
Améliorer mes compétences Cloud - Semaine 3 - Applications de conception de systèmes
L’objectif de cette semaine est vaste, couvrant des sujets allant des types architecturaux fondamentaux aux subtilités du stockage, de la mise en cache et de l’équilibrage de charge dans le cloud. J’explorerai des modèles architecturaux critiques comme les architectures monolithiques, microservices et sans serveur, je comprendrai comment les API fonctionnent comme des ponts de communication et j’examinerai le modèle d’architecture à trois niveaux qui pose les bases d’applications évolutives et maintenables.
Cette approche à multiples facettes aide non seulement à consolider mes connaissances du cloud, mais offre également une expérience pratique grâce à des projets concrets.
Comme je l’ai mentionné dans mon précédent article, je viens d’un background en cloud computing et en ingénierie logicielle, donc tout au long de mon parcours d’apprentissage, je marquerai les nouveaux concepts avec le hashtag #nouveau. Cela aidera à mettre en évidence ce qui est nouveau pour moi et offrira aux lecteurs une idée plus claire des endroits où ils pourraient trouver une valeur ajoutée, qu’ils revisitent des concepts familiers ou qu’ils rencontrent de nouveaux éléments.
Restez à l’écoute, car je continue de documenter mon processus d’apprentissage et de partager des points à retenir pratiques de chaque module !
1 - Architecture monolithique
2 - Architecture microservices
3 - Architecture sans serveur
4 - API
5 - Architecture à trois niveaux
6 - Options de stockage cloud
7 - Mise en cache
8 - Équilibreur de charge vs passerelle API
9 - Mise à l’échelle serveur vs sans serveur
10 - Projet | Concevoir une architecture pour une application de commerce électronique
11 - Projet | Concevoir une architecture pour Youtube
1 — Types d’architecture
Il existe trois principaux types d’architecture, qui sont :
- L’architecture monolithique est une conception logicielle traditionnelle où l’ensemble de l’application est construit comme une seule unité unifiée. Cette architecture comprend généralement trois composants principaux : l’interface utilisateur (UI), la logique métier (Backend) et l’interface de données. Bien qu’elle soit simple à développer, à maintenir et à déployer, elle présente des défis lorsque l’application doit s’adapter ou évoluer. Les modifications apportées à une partie du système peuvent affecter l’ensemble de l’application, et la mise à l’échelle nécessite souvent de répliquer l’ensemble du monolithe, ce qui entraîne une utilisation inefficace des ressources.
- L’architecture microservices décompose l’application en services plus petits, indépendants. Chaque microservice est responsable d’une fonction métier spécifique, telle que l’authentification des utilisateurs, la gestion des produits ou le traitement des paiements. Ces services communiquent via des API et gèrent leurs propres bases de données, favorisant un couplage faible et une évolutivité indépendante. Les microservices permettent à différentes équipes de travailler simultanément sur différents services, offrant une plus grande flexibilité et agilité. Cependant, ils introduisent également une complexité en termes de coordination des services, de cohérence des données et de frais généraux opérationnels, nécessitant des stratégies robustes pour la communication, la sécurité et la surveillance.
- L’architecture sans serveur déplace l’attention de la gestion des serveurs à la gestion de fonctions individuelles. Dans ce modèle, les fournisseurs de cloud gèrent l’infrastructure, ce qui permet aux développeurs de déployer des fonctions basées sur les événements qui s’adaptent automatiquement en réponse à la demande. Les architectures sans serveur sont rentables, car vous ne payez que le temps de calcul utilisé lorsqu’une fonction est activement en cours d’exécution. Ce modèle est particulièrement adapté aux applications avec des modèles de trafic variables ou imprévisibles, tels que les charges de travail basées sur les événements, le traitement des données en temps réel ou les API backend. Cependant, les fonctions sans serveur sont sans état, ce qui peut compliquer la gestion de l’état entre les exécutions, et elles peuvent souffrir de problèmes de latence en raison des démarrages à froid.
Cas d’utilisation
- Architecture monolithique : Idéale pour les applications à petite échelle, les startups ou les systèmes hérités où la simplicité et un délai de mise sur le marché rapide sont plus importants que l’évolutivité et la flexibilité.
- Architecture microservices : Cas d’utilisation : Le mieux adapté aux applications volumineuses et complexes qui nécessitent une haute disponibilité, une mise à l’échelle indépendante et un déploiement continu. Les exemples incluent les plateformes de commerce électronique, les sites de médias sociaux et les applications SaaS à grande échelle.
- Architecture sans serveur : Cas d’utilisation : Idéale pour les applications basées sur les événements, le traitement des données en temps réel et les applications avec des charges de travail variables comme les chatbots, les backends IoT ou les services de traitement vidéo.
Avantages et inconvénients
Avantages de l’architecture monolithique :
- Simplicité : Base de code unique, facile à comprendre et à gérer.
- Environnement unifié : Processus de débogage, de test et de déploiement rationalisés.
- Gestion centralisée : Convient aux petites équipes où une prise de décision centralisée est possible.
Inconvénients de l’architecture monolithique :
- Évolutivité : La mise à l’échelle verticale est limitée et peut devenir coûteuse. La mise à l’échelle horizontale nécessite de dupliquer l’ensemble de l’application.
