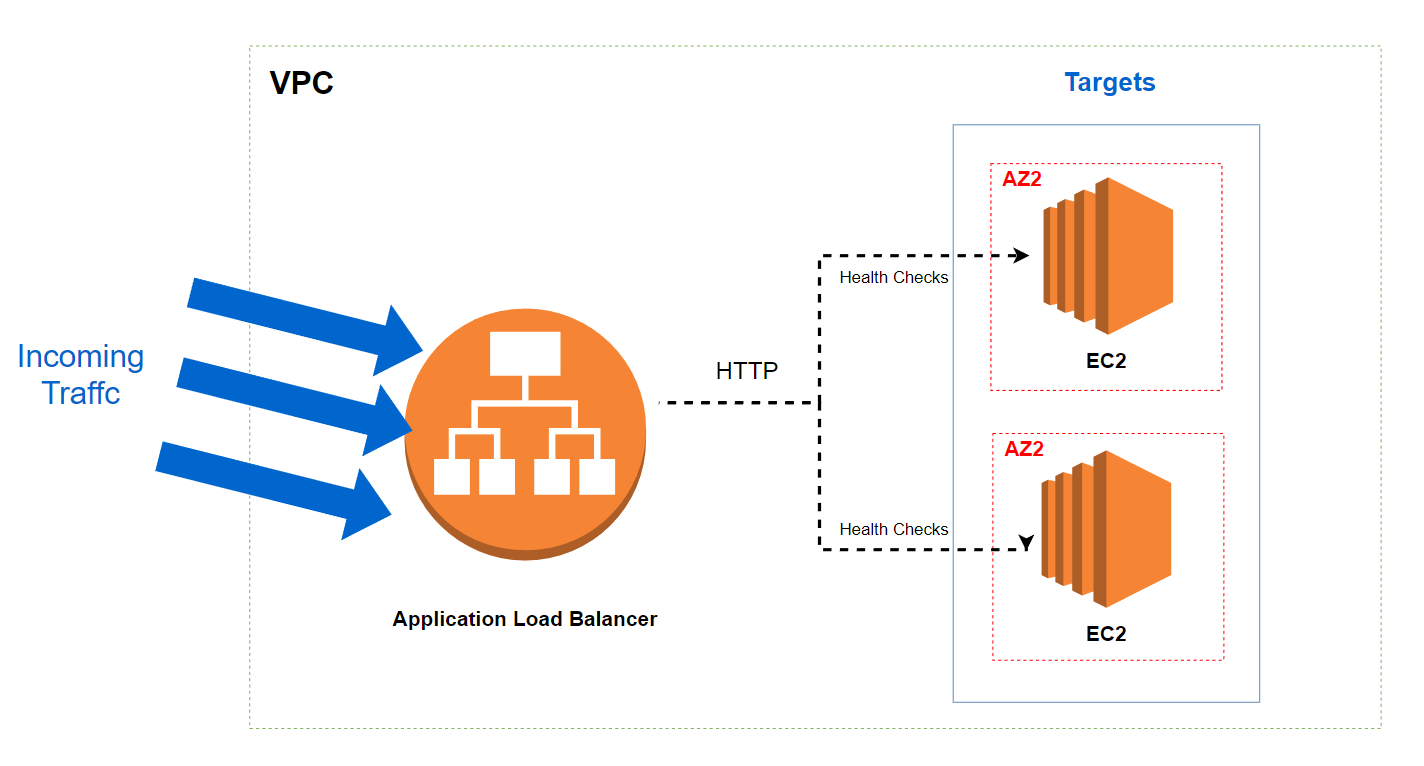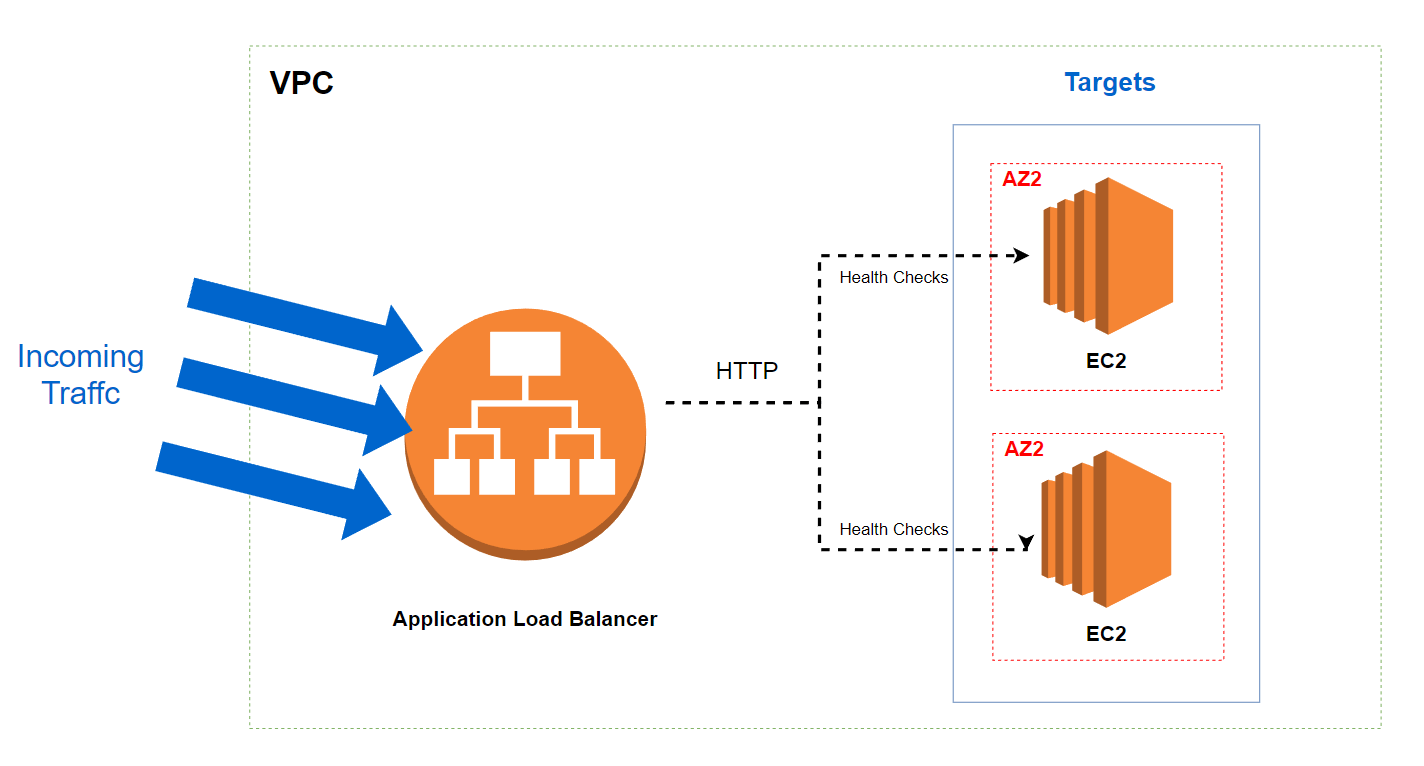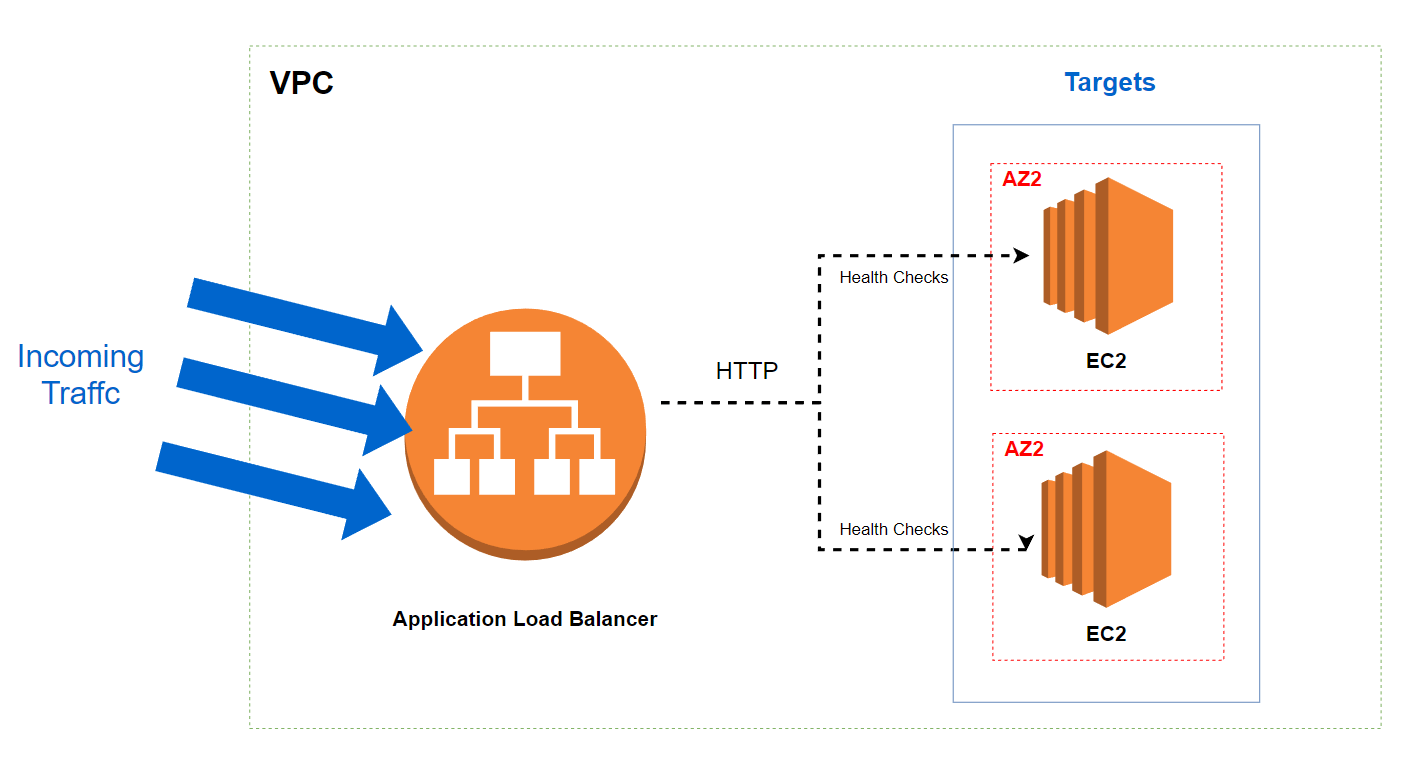
Vous pouvez trouver le modèle complet ici.
Le modèle pour créer un Load Balancer :
# Application Load Balancer. Nous devons créer un Listener et un groupe cible.
MyLoadBalancer:
