Enhancing my Cloud Skills - Week 8 - DevOps
I’m relatively new to the DevOps world, having briefly worked with Azure DevOps at work. This week, I learned how DevOps is transforming the landscape of development and deployment. I had the opportunity to use GitHub Actions for the first time and integrate it with IaC and AWS. It was a really fun experience !
As I mentioned in my previous articles, I come from a background in cloud computing and software engineering, so throughout my learning journey, I will be marking new concepts with the hashtag #new. This will help highlight what’s new to me and offer readers a clearer idea of where they might find additional value — whether they’re revisiting familiar concepts or encountering fresh material themselves.
Stay tuned as I continue to document my learning process and share practical takeaways from each module!
1 - A World before DevOps
2 - What is DevOps
3 - CI/CD
4 - Continuous Integration
5 - Continuous Delivery & Deployment
6 - CI vs CD Pipeline
7 - Deployment Strategies
8 - GitHub Actions
9 - First GitHub Actions Workflow
10 - Project | CICD Pipeline For a Lambda Function
11 - Project | Testing IaC CloudFormation Template using GitHub Actions
1 - A World before DevOps
Before the advent of DevOps, traditional software development and operations practices were heavily siloed, leading to slow and cumbersome processes. These silos created communication barriers between teams, resulting in delayed releases, broken systems, and unhappy customers.
Siloed Teams
In the pre-DevOps era, development, testing (QA), and operations teams worked in isolation from each other:
- Developers would write code for months, focusing solely on adding new features.
- QA teams would test the code for months, identifying bugs and potential issues.
- Operations would be tasked with deploying large releases, often surprised by the volume of changes and the amount of new features they had to manage.
This disjointed workflow resulted in poor collaboration, miscommunication, and operational bottlenecks.
Slow Processes and Communication Barriers
The lack of communication between development, QA, and operations teams led to inefficient and slow release cycles:
- Development teams would work in isolation for extended periods, sometimes months, before handing off their code to QA.
- QA testing would take another lengthy period, as testers would have to deal with hundreds of updates and features bundled into a single release.
- Operations teams, often unaware of what was coming, would be caught off guard by the large deployments, facing unexpected challenges during production rollouts.
Inefficient Release Cycles
Releases were often slow, risky, and prone to failure. Common characteristics of the pre-DevOps world included:
- Infrequent, large releases: Releases were bundled together with hundreds of changes, often scheduled months or even years apart.
- High risk of failure: Each release posed a high risk of breaking existing systems, as it was difficult to test all changes in one go.
- Rollback challenges: When a release failed, rolling back to a previous stable version was often difficult and time-consuming, leading to downtime and customer dissatisfaction.
A manual process
The pre-DevOps world relied heavily on manual processes, which contributed to the overall inefficiency and risk:
- Manual deployments: Teams had to follow extensive checklists for each deployment, which was time-consuming and prone to human error.
- Inconsistent environments: Development, testing, and production environments often differed, leading to issues that were difficult to trace and fix.
- Version tracking challenges: Without automation, it was hard to ensure that each environment was using the correct software version, further increasing the likelihood of failures.
Operations teams, responsible for keeping the systems running smoothly, were often placed in a difficult position:
- Blocked deployments: Ops teams frequently delayed or outright blocked new deployments to avoid the risk of system outages or failures.
- Risk-averse culture: Innovation took a backseat to stability—the fear of breaking production systems stifled the pace of new feature development.
- Reliance on legacy systems: Organizations often clung to legacy systems to avoid the risks associated with updating to new versions, which in turn slowed down their ability to innovate.
Lack of Communication
The lack of collaboration and communication between developers, QA, and operations exacerbated the problems:
- Developers disconnected from production: Developers had little visibility into how their code performed in real-world environments. They were focused on adding new features and rarely dealt with the impact of their code in production.
- Operations blindsided by new features: Operations teams were often caught off guard by the changes introduced by new releases. Without a clear understanding of what was being deployed, they struggled to manage the increased complexity.
- Customers left waiting: End users had to wait for long periods to receive new features or bug fixes. Due to the lack of communication and feedback between teams, customer dissatisfaction grew as response times for addressing issues increased.
The Need for a Change
The combination of slow processes, poor communication, and manual efforts led to:
- Slow release cycles: Organizations would often take months or years to release updates, with hundreds of changes bundled into each deployment.