- Manque de flexibilité : Le couplage étroit rend difficile la mise en œuvre de modifications ou de nouvelles fonctionnalités sans affecter l’ensemble du système.
- Complexité du déploiement : Le déploiement des mises à jour nécessite le redéploiement de l’ensemble de l’application, ce qui augmente le risque de temps d’arrêt.
Avantages de l’architecture microservices :
- Évolutivité : Les services peuvent être mis à l’échelle indépendamment, ce qui permet une allocation optimisée des ressources.
- Flexibilité : Chaque service peut utiliser différentes technologies, langages et bases de données adaptés à ses besoins.
- Résilience : Les pannes isolées empêchent les problèmes en cascade dans l’ensemble du système.
- Agilité : Cycles de développement plus rapides avec des mises à jour de services indépendantes.
Inconvénients de l’architecture microservices :
- Complexité : Nécessite une gestion minutieuse de la communication entre les services, de la cohérence des données et des transactions distribuées.
- Frais généraux opérationnels : Plusieurs services signifient plus de pipelines de déploiement, d’outils de surveillance et d’infrastructure à gérer.
- Sécurité et tests : Nécessite des mesures de sécurité robustes et des stratégies de test complexes pour garantir que tous les services fonctionnent de manière transparente.
Avantages de l’architecture sans serveur :
- Rentabilité : Le modèle de paiement à l’exécution réduit les coûts, en particulier pour les applications avec un trafic variable.
- Mise à l’échelle automatique : S’adapte automatiquement en fonction de la demande sans intervention manuelle.
- Aucune gestion de l’infrastructure : Le fournisseur de cloud gère la mise à l’échelle, les correctifs et le provisionnement des serveurs.
- Développement plus rapide : Concentrez-vous sur la logique métier plutôt que sur la gestion des serveurs, en favorisant une itération et un déploiement rapides.
Inconvénients de l’architecture sans serveur :
- Démarrages à froid : Les fonctions peuvent subir des retards lors de la première invocation après avoir été inactives.
- Limites de temps d’exécution : Ne convient pas aux processus de longue durée.
- Sans état : Nécessite des services externes pour la gestion de l’état.
- Verrouillage du fournisseur : La dépendance à des fournisseurs de cloud spécifiques peut rendre la migration difficile.
Comment cela peut-il aider ?
Comprendre les forces et les faiblesses de chaque architecture est crucial pour prendre des décisions éclairées. Le bon choix dépend de facteurs tels que la complexité de l’application, les modèles de trafic attendus, la taille de l’équipe de développement et les besoins d’évolutivité à long terme. En évaluant ces aspects, les architectes peuvent sélectionner l’architecture la plus appropriée pour construire des systèmes évolutifs, résilients et efficaces.
2 — API
Une API (Interface de programmation d’application) est un pont de communication qui permet à différentes applications logicielles d’interagir. Elle définit un ensemble de règles pour accéder et utiliser les fonctionnalités d’une application, d’un service ou d’un système. Les API fonctionnent de la même manière qu’un serveur dans un restaurant, où l’API prend les requêtes (commandes) des clients (utilisateurs ou applications), communique avec le backend (cuisine) et renvoie les réponses (repas).
Éléments clés d’une API
- Actions ou opérations : Les API fournissent des points de terminaison pour des actions telles que GET (récupérer des données), POST (soumettre des données), PUT (mettre à jour des données) et DELETE (supprimer des données), définissant la manière dont les développeurs peuvent interagir avec l’application.
- Documentation de l’API : Sert de guide, détaillant les points de terminaison disponibles, les méthodes HTTP, les paramètres requis et les réponses possibles, souvent dans des formats tels que JSON ou XML.
- Cycle de requête et de réponse : L’API reçoit une requête du client, la traite via le backend et renvoie la réponse appropriée.
Importance des API
- Communication efficace : Les API garantissent un échange de données structuré et cohérent entre différents systèmes.
- Personnalisation et flexibilité : Les développeurs peuvent personnaliser leurs requêtes pour récupérer ou modifier des données spécifiques, ce qui permet des intégrations sur mesure.
- Intégration transparente : Dans les architectures complexes comme les microservices ou les systèmes cloud, les API permettent à divers composants de fonctionner ensemble de manière transparente.
Types d’API
- API Web (API HTTP/REST) : Couramment utilisées dans le développement Web, ces API communiquent via HTTP et sont sans état, ce qui les rend simples et évolutives.
- API SOAP : Utilisent XML pour les requêtes et les réponses, offrant des normes de sécurité et de transaction strictes, adaptées à des secteurs comme la banque.
- API GraphQL : Permettent aux clients de spécifier exactement les données nécessaires, réduisant la sur-extraction ou la sous-extraction des données.
- API internes : Utilisées au sein des organisations pour la communication interne entre les systèmes, améliorant les processus sans exposition publique.
Avantages de l’utilisation des API
- Développement modulaire : Permet le développement et la maintenance indépendants de différents composants d’application, facilitant l’évolutivité.
- Interopérabilité : Permet aux applications construites avec différentes technologies de communiquer, ce qui est crucial dans les environnements avec des piles technologiques diverses.
- Développement plus rapide : En utilisant les API existantes, les développeurs peuvent intégrer rapidement des fonctionnalités telles que l’authentification ou le traitement des paiements.