Type: AWS::ElasticLoadBalancingV2::LoadBalancer
Properties:
Name: MyLoadBalancer
Subnets:
- !Ref PublicSubnet1A
- !Ref PublicSubnet2B
SecurityGroups:
- !Ref WebServerSecurityGroupCeci est notre LoadBalancer dans la console AWS :
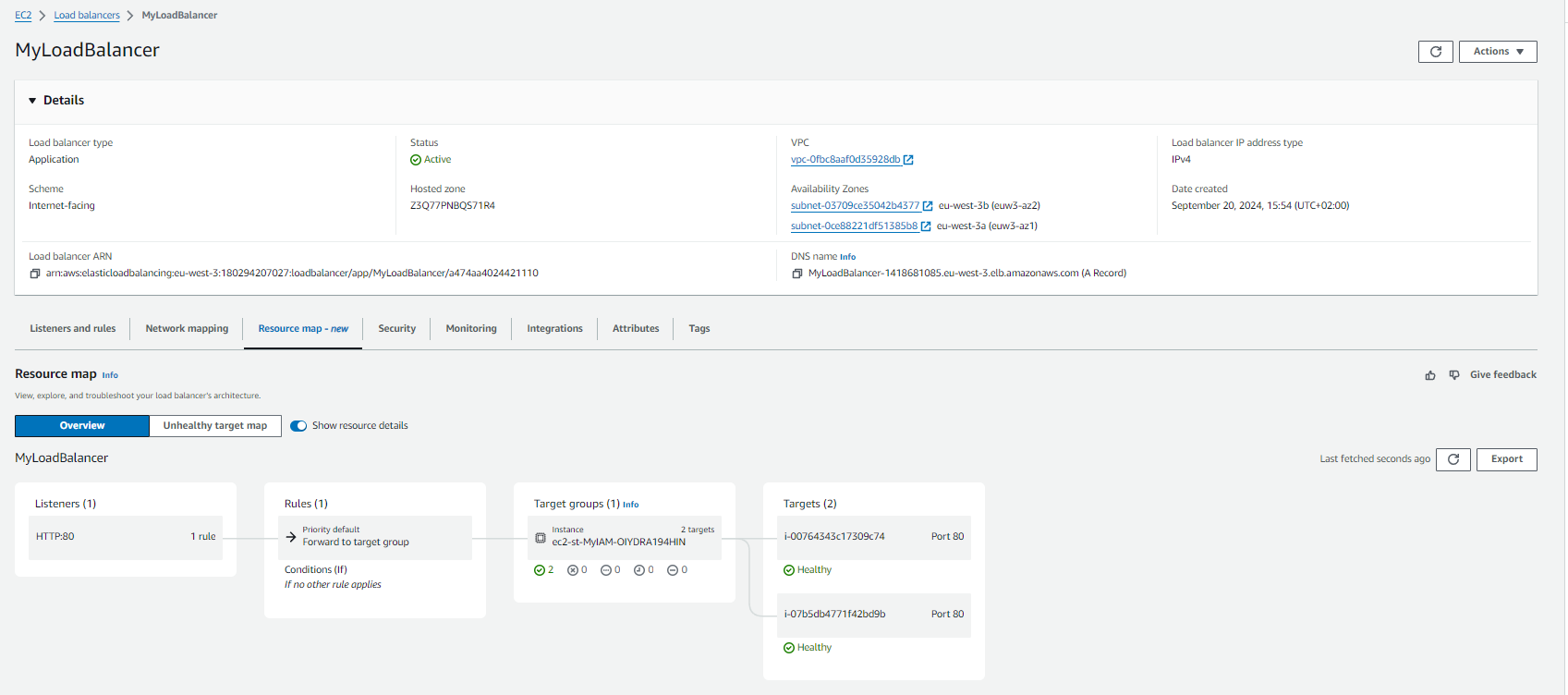
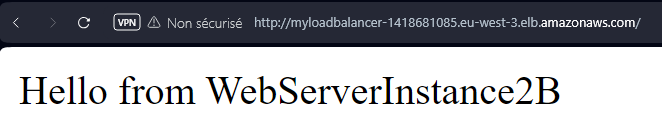
En utilisant le nom DNS de notre équilibreur de charge, nous pouvons voir que nous sommes redirigés vers l’une de nos instances que nous avons définies dans la cible ci-dessus :
Projet - Groupe Auto Scaling
Maintenant, nous voulons créer un groupe Auto Scaling. Pour être déclenché pour mettre à l’échelle notre groupe Auto Scaling. Nous allons créer une cloudWatchAlarm. Nous allons utiliser l’utilisation du processeur pour effectuer une mise à l’échelle si nécessaire. Si l’utilisation du processeur est supérieure à 70 %, nous aurons besoin d’une autre instance pour prendre en charge la charge.
