
Design an Architecture for an E-commerce application
This project goal is to design a simple e-commerce application using monolitic architecture, then refactor it into microservices, and finally, propose a serverless approach for certain functionalities. This exercise aims to provide practical insights into the advantages, challenges, and use cases of each architectural style.
This project offered a good learning experience, allowing me to gain valuable insights through hands-on application. By engaging with the practical aspects of designing and implementing the architecture, I was able to better understand the complexities and nuances involved in building scalable and resilient systems.
1 - Requirements
2 - Part 1: Monolithic Architecture Design
3 - Part 2 : Microservices Architecture
4 - Part 3 : Serverless Architecture
5 - How to choose ?
Requirements
Key Features
Our application must be able to handle these operations :
- View Articles : product catalog
- Buy Articles : shopping cart and order processing
- User Registration and login
Architecture Requirements
In order to be efficient and adapt to users needs we must ensure an architecture that is :
- Scalability: The system must handle millions of users and video uploads simultaneously.
- Resilience: The system should be fault-tolerant and available at all times.
- Cost Efficiency: Optimized use of resources to balance cost with performance.
- Security: The platform must ensure secure data storage and prevent unauthorized access.
Part 1: Monolithic Architecture Design
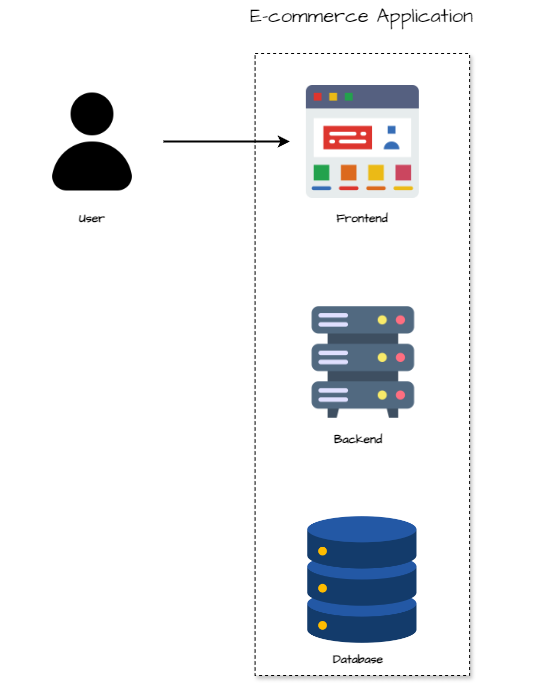
Components
The monolithic architecture follows a layered pattern where all functionalities are packaged into a single deployment unit. Here’s an overview of the architecture:
- UI Layer: Contains all the front-end components, providing the user interface for interaction.
- Business Logic Layer: Contains the core logic for each module (user management, product catalog, shopping cart, order processing). All functionalities reside in this layer.
- Data Interface Layer: A single interface to the database which contains tables for users, products, shopping carts, and orders.
Workflow
- UI Layer: This could be a web application or a mobile app.
- Users interact with the application through the UI to browse products, manage their shopping cart, and complete purchases.
- Business Logic Layer: The heart of the application containing all the functional modules.
- User Management Module: Handles user registration, login, and profile management.
- Product Catalog Module: Manages product listings, categories, and search functionality.
- Shopping Cart Module: Handles adding, removing, and updating items in the user’s cart.
- Order Processing Module: Manages order creation, payment processing, and order status updates.
- **Database
- A single database instance where all the application’s data resides.
Benefits
- Simplicity: Development is straightforward since the application is a single unit. There is a single codebase, making it easier to understand and develop.
- Uniformity: All components are part of a single deployment, making it easier to manage and deploy as there are fewer moving parts.
- Performance: Communication between components is usually faster since they operate within the same process.
- Ease of Testing: Since all functionalities are tightly integrated, testing can be simpler.
Challenges
- Scalability: Monolithic applications can be challenging to scale. To scale a monolithic app, you must replicate the entire application, which can be resource-intensive.
- Flexibility: Changes in one module can impact the entire application. It can lead to a high risk of breaking other functionalities when making changes.
- Deployment: Any update, even a small one, requires redeploying the entire application. This can lead to longer deployment times and increased downtime.
- Tight Coupling: All components are closely linked, making it difficult to isolate and develop new features independently.