- Innovation et collaboration : Les API permettent aux développeurs externes d’étendre les fonctionnalités d’un produit, favorisant la collaboration et l’innovation.
Pourquoi est-ce important ?
Les API sont essentielles dans le développement logiciel moderne, servant de pont entre les systèmes, les applications et les services. Elles abstraitent la complexité des systèmes backend et fournissent aux développeurs des outils pour construire des applications flexibles, évolutives et interopérables. Qu’il s’agisse d’une API REST pour la communication Web, d’une API SOAP pour les transactions sécurisées ou d’une API GraphQL pour la récupération de données sur mesure, les API sont cruciales pour une intégration et une évolutivité efficaces dans le paysage numérique actuel.
3 — Architecture à trois niveaux #nouveau
L’architecture à trois niveaux est un modèle de conception logicielle qui divise une application en trois couches : la couche de présentation, la couche d’application (logique métier) et la couche de données. Cette structure est couramment utilisée dans divers modèles architecturaux, notamment les architectures monolithiques, microservices et sans serveur, pour créer des applications évolutives et maintenables.
Les trois niveaux
- Niveau de présentation (couche UI) : Il s’agit du front-end où les utilisateurs interagissent avec l’application, comme les interfaces Web ou les applications mobiles. Il gère l’affichage des données et les entrées de l’utilisateur, communiquant avec le backend pour traiter les requêtes.
- Niveau d’application (couche de logique métier) : Également appelé couche intermédiaire, ce niveau traite la logique métier et les règles. Il gère les requêtes du niveau de présentation, effectue des calculs et interagit avec la couche de données.
- Niveau de base de données (couche de données) : Ce niveau est responsable du stockage, de la gestion et de la récupération des données. Il utilise des bases de données (relationnelles ou NoSQL) pour stocker les données persistantes et garantit l’intégrité et la sécurité des données.
Avantages de l’architecture à trois niveaux
- Évolutivité : Chaque niveau peut être mis à l’échelle indépendamment. Par exemple, davantage de serveurs peuvent être ajoutés au niveau de présentation pour gérer l’augmentation du trafic utilisateur ou au niveau d’application pour traiter une logique métier plus complexe.
- Maintenabilité : Une séparation claire des préoccupations facilite la mise à jour ou la modification d’un niveau sans affecter les autres, améliorant ainsi la maintenabilité du système.
- Réutilisabilité : Des composants comme la couche de logique métier peuvent être réutilisés sur différentes interfaces (par exemple, applications Web et mobiles), réduisant ainsi la duplication du code.
- Flexibilité : Chaque niveau peut utiliser différentes technologies, offrant une flexibilité dans le choix des outils les plus adaptés à chaque partie du système.
Comment ça marche
- Interaction de l’utilisateur : Les utilisateurs interagissent avec le frontend (niveau de présentation) en effectuant des requêtes (par exemple, en soumettant des formulaires).
- Traitement des requêtes : Le niveau d’application reçoit et traite ces requêtes, en appliquant la logique métier et, si nécessaire, en interagissant avec la couche de données.
- Gestion des données : La couche de base de données stocke ou récupère les données selon les instructions du niveau d’application.
- Réponse : Le niveau d’application renvoie les données traitées au niveau de présentation, qui les affiche à l’utilisateur.
Pourquoi est-ce important ?
L’architecture à trois niveaux offre une approche structurée pour la création d’applications évolutives, maintenables et flexibles. En séparant l’application en trois couches distinctes, les développeurs peuvent créer des systèmes modulaires qui peuvent évoluer et s’adapter indépendamment. Cette architecture est particulièrement adaptée aux applications Web, d’entreprise et basées sur le cloud où l’évolutivité et la maintenabilité sont essentielles.
4 — Options de stockage cloud
Dans le cloud, plusieurs options de stockage sont disponibles, chacune étant conçue pour répondre à différents types de besoins de stockage de données. Les trois principaux types de stockage cloud incluent le stockage de fichiers, le stockage par blocs et le stockage d’objets. Chacun offre des avantages, des cas d’utilisation et des compromis uniques en termes de performance, d’évolutivité et de coût.
Stockage de fichiers
Le stockage de fichiers est une méthode de stockage des données dans une structure hiérarchique de fichiers et de dossiers. Cette structure ressemble aux systèmes de fichiers traditionnels utilisés sur les serveurs physiques ou les ordinateurs personnels. Les données sont organisées en répertoires et sous-répertoires, ce qui les rend familières et faciles à naviguer pour de nombreux utilisateurs et applications.
Quand utiliser le stockage de fichiers ?
- Systèmes de fichiers partagés : Idéal lorsque les applications doivent accéder à un système de fichiers partagé sur plusieurs instances.
- Répertoires utilisateur : Convient aux répertoires utilisateur, tels que les répertoires personnels où les utilisateurs stockent des fichiers personnels.
- Hiérarchie structurée : Parfait pour stocker des fichiers et des dossiers dans une hiérarchie bien définie et structurée.
- Applications héritées : Utile pour les applications plus anciennes conçues pour fonctionner avec des systèmes de fichiers traditionnels.
Avantages du stockage de fichiers
- Structure familière : Le stockage de fichiers suit la même organisation basée sur les répertoires à laquelle la plupart des utilisateurs sont habitués.