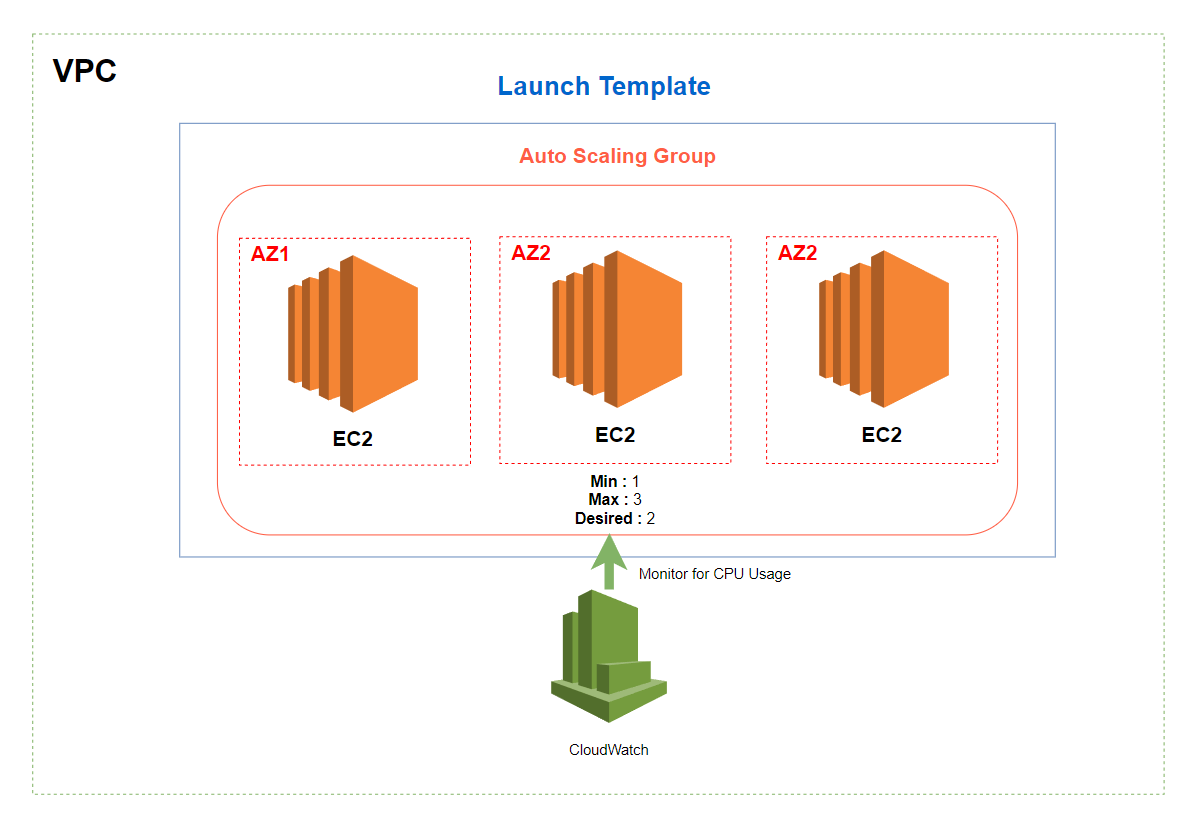
Vous pouvez trouver le modèle complet ici.
7 - S3
Qu’est-ce que S3 ?
Amazon S3 (Simple Storage Service) est un service de stockage d’objets basé sur le cloud hautement évolutif, conçu pour stocker et récupérer des données de n’importe où sur le web. Il offre une durabilité impressionnante de 99,999999999 % (appelée 11 nines de durabilité) et une disponibilité de 99,99 %, garantissant que vos données sont protégées contre la perte et accessibles en cas de besoin. S3 est connu pour sa grande capacité, sa sécurité et sa fiabilité, ce qui en fait l’un des services de stockage les plus utilisés dans le cloud computing.
Composants
Buckets
Les buckets sont les conteneurs de premier niveau utilisés pour stocker des objets (données) dans S3. Chaque bucket a un nom unique dans tous les comptes AWS à l’échelle mondiale et sert d’unité organisationnelle où les données sont stockées.
Principales caractéristiques :
- Les buckets peuvent être organisés avec des dossiers (répertoires virtuels) pour structurer vos données.
- Le nom du bucket doit être unique globalement, et par défaut, AWS autorise la création de jusqu’à 100 buckets par compte.
- La gouvernance des données peut être appliquée au niveau du bucket à l’aide de Bucket Policies (pour le contrôle d’accès).