Part 2: Refactoring into Microservices
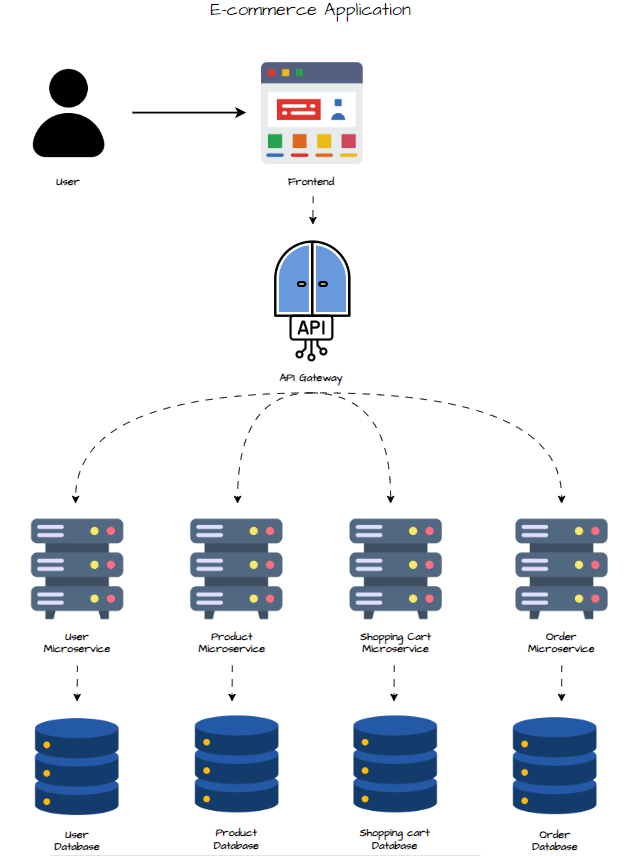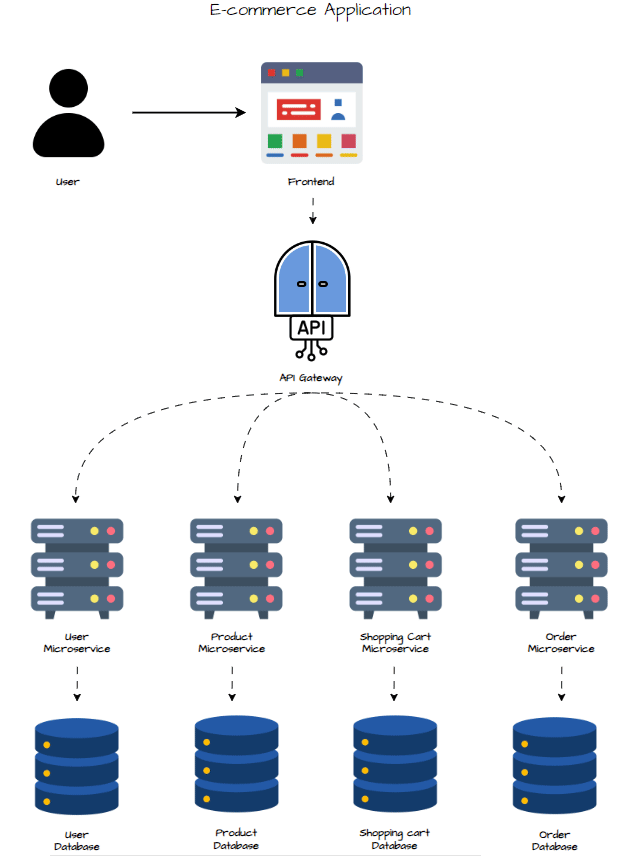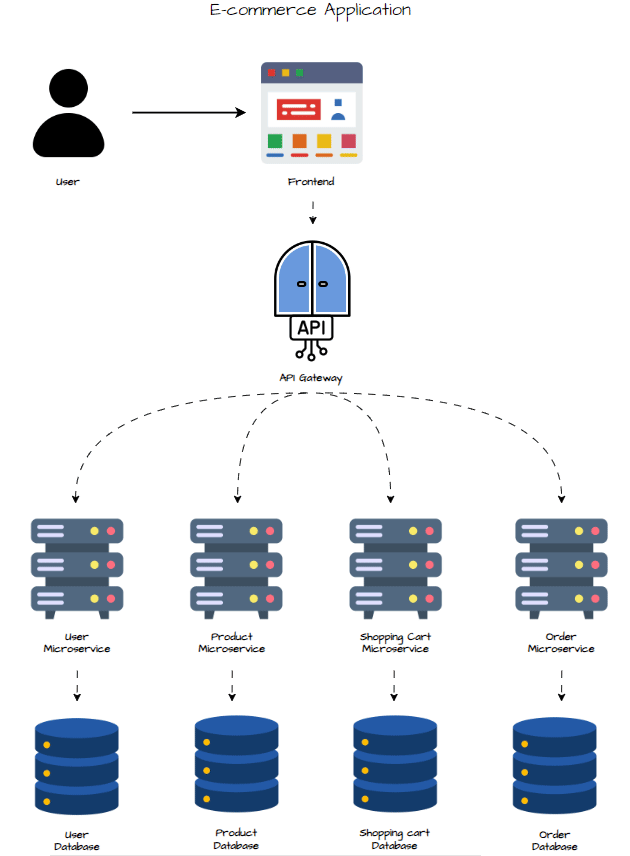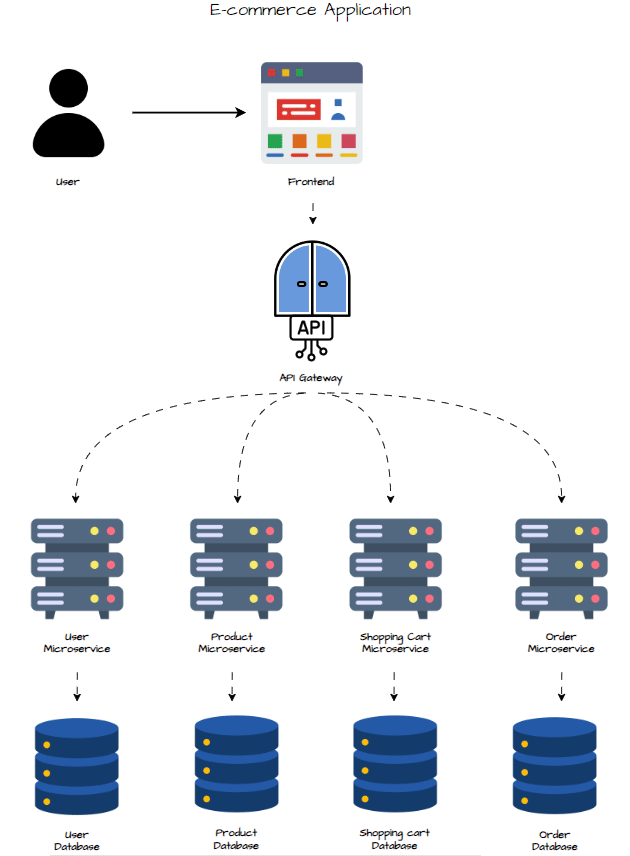
Design Microservices
To break down the monolithic architecture into microservices, we identify the core functionalities that can be isolated into distinct, independently deployable services. The e-commerce application can be divided into the following microservices:
- User Service: Manages user registration, login, and profile information.
- Product Service: Manages the product catalog, including product listings, search, and details.
- Cart Service: Manages shopping cart operations such as adding, updating, and removing items.
- Order Service: Handles order processing, including order creation, payment processing, and order tracking.
Each microservice will have its own database to ensure loose coupling and independence.
Workflow
- UI Layer : User interacts with the UI. UI sends requests to the API Gateway.
- API Gateway : API Gateway routes requests to the appropriate microservice (User, Product, Cart, Order).
- Microservices : Microservices perform their operations and communicate with their respective databases. Microservices communicate with each other when necessary. Responses are sent back through the API Gateway to the UI for user interaction.
- Database : Databases of each microservices are requested when needed.
Benefits
-
Scalability : Microservices break down the monolith into independently deployable services (e.g., User Service, Product Service, Cart Service, Order Service). Each service can be scaled independently based on its specific load. For example, if the product catalog experiences heavy traffic, only the Product Service needs to be scaled. This allows optimized resource use and cost efficiency, as services can be scaled up or down independently depending on demand.