- Opérations au niveau des fichiers : Il prend en charge les opérations au niveau des fichiers telles que ouvrir, fermer, lire, écrire et naviguer dans la structure des répertoires.
- Facilité d’utilisation : Facile à intégrer avec les applications qui dépendent déjà des systèmes de fichiers.
Inconvénients du stockage de fichiers
- Limitations d’évolutivité : Le stockage de fichiers est généralement moins évolutif que le stockage d’objets, en particulier lorsqu’il s’agit de quantités massives de données.
- Dégradation des performances : Les performances peuvent se dégrader en cas de nombre élevé de fichiers ou de plusieurs utilisateurs accédant simultanément au système.
Exemple : Amazon EFS (Elastic File System) — Une solution de stockage de fichiers évolutive à utiliser avec les instances Amazon EC2.
Stockage par blocs
Le stockage par blocs stocke les données dans des blocs de taille fixe, chacun avec un identifiant unique. Ces blocs sont gérés individuellement, et plusieurs blocs peuvent être combinés pour former un volume de stockage plus important. Le stockage par blocs est généralement utilisé dans les réseaux de stockage (SAN) et est idéal pour les applications nécessitant des performances élevées et une faible latence.
Quand utiliser le stockage par blocs ?
- Bases de données et données transactionnelles : Le mieux adapté aux bases de données ou aux applications transactionnelles qui nécessitent des opérations d’entrée/sortie (E/S) élevées.
- Machines virtuelles et conteneurs : Essentiel pour l’exécution de machines virtuelles ou de conteneurs qui ont besoin d’un accès direct à un système de fichiers.
- Stockage brut et non formaté : Utile pour les applications qui nécessitent un stockage brut, car le stockage par blocs se comporte comme un disque dur physique.
Avantages :
- Hautes performances : Le stockage par blocs est connu pour offrir des performances élevées avec une faible latence, ce qui le rend adapté aux charges de travail exigeantes.
- Contrôle : Fournit un contrôle granulaire sur le stockage, car chaque bloc peut être géré indépendamment, comme un disque dur individuel.
- Personnalisable : Les blocs peuvent être combinés ou partitionnés selon les besoins pour créer des structures de stockage spécifiques.
Inconvénients :
- Coût plus élevé : Le stockage par blocs est généralement plus cher que le stockage de fichiers ou d’objets en raison de ses performances élevées et de ses cas d’utilisation spécialisés.
- Moins évolutif : Il ne s’adapte pas aussi efficacement que le stockage d’objets en termes de capacité et de gestion.
- Frais généraux de gestion : Le stockage par blocs nécessite souvent une gestion manuelle pour la mise à l’échelle, ce qui peut introduire une complexité et des frais généraux opérationnels supplémentaires.
Exemple : Amazon EBS (Elastic Block Store) — Une solution de stockage par blocs hautes performances à utiliser avec les instances Amazon EC2.
Stockage d’objets
Le stockage d’objets est conçu pour gérer les données non structurées sous forme d’objets. Chaque objet contient les données elles-mêmes, ainsi que les métadonnées associées et un identifiant unique. Cela rend le stockage d’objets particulièrement adapté au stockage de grands volumes de données non structurées telles que les fichiers multimédias, les sauvegardes et les archives.
Quand utiliser le stockage d’objets ?
- Données non structurées : Idéal pour stocker de grandes quantités de données non structurées comme des photos, des vidéos et des journaux.
- Contenu web : Convient au contenu qui doit être accessible via HTTP/HTTPS, comme les fichiers statiques pour les sites web.
- Archivage et sauvegardes : Bien adapté à l’archivage ou à la sauvegarde de données en raison de son évolutivité illimitée.
Avantages ?
- Hautement évolutif : Le stockage d’objets peut évoluer horizontalement sans limites, ce qui le rend parfait pour les ensembles de données en croissance.
- Capacité illimitée : Prend en charge une capacité de stockage pratiquement illimitée, idéale pour les applications natives du cloud et le big data.
- Accessibilité : Les données sont accessibles partout, ce qui permet un accès global aux objets stockés.
- Métadonnées : Les objets peuvent stocker de riches métadonnées, qui peuvent être utilisées à des fins de recherche et d’analyse, ce qui en fait un outil puissant pour l’indexation et la gestion de grands ensembles de données.
Inconvénients ?
- Ne convient pas aux systèmes de fichiers traditionnels : Le stockage d’objets ne fournit pas la structure hiérarchique nécessaire aux applications qui s’appuient sur des systèmes de fichiers ou qui nécessitent des mises à jour fréquentes et complexes.
- Latences plus élevées : Le stockage d’objets a généralement des latences plus élevées que le stockage par blocs, ce qui le rend moins idéal pour les applications en temps réel ou à hautes performances.
Exemple : Amazon S3 (Simple Storage Service) — Un service de stockage d’objets hautement évolutif conçu pour stocker et récupérer n’importe quelle quantité de données à tout moment.
Choisir la bonne option de stockage
La sélection de la bonne option de stockage cloud dépend de plusieurs facteurs, notamment :
- Exigences de l’application : L’application a-t-elle besoin d’un stockage de données structurées (stockage de fichiers), d’un stockage de données transactionnelles à hautes performances (stockage par blocs) ou d’un stockage de données non structurées évolutif (stockage d’objets) ?