Objets
Les objets sont les entités fondamentales stockées dans S3, constituées de données et de métadonnées associées. Chaque objet peut avoir une taille comprise entre 0 octet et 5 téraoctets et est identifié par une clé unique.
Composants :
- Fichier réel : Les données stockées (par exemple, une image, une vidéo, un document).
- Métadonnées : Informations sur l’objet, telles que son type de contenu, sa date de création et les métadonnées définies par l’utilisateur.
Clés
Une clé est un identifiant unique pour chaque objet dans un bucket. Elle comprend le chemin complet de l’objet, similaire à un chemin de fichier dans un système de fichiers traditionnel. Par exemple, dans le bucket my-bucket, la clé d’un objet peut être images/photo.jpg.
Fonctionnalités
Bucket Policies
Les Bucket Policies sont des politiques de contrôle d’accès basées sur JSON qui permettent un contrôle précis sur les personnes qui peuvent accéder à vos ressources S3 et sur la manière dont elles peuvent interagir avec elles.
- Principales caractéristiques :
- Autoriser ou refuser l’accès à des comptes AWS spécifiques, des utilisateurs IAM ou des plages d’adresses IP.
- Accorder des autorisations telles que lecture, écriture ou suppression pour les objets du bucket.
- Appliquer des exigences de chiffrement pour les objets téléchargés dans le bucket.
- Restreindre l’accès en fonction des référents HTTP ou exiger des conditions spécifiques pour l’accès.
Versioning
Le versioning vous permet de conserver plusieurs versions d’un objet dans un bucket. Lorsque le versioning est activé, S3 conserve les versions précédentes des objets, ce qui vous permet de récupérer en cas de suppressions ou de remplacements accidentels.
Avantages :
- Protection contre la suppression accidentelle : Restaure les objets à leur état précédent en cas de suppression.
- Conformité : Répond aux exigences réglementaires en matière de conservation des données.
- Activer ou suspendre : Vous pouvez activer ou suspendre le versioning à tout moment. Lorsqu’il est suspendu, les versions existantes sont conservées, mais de nouvelles versions ne sont plus créées.
Lifecycle Policies
Les Lifecycle Policies aident à automatiser la gestion des objets stockés dans S3. En fonction de règles prédéfinies, vous pouvez faire passer des objets entre différentes classes de stockage ou les supprimer après une certaine période.
- Principales caractéristiques :
- Faire passer des objets à des classes de stockage moins coûteuses (par exemple, déplacer des données de Standard vers Glacier après une certaine période).
- Faire expirer les objets après un délai spécifié pour libérer de l’espace et réduire les coûts.
- Supprimer les versions précédentes des objets en fonction des politiques de conservation définies.
Les politiques de cycle de vie permettent d’optimiser les coûts en faisant passer automatiquement les données vers des niveaux de stockage plus rentables à mesure que leur utilisation diminue.
Classes de stockage S3
Standard
Données fréquemment consultées et nécessitant durabilité et disponibilité
Intelligent
Modèles d’accès inconnus ou changeants. Il déplace automatiquement les données vers le niveau d’accès le plus rentable.
Accès peu fréquent (IA)
Données moins fréquemment consultées qui nécessitent un accès rapide en cas de besoin.
One Zone-InfrequentAccess (IA)
Les données sont stockées dans une seule zone de disponibilité et coûtent 20 % de moins que Standard IA. Données consultées peu fréquemment qui n’ont pas besoin d’être répliquées sur plusieurs AZ.
Glacier et Glacier Deep Archive
Stockage le moins cher pour l’archivage de données et la sauvegarde à long terme. Pour les données consultées peu fréquemment et lorsque plusieurs heures de temps de récupération sont appropriées.
```markdown
---
title: Projet - Déploiement d'un site web statique vers S3
description: Déploiement d'un site web statique vers S3.
lang: fr
pubDate: 2024-01-27T10:00:00.000Z
---
## Projet - Déploiement d'un site web statique vers S3
Nous allons déployer une simple page web statique vers S3. Je viens de créer une page index.html avec une balise H1 disant : "HI THIS IS A WEBSITE HOSTED ON AWS".