-
Flexibility : In a microservices architecture, each service is loosely coupled and highly cohesive, focusing on a specific functionality (e.g., User Service for user management). This isolation allows teams to develop, test, and deploy each service independently, making it easier to add new features or update existing ones without affecting the rest of the system. Different microservices can use different technologies, languages, and databases, enabling teams to choose the best tools for each service.
Challenges
-
Increased Deployment Complexity: Deploying microservices is more complex than deploying a monolith because there are multiple services to manage. Each service has its own deployment pipeline, configurations, and infrastructure requirements. This complexity necessitates a robust CI/CD pipeline to handle frequent and independent deployments.
-
Cross-Service Communication: Microservices often need to communicate with each other,. This introduces challenges like network latency, service discovery, and fault tolerance. Developers must implement mechanisms for retries, fallbacks, and circuit breakers to handle potential communication failures.
-
Data Consistency: In a monolith, maintaining data consistency is straightforward since a single database is shared. However, in microservices, each service has its own database, leading to challenges in maintaining data consistency across services. For example, ensuring that inventory is updated correctly when an order is placed requires coordination between the Order Service and Product Service. Techniques like eventual consistency, distributed transactions, and the Saga pattern are used to address these challenges, but they add complexity to the system.
Part 3: Incorporating Serverless Architecture
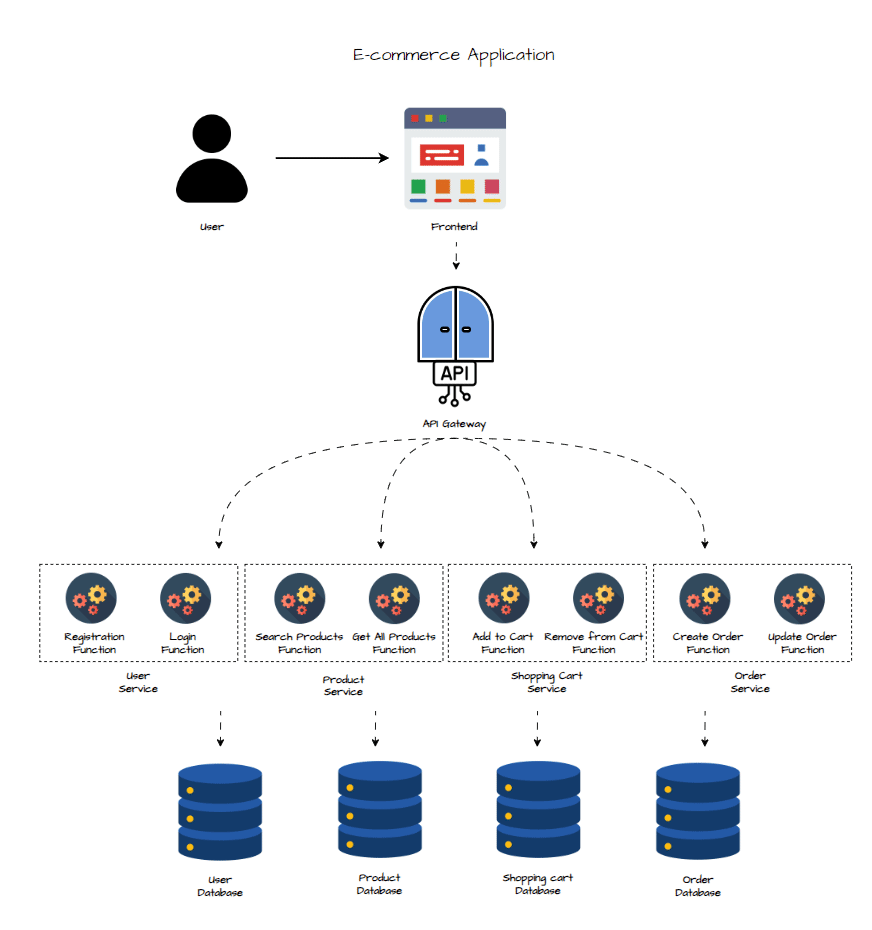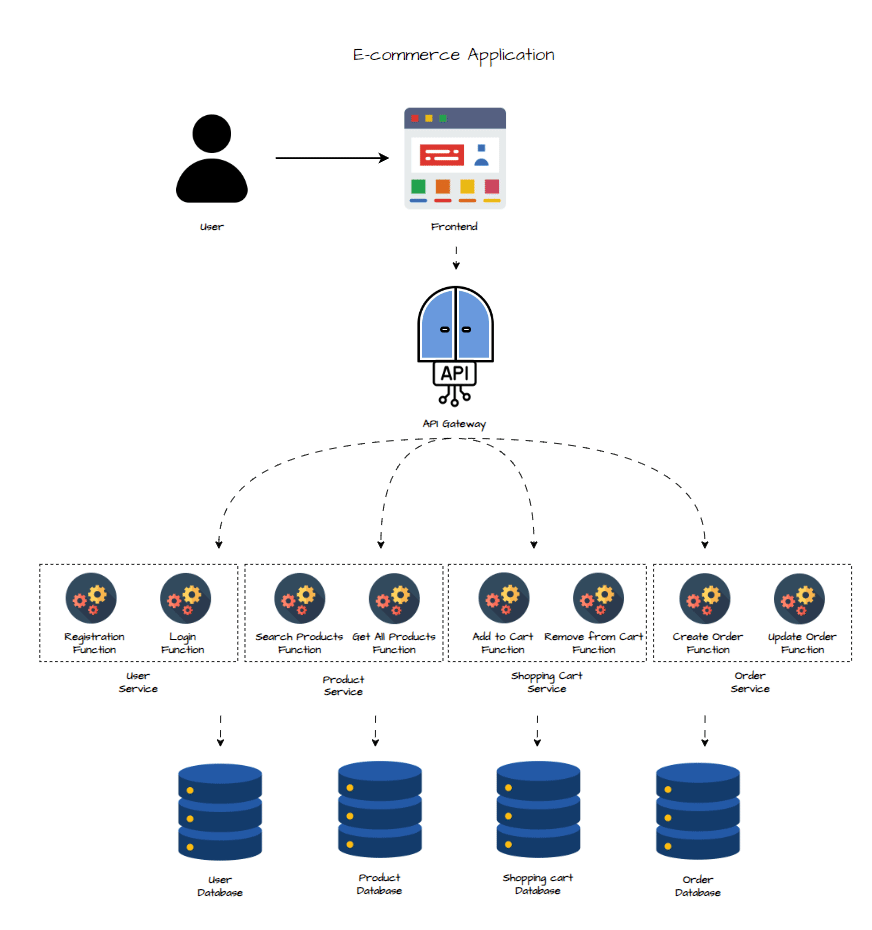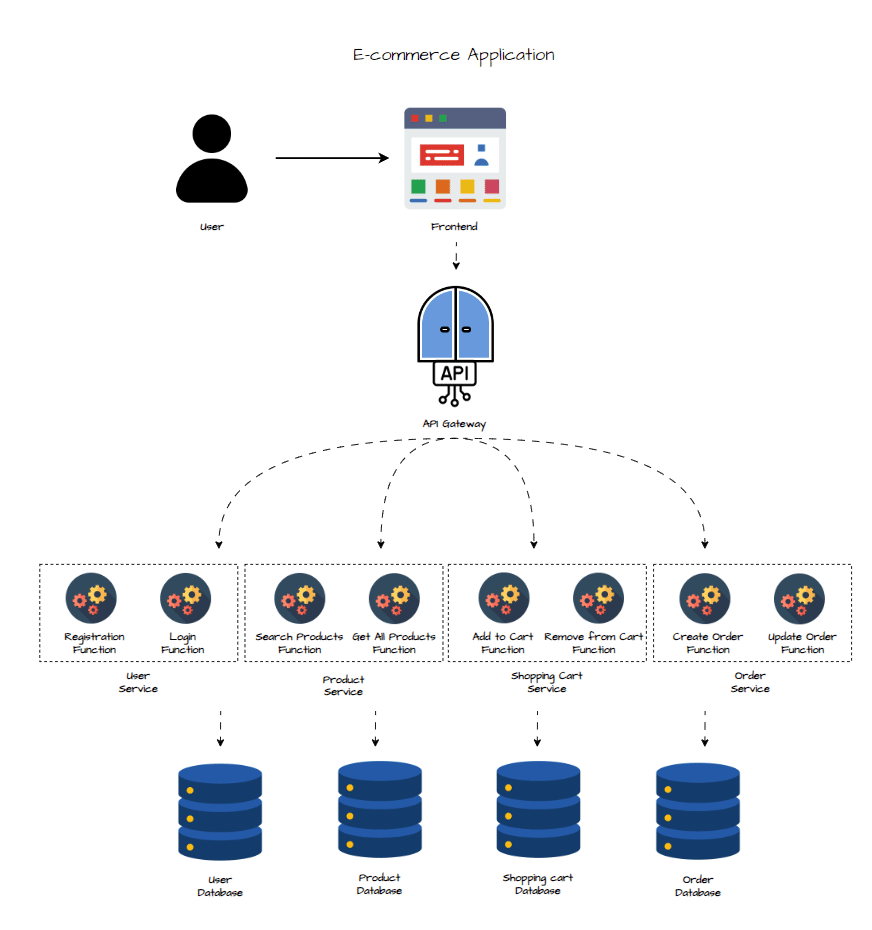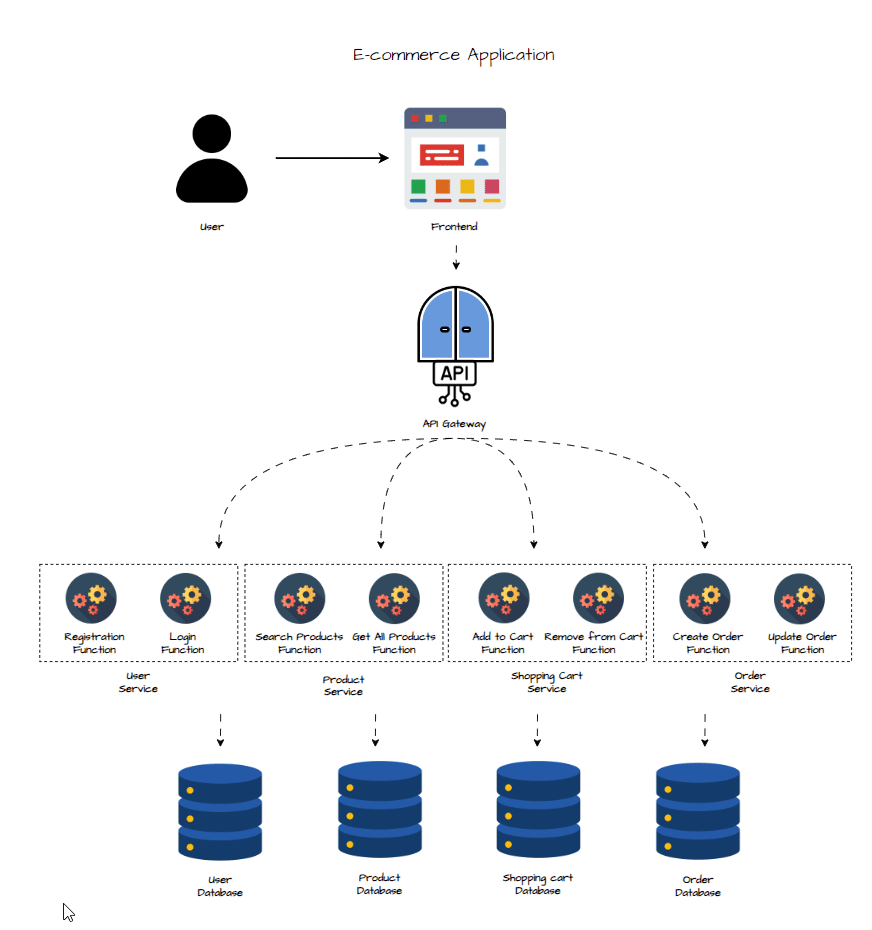
Design Functions
The architecture remains largely similar to the previous microservices design, with a key difference in how the backend is structured. In a serverless architecture, the backend is broken down into individual, fine-grained functions, each dedicated to a specific operation or action. Instead of having services composed of multiple functionalities, as in a microservices architecture, serverless decomposes these services into smaller, single-purpose functions. Each function is triggered by HTTP requests, responding directly to user interactions with the interface.