- Besoins de performance : Si une faible latence et un débit élevé sont essentiels, le stockage par blocs peut être la meilleure option. Si l’évolutivité est la principale préoccupation, le stockage d’objets est probablement le bon choix.
- Évolutivité : Le stockage d’objets offre la plus grande évolutivité, tandis que le stockage par blocs est plus limité à cet égard.
- Considérations de coût : Le stockage par blocs a tendance à être le plus cher en raison de ses hautes performances, tandis que le stockage d’objets offre une évolutivité plus rentable pour les grands ensembles de données.
5 — Mise en cache
La mise en cache est une technique qui stocke temporairement les données dans un cache, un emplacement de stockage temporaire, pour permettre une récupération plus rapide des données. Au lieu d’extraire les données de l’emplacement de stockage principal (comme une base de données ou une API externe) à chaque fois qu’elles sont demandées, la mise en cache stocke les données fréquemment consultées plus près de l’application. Cela améliore considérablement l’efficacité et les performances en réduisant le temps nécessaire pour accéder aux données et en diminuant la charge sur le système de stockage principal.
En bref, la mise en cache permet de gagner du temps et des ressources en évitant les allers-retours inutiles vers la source de données principale, ce qui la rend idéale pour améliorer les performances des systèmes qui accèdent fréquemment aux mêmes données.
Pourquoi la mise en cache est-elle importante ?
La mise en cache joue un rôle essentiel dans l’amélioration des performances et de l’évolutivité des systèmes, en particulier dans les applications gourmandes en données. Voici les principales raisons pour lesquelles la mise en cache est importante :
Amélioration des performances :
La mise en cache améliore les temps de réponse et réduit la latence, ce qui rend les applications beaucoup plus rapides. Dans les systèmes à fort trafic ou les applications gourmandes en données, même quelques millisecondes de retard peuvent avoir un impact sur la satisfaction de l’utilisateur.
- Exemple : Une application web qui interroge fréquemment une base de données pour les mêmes données peut utiliser la mise en cache pour accélérer la récupération des données et améliorer l’expérience utilisateur.
Évolutivité :
En réduisant le nombre d’allers-retours vers le backend (comme les bases de données ou les API), la mise en cache permet de diminuer la charge sur le système, ce qui le rend plus évolutif. La mise en cache permet aux systèmes de gérer plus d’utilisateurs simultanés sans dégrader les performances.
Économies de coûts :
Dans les environnements cloud, chaque utilisation des ressources entraîne des coûts opérationnels. La mise en cache permet de gagner de l’argent en réduisant la nécessité d’accéder fréquemment à des ressources à forte computation. L’accès aux données à partir du cache nécessite moins de puissance de calcul, ce qui réduit les coûts liés à :
- Transfert de données
- Opérations d’E/S de stockage (entrée/sortie)
- Ressources de calcul
La mise en cache peut également réduire les coûts de transfert de données et les coûts d’E/S en minimisant les opérations de lecture et d’écriture vers la base de données principale.
Types de mise en cache
Différents types de mise en cache sont utilisés pour résoudre des goulots d’étranglement spécifiques en matière de performances dans les applications modernes :
- Mise en cache du navigateur : La mise en cache du navigateur stocke les fichiers tels que HTML, CSS, JavaScript et les images localement sur le navigateur de l’utilisateur. Lorsqu’un utilisateur revisite une page web, le navigateur récupère ces fichiers à partir du cache local au lieu de les télécharger à nouveau à partir du serveur.
- Mise en cache du réseau de diffusion de contenu (CDN) : Un réseau de diffusion de contenu (CDN) est un réseau distribué de serveurs qui stockent des copies mises en cache du contenu géographiquement plus près de l’utilisateur. Les CDN mettent en cache le contenu statique (tel que les images, les vidéos et les pages web) dans plusieurs emplacements dans le monde afin de réduire le temps nécessaire à la diffusion du contenu.
- Mise en cache en mémoire : La mise en cache en mémoire stocke les données directement dans la RAM (mémoire vive) du serveur, ce qui rend la récupération des données beaucoup plus rapide que la lecture à partir du stockage sur disque. Ce type de mise en cache est idéal pour les données qui nécessitent un accès fréquent mais qui n’ont pas besoin d’un stockage permanent.
- Mise en cache de base de données : La mise en cache de base de données implique le stockage temporaire des résultats de requêtes de base de données coûteuses. Lorsqu’une requête est exécutée, le système vérifie d’abord le cache pour voir si le résultat est déjà stocké. Si ce n’est pas le cas, il récupère les données de la base de données et les stocke dans le cache pour une utilisation ultérieure.
- Mise en cache d’application : La mise en cache d’application stocke les données de session utilisateur ou les préférences utilisateur au niveau de l’application. Ce type de mise en cache peut être implémenté dans le code de l’application ou via des systèmes de mise en cache externes.
Pourquoi la mise en cache est-elle importante ?
La mise en cache est une technique puissante qui aide les applications à obtenir de meilleures performances, une évolutivité et une rentabilité en stockant temporairement les données fréquemment consultées plus près de l’endroit où elles sont nécessaires. Que ce soit par le biais de la mise en cache du navigateur, de la mise en cache CDN, de la mise en cache en mémoire, de la mise en cache de base de données ou de la mise en cache d’application, l’utilisation stratégique des caches peut :
- Optimiser l’utilisation des ressources
- Réduire les coûts
- Améliorer les performances globales du système
Dans les environnements cloud, la mise en cache peut réduire considérablement les coûts opérationnels et améliorer les temps de réponse, ce qui en fait un composant essentiel de la conception des systèmes modernes.