Vous pouvez trouver le modèle complet [ici](https://github.com/IssamSisbane/cea-cloudformation/blob/main/s3-static.yaml).
Voici comment créer un bucket S3 :
```yaml
MyS3Bucket:
Type: AWS::S3::Bucket
Properties:
BucketName: my-static-website-is
WebsiteConfiguration:
IndexDocument: index.htmlNous avons mis notre fichier index.html dans le bucket :
aws s3 cp index.html s3://my-static-website-isSi nous essayons d’accéder au fichier dans le bucket, nous rencontrons un Access Denied :
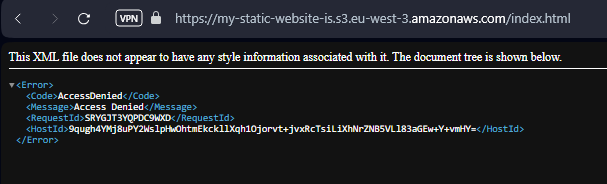
Si nous essayons de déboguer en utilisant la console AWS, nous trouvons ce paramètre intéressant :
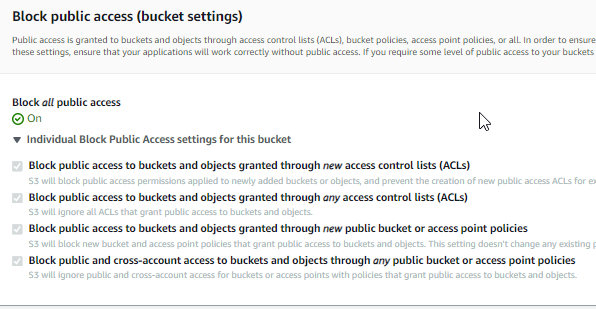
Nous devons mettre à jour les politiques du bucket pour autoriser l’accès public.
MyS3Bucket:
Type: AWS::S3::Bucket
Properties:
BucketName: my-static-website-is
WebsiteConfiguration:
IndexDocument: index.html
PublicAccessBlockConfiguration:
RestrictPublicBuckets: falseCela fonctionne maintenant :

8 - RDS (Service de base de données relationnelle)
La base de données relationnelle gérée par AWS. AWS s’occupe du provisionnement, de la configuration, des correctifs et des sauvegardes.
Sous le capot, RDS est construit sur EC2. Nous pouvons utiliser de nombreux moteurs de bases de données tels que :
- MySQL
- PostgresSQL
- MariaDB
- Oracle DB
Avantages
Multi-AZ
Les bases de données sont répliquées sur plusieurs AZ. Cela améliore la fiabilité et la disponibilité.
Basculement automatique
Il existe un basculement automatique vers l’instance de secours, ce qui permet à notre base de données de continuer à fonctionner.
Réplicas en lecture
Permettent de gérer les charges de travail en lecture seule pour alléger la base de données. Notre base de données principale ne serait pas surchargée. Nous aurons une base de données pour l’écriture des données et une pour la lecture des données. Nous pouvons placer des réplicas en lecture dans d’autres régions.
Sauvegardes automatiques
Cela se produit une fois par jour et comprend à la fois : l’instance RDS et les journaux de transactions. Nous pouvons choisir la période de conservation (jusqu’à 35 jours). Si nous voulons le conserver plus longtemps, nous devons créer des instantanés manuels de notre base de données. Nous pouvons stocker les sauvegardes dans AWS S3.
Projet - Création de base de données
Ceci est un modèle pour créer une nouvelle base de données RDS MySQL :
AWSTemplateFormatVersion: "2010-09-09"
Description: CloudFormation template to create an RDS instance
Resources:
# MyDB
MyDb:
Type: AWS::RDS::DBInstance
Properties:
DBInstanceIdentifier: MyNewRDS
MasterUsername: admin # in prodcution we would use KMS to encrypt this
MasterUserPassword: password # in prodcution we would use KMS to encrypt this
DBInstanceClass: db.t3.micro
Engine: mysql
EngineVersion: 8.0.35
AllocatedStorage: 20
BackupRetentionPeriod: 7DynamoDB
La base de données non relationnelle gérée par AWS.