In the diagram above, not all functions are depicted for simplicity. Below is a detailed list of the serverless functions corresponding to each service:
1 - User Service :
- Registration Function : Handles user registration, storing user details in the database.
- Login Function : Authenticates users, generates tokens, and manages user sessions.
- Update User Info Function : Allows users to update their personal information.
2 - Product Service :
- Search Products Function : Handles product search queries and filters results based on user input.
- Get All Products Function : Retrieves a list of all available products.
- Add Product Function : Allows new products to be added to the catalog.
- Remove Product Function : Removes a specific product from the catalog.
- Delete Product Function : Permanently deletes a product from the database.
3 - Shopping Cart Service :
- Create Shopping Cart Function: Initializes a new shopping cart for a user.
- Add Products to Cart Function: Adds selected products to the user’s cart.
- Remove Products From Cart Function: Removes specific products from the cart.
- Validate Cart Function: Validates the cart’s contents and checks inventory before proceeding to checkout.
4 - Order Service:
- Create Order Function : Creates a new order from the validated cart, initiating the payment process.
- Update Order Function : Updates the order status and manages order tracking.
Function Interactions
Functions can call other functions to create more complex workflows. For example, the Validate Cart Function in the Shopping Cart Service might call the Create Order Function to proceed with order placement after validating the cart’s contents.
This serverless approach allows for highly modular and scalable components, where each function independently performs a specific task, allowing for fine-grained control over the application’s backend logic.
Benefits
-
Scaling: Serverless functions automatically scale with demand. When an HTTP trigger invokes a function, the cloud provider dynamically allocates resources to handle the request. This allows seamless scaling, whether the load is a single user or thousands, without the need for manual intervention. Unlike microservices, which scale entire services, serverless scales at the function level. This allows for more granular resource allocation, ensuring only the necessary parts of the application consume resources at any given time.
-
Cost: Serverless operates on a pay-as-you-go model, where you only pay for the compute time used when a function is executed. This is more cost-efficient compared to microservices, where servers need to be running constantly, even if they are underutilized.
-
Operational Management: Serverless abstracts away the server infrastructure. Developers do not need to worry about server provisioning, patching, or scaling; the cloud provider handles these aspects automatically. With serverless, developers can focus on writing individual functions rather than managing the complexities of full services. This leads to quicker iterations and deployments, enhancing agility and time-to-market.
Comparison with microservices
-
Granularity: Microservices break down the application into services that handle specific business domains, whereas serverless architecture goes a step further, decomposing these services into smaller, single-purpose functions.
-
Lifecycle and State: Microservices typically run continuously and can maintain state across requests. Serverless functions, on the other hand, are stateless and ephemeral, executing only in response to specific events (e.g., HTTP triggers).
-
Infrastructure Management: Microservices require managing infrastructure (even if containerized), whereas serverless offloads this responsibility entirely to the cloud provider.
Challenges
-
Cold Starts: Serverless functions may experience latency during the initial invocation, known as a “cold start.” This can lead to delays, particularly for time-sensitive operations.
-
State Management: Serverless functions are stateless by design, making it difficult to maintain state across function executions. Developers need to use external storage (e.g., databases, caches) to manage any stateful requirements.
-
Execution Limits: Serverless functions often have limits on execution time (e.g., AWS Lambda has a 15-minute limit), making them less suitable for long-running processes.
-
Complexity in Coordination: Breaking down services into numerous functions can introduce complexity in managing workflows and interactions between functions. This requires careful design to ensure that the system remains cohesive and manageable.
How to choose ?
In conclusion, there is no single “perfect” architecture. Each type has its strengths depending on the specific requirements of the project. The choice of architecture should be driven by the application’s unique needs. It’s not about finding a one-size-fits-all solution, but rather the best-fit solution.
So, when should we use each type?
- Monolithic Architecture is best suited for small-scale projects with consistent loads, offering simplicity and ease of development at the cost of flexibility and scalability.
- Microservices Architecture is ideal for large-scale, complex projects with a need for independent development, deployment, and scaling. It’s also effective for applications with variable loads but introduces complexity in management and maintenance.
- Serverless Architecture is well-suited for applications with variable or unpredictable loads and for small to medium-sized projects that benefit from reduced operational management. It offers cost efficiency and automatic scaling but can become complex and potentially costly for large-scale, consistently high-load applications.