6 — Équilibreur de charge
Un équilibreur de charge est conçu pour distribuer le trafic réseau entrant sur plusieurs serveurs, en veillant à ce qu’aucun serveur ne soit submergé par les requêtes. Cela permet non seulement d’optimiser l’utilisation des ressources, mais aussi d’améliorer la fiabilité, la disponibilité et les performances globales du système.
Comment fonctionnent les équilibreurs de charge
- Routage du trafic : Les équilibreurs de charge utilisent divers algorithmes pour acheminer les requêtes entrantes vers le serveur le plus approprié. Les algorithmes de routage courants incluent : (Round-robin, Least connection, IP Hash…)
- Mise à l’échelle des ressources : Les équilibreurs de charge peuvent mettre à l’échelle dynamiquement les ressources des serveurs en réponse aux pics de trafic. Cela garantit une utilisation efficace en cas de forte demande et préserve les ressources pendant les périodes de faible trafic en réduisant le nombre de serveurs.
- Fonctionnalités de diffusion d’applications : Les équilibreurs de charge modernes, qui font souvent partie d’un contrôleur de diffusion d’applications (ADC), offrent des fonctionnalités supplémentaires telles que la mise en cache et la compression, ce qui améliore encore les performances.
Avantages des équilibreurs de charge
- Fiabilité améliorée : Distribue le trafic sur plusieurs serveurs, réduisant le risque de point de défaillance unique.
- Haute disponibilité : Garantit que l’application reste disponible même si certains serveurs sont en panne ou en maintenance.
- Performances améliorées : Équilibre la charge pour éviter les surcharges de serveurs, réduisant ainsi la latence et améliorant les temps de réponse.
Types d’équilibreurs de charge
- Équilibreurs de charge matériels : Déployés sous forme de dispositifs physiques dans un centre de données.
- Équilibreurs de charge logiciels : Instances virtualisées qui s’exécutent sur des environnements cloud ou sur site.
Cas d’utilisation
Les équilibreurs de charge sont essentiels dans les scénarios où vous devez distribuer le trafic de manière uniforme sur les serveurs pour maintenir une haute disponibilité, en particulier dans les systèmes distribués ou les applications basées sur le cloud.
7 — Passerelle API
Une passerelle API agit comme un point d’entrée unique pour toutes les requêtes client destinées à divers services backend. Dans les architectures de microservices, une passerelle API joue un rôle crucial en découplant l’interface client du backend, en gérant et en acheminant les requêtes vers le microservice approprié.
Comment fonctionnent les passerelles API
- Routage et agrégation des requêtes : La passerelle API peut agréger plusieurs requêtes client et les acheminer vers les microservices appropriés. Ceci est particulièrement utile lorsqu’une action client nécessite des données ou des services de plusieurs microservices.
- Sécurité et authentification : Les passerelles API appliquent des politiques de sécurité telles que l’authentification, l’autorisation et la limitation du débit pour contrôler le trafic et protéger les services backend. Elles gèrent également la terminaison SSL, réduisant ainsi la charge sur les serveurs backend.
- Gestion du trafic : En plus d’acheminer les requêtes, les passerelles API gèrent le trafic au niveau de l’API, y compris la limitation du débit (pour éviter les abus) et la journalisation (pour la surveillance et l’analyse).
Avantages des passerelles API
- Simplifie les interactions client : Les clients interagissent avec un point de terminaison API unique et unifié, tandis que la passerelle gère la communication avec les multiples services backend.
- Sécurité renforcée : La passerelle API peut agir comme une couche de sécurité, gérant l’authentification et empêchant l’accès non autorisé, tout en masquant les services internes à l’exposition directe aux clients.
- Limitation du débit et contrôle du trafic : La passerelle peut limiter les requêtes pour éviter de surcharger les services backend et améliorer l’évolutivité.
Cas d’utilisation des passerelles API
- Architectures de microservices : Les passerelles API sont particulièrement utiles dans les environnements de microservices, où elles simplifient les interactions entre le client et de nombreux services backend.
- Gestion de la sécurité : Elles centralisent l’application de la sécurité, en veillant à ce que toutes les requêtes client respectent les mêmes contrôles d’accès et politiques.
- Gestion des requêtes : L’agrégation de plusieurs requêtes en une seule réduit le nombre d’interactions client-serveur, améliorant ainsi l’efficacité et les performances.
8 — Équilibreurs de charge vs passerelles API
Bien que les équilibreurs de charge et les passerelles API gèrent tous deux le trafic, ils ont des objectifs et des capacités distincts :
Objectif principal
- Équilibreur de charge : Se concentre sur la distribution du trafic, en veillant à ce que les requêtes soient acheminées de manière uniforme vers les serveurs backend afin d’optimiser l’utilisation des ressources et d’éviter les surcharges.
- Passerelle API : Se concentre sur la gestion des API, en acheminant les requêtes API vers les microservices appropriés tout en gérant l’authentification, la limitation du débit et l’agrégation des requêtes.
Implémentation
- Équilibreur de charge : Fonctionne généralement au niveau du réseau ou de la couche de transport (couche 4 ou couche 7), en distribuant le trafic entre plusieurs serveurs.
- Passerelle API : Fonctionne au niveau de la couche application (couche 7), gérant spécifiquement les requêtes API et traitant les fonctionnalités au niveau de l’API telles que la sécurité, la journalisation et la transformation des données.
Gestion du trafic
- Équilibreur de charge : Gère le routage général du trafic en distribuant les requêtes entrantes sur plusieurs serveurs à l’aide de divers algorithmes.
- Passerelle API : Gère les requêtes spécifiques à l’API en les acheminant vers le microservice correct, tout en effectuant également des fonctions supplémentaires telles que la limitation du débit, la mise en cache et la journalisation.
Capacités
- Équilibreur de charge : Principalement axé sur la distribution du trafic et la mise à l’échelle des ressources.
- Passerelle API : Fournit un plus large éventail de fonctionnalités, notamment l’application de la sécurité, l’agrégation des requêtes et le contrôle du trafic.
Exposition des services
- Équilibreur de charge : Principalement axé sur la distribution du trafic backend sur les serveurs, il n’expose pas de services backend spécifiques aux clients.
- Passerelle API : Agit comme l’interface publique pour les microservices, permettant aux clients externes d’interagir avec le backend via un point d’entrée API unique.
Conclusion
Les équilibreurs de charge et les passerelles API sont tous deux des outils essentiels dans les systèmes distribués modernes, mais ils servent des objectifs différents :
- Les équilibreurs de charge garantissent une haute disponibilité, une fiabilité et des performances en distribuant le trafic sur les serveurs, en évitant les surcharges et en maintenant la disponibilité du système.
- Les passerelles API offrent un moyen centralisé de gérer le trafic API, d’améliorer la sécurité et de simplifier les interactions client avec des services backend complexes, en particulier dans les architectures de microservices.
Comprendre les rôles distincts de chacun aide les organisations à concevoir des systèmes évolutifs, sécurisés et résilients, en optimisant à la fois les performances du backend et l’expérience utilisateur.
Dans les architectures cloud modernes, la mise à l’échelle est un facteur crucial pour garantir que les applications peuvent gérer efficacement des quantités variables de trafic. Les serveurs (machines virtuelles) et les fonctions sans serveur représentent deux approches distinctes de la mise à l’échelle, chacune ayant ses propres avantages et défis. Il est essentiel de comprendre les différences entre la mise à l’échelle verticale, la mise à l’échelle horizontale et la mise à l’échelle sans serveur pour choisir la bonne stratégie pour votre application.
9 — Mise à l’échelle verticale (Serveurs)
La mise à l’échelle verticale consiste à augmenter la capacité d’un seul serveur (ou d’une machine virtuelle) en ajoutant davantage de ressources, telles que le processeur, la mémoire ou le stockage.
Comment fonctionne la mise à l’échelle verticale ?
- Pour mettre à l’échelle une machine virtuelle, vous arrêtez généralement le serveur et passez à un type d’instance plus puissant qui offre davantage de ressources.
- Une fois la nouvelle instance prête, vous redirigez le trafic vers la machine mise à jour.
Principaux avantages
- Simplicité : La mise à l’échelle verticale est simple, car elle consiste simplement à augmenter les ressources disponibles pour un seul serveur.
- Rapide et facile : Pour les petites ou moyennes charges de travail, cette méthode est rapide à mettre en œuvre, car vous ne travaillez qu’avec une seule machine.
Limitations
- Limites de ressources : La mise à l’échelle verticale est limitée par la capacité maximale du serveur ou du type d’instance. Il existe une limite finie à la quantité de processeur et de mémoire que vous pouvez ajouter.
- Temps d’arrêt : Le processus implique généralement d’arrêter la machine et d’en lancer une nouvelle, ce qui peut entraîner des temps d’arrêt et avoir un impact sur la disponibilité.
- Processus répété : Chaque fois que le serveur atteint sa capacité, vous devez répéter ce processus, et vous atteindrez finalement les limites physiques ou virtuelles du serveur.
Cas d’utilisation
- La mise à l’échelle verticale est idéale pour les petites applications ou les systèmes avec des charges de travail prévisibles qui ne nécessitent pas une mise à l’échelle massive ou pour lesquels la simplicité est privilégiée.
10 — Mise à l’échelle horizontale (Serveurs)
La mise à l’échelle horizontale, également appelée mise à l’échelle externe, consiste à ajouter davantage de serveurs pour répartir la charge plutôt que d’augmenter la capacité d’un seul serveur. C’est la méthode privilégiée pour les systèmes distribués à grande échelle.
Comment fonctionne la mise à l’échelle horizontale
- Au lieu de mettre à niveau un seul serveur, vous ajoutez davantage de serveurs à un groupe de mise à l’échelle.
- Le trafic est automatiquement équilibré entre ces serveurs, ce qui supprime efficacement les limites de capacité, car davantage de machines peuvent être ajoutées si nécessaire.
Principaux avantages
- Évolutivité illimitée : La mise à l’échelle horizontale supprime les limitations physiques d’une seule machine, vous permettant de mettre à l’échelle à l’infini en ajoutant davantage de serveurs pour gérer l’augmentation du trafic.
- Tolérance aux pannes : En distribuant le trafic sur plusieurs serveurs, vous augmentez la résilience du système, car la défaillance d’une machine n’a pas d’impact sur l’ensemble du système.
- Mise à l’échelle automatisée : Dans les environnements cloud modernes, la mise à l’échelle horizontale peut être automatisée à l’aide de groupes de mise à l’échelle automatique qui ajoutent ou suppriment dynamiquement des serveurs en fonction de la demande en temps réel.
Limitations
- Complexité accrue : La gestion d’un grand nombre de serveurs introduit plus de complexité en termes d’orchestration, de maintenance et de surveillance.
- Coût : L’ajout de davantage de serveurs pour gérer les pics de trafic peut augmenter les coûts opérationnels, en particulier si le trafic est incohérent ou imprévisible.
Cas d’utilisation
- La mise à l’échelle horizontale est idéale pour les applications à grande échelle qui nécessitent une haute disponibilité, une résilience et la capacité de gérer de grands volumes de trafic, tels que les sites web de commerce électronique ou les plateformes de diffusion de vidéos en continu.
11 — Mise à l’échelle sans serveur
La mise à l’échelle sans serveur est fondamentalement différente de la mise à l’échelle traditionnelle basée sur des serveurs. Dans un environnement sans serveur, le fournisseur de cloud gère automatiquement la mise à l’échelle des ressources en fonction des requêtes entrantes, sans qu’il soit nécessaire d’intervenir manuellement ou de définir des limites de capacité prédéfinies.
Comment fonctionne la mise à l’échelle sans serveur
- Chaque requête entrante déclenche une nouvelle instance d’une fonction sans serveur (telle que AWS Lambda, Google Cloud Functions ou Azure Functions).
- Le fournisseur de cloud gère la mise à l’échelle de manière transparente, en veillant à ce que l’application puisse gérer n’importe quelle quantité de trafic en lançant automatiquement de nouvelles instances si nécessaire.
- Chaque instance fonctionne indépendamment et est de courte durée, traitant une seule tâche avant de se terminer.
Principaux avantages
- Évolutivité transparente : Les architectures sans serveur peuvent évoluer pour gérer pratiquement n’importe quel volume de trafic sans intervention manuelle. Cela est idéal pour les applications avec un trafic imprévisible ou en rafales.
- Aucune gestion de l’infrastructure : Les développeurs n’ont pas à se soucier de la gestion des serveurs ou de la planification de la capacité — la mise à l’échelle est entièrement automatisée et gérée par le fournisseur.
- Rentabilité : Dans un modèle sans serveur, vous ne payez que pour le temps d’exécution de chaque fonction. Lorsqu’aucune requête n’est traitée, aucune ressource n’est consommée, ce qui rend le sans serveur très rentable pour les applications avec des charges de travail sporadiques.
Limitations
- Démarrages à froid : Les fonctions sans serveur peuvent subir une latence de démarrage à froid, c’est-à-dire un léger délai lorsque la fonction est invoquée après avoir été inactive pendant un certain temps. Cela peut avoir un impact sur les performances des applications nécessitant des réponses à faible latence.
- Limites d’exécution : Les fonctions sans serveur ont généralement des limites de temps d’exécution (par exemple, AWS Lambda a une durée d’exécution maximale de 15 minutes), ce qui peut être une limitation pour les processus de longue durée.
- Contrôle limité : Avec le sans serveur, vous avez moins de contrôle sur l’infrastructure sous-jacente, ce qui peut rendre certaines personnalisations ou configurations plus difficiles.
Cas d’utilisation
- La mise à l’échelle sans serveur est idéale pour les applications basées sur les événements, les API et les services qui subissent un trafic sporadique ou des charges imprévisibles. Elle est particulièrement bénéfique pour les charges de travail où le trafic fluctue ou où l’optimisation des coûts est une priorité.
12 — Mise à l’échelle serveur vs sans serveur
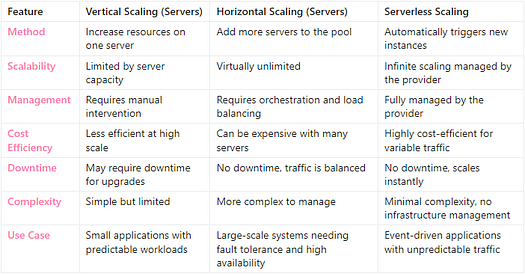
Choisir entre la mise à l’échelle serveur et sans serveur
- La mise à l’échelle verticale convient aux petites applications ou aux systèmes avec des charges de travail prévisibles où la simplicité est plus importante que l’évolutivité.
- La mise à l’échelle horizontale est essentielle pour les grandes applications qui doivent gérer des volumes de trafic importants et qui nécessitent une tolérance aux pannes et une résilience.
- La mise à l’échelle sans serveur offre la meilleure solution pour les charges de travail basées sur les événements ou imprévisibles, offrant une mise à l’échelle transparente et une rentabilité sans avoir besoin de gérer l’infrastructure.
Chaque approche a ses avantages et ses limites, et le choix dépend des exigences spécifiques de votre application, notamment des besoins de performance, de l’évolutivité et des considérations de coûts.
13 — Projet | Concevoir une architecture pour une application de commerce électronique
Ce projet se trouve ici.
14 — Projet | Concevoir une architecture pour Youtube
Ce projet se trouve ici.