- High risk of failure: The size and complexity of each release increased the chances of something breaking during deployment, making it difficult to deliver stable systems.
- Lack of innovation: In an effort to avoid risk, teams were hesitant to adopt new technologies or practices, resulting in stagnation and a failure to meet evolving customer demands.
Without effective feedback mechanisms between development, operations, and the customer:
- Slow improvements: Bugs took a long time to fix, and new features took even longer to roll out.
- Unhappy customers: End users were left frustrated by the long delays in addressing issues, resulting in a poor customer experience.
The pre-DevOps era was characterized by slow, inefficient, and risky processes that led to disconnected teams and frustrated customers. The traditional approach, centered around silos and manual processes, could no longer keep up with the demand for faster, more reliable releases.
This paved the way for DevOps, a cultural and technological shift designed to bridge the gap between development and operations teams, enabling faster, safer, and more collaborative releases. By introducing automation, continuous feedback, and cross-functional collaboration, DevOps transformed the way organizations delivered software, making releases more frequent, efficient, and reliable.
2 - What is DevOps
Definition
DevOps is a set of practices that combines software development (Dev) and IT operations (Ops) with the goal of shortening the systems development life cycle and delivering high-quality software continuously. DevOps represents a cultural shift that prioritizes collaboration, automation, and shared responsibility between traditionally siloed development and operations teams.
At its core, DevOps is about breaking down the barriers between development and operations, creating a bridge that enables continuous value flow from development to deployment. It’s important to note that while tools are essential, DevOps is primarily about people and processes. By fostering collaboration, automation, and continuous feedback, DevOps enables teams to deliver better software faster, more reliably, and more efficiently.
Principles of DevOps
DevOps is driven by a set of core principles that emphasize continuous delivery, rapid iteration, and a customer-focused mindset.
Collaboration
DevOps encourages open communication and shared responsibility across the entire organization, from developers to operations and beyond. The goal is to foster a culture where teams work together toward shared goals rather than working in silos.
Breaking down walls between teams enhances transparency and encourages mutual understanding of goals and processes.
Automation
Automation is a key principle of DevOps, aiming to reduce manual intervention, thereby minimizing errors and speeding up processes. It covers everything from testing and integration to deployment and monitoring.
By automating repetitive tasks, teams can focus on higher-value work while ensuring consistent, repeatable processes.
Continuous Improvement
DevOps embraces a growth mindset where teams are encouraged to learn from failures, make incremental improvements, and abandon the fear of change.
Teams continually refine their processes, tools, and techniques based on feedback and performance data, enabling rapid iterations.
Customer-Centricity
In a DevOps culture, customers are prioritized. The goal is to deliver value to the end-users efficiently by continually releasing new features, updates, and bug fixes.
The focus is on customer feedback loops to ensure that software is constantly improving and evolving to meet user needs.
Measurement
Successful DevOps teams measure and monitor their performance using metrics and data to guide improvements.
Data-driven decision-making is a cornerstone of DevOps, allowing teams to assess the impact of changes, monitor system health, and ensure alignment with business goals.
Advantages
The adoption of DevOps offers numerous benefits to organizations, making software development faster, more reliable, and more scalable.
Faster Time to Market
By embracing continuous delivery and automation, DevOps teams can significantly reduce the time from idea to production. Frequent releases ensure that new features and improvements are delivered faster.
Better Collaboration
DevOps improves communication and collaboration across traditionally siloed departments, leading to more cohesive teams and smoother handoffs between development, testing, and operations.
Improved Reliability
DevOps practices such as continuous testing and integration help teams catch and fix issues early in the development cycle. This leads to more stable releases and a higher degree of confidence in production deployments.
Improved Security
With the integration of DevSecOps (development, security, and operations), security becomes an integral part of the development process from the very beginning. This ensures that security vulnerabilities are addressed earlier and more effectively.
Increased Scalability
DevOps practices make it easier to manage and scale complex systems. Automation allows teams to scale up infrastructure and services on-demand, ensuring that systems can handle increased traffic or workload efficiently.
Increased Developer Productivity
- By automating repetitive tasks like testing, building, and deploying, CI/CD frees up developers to focus on writing code rather than spending time on manual processes.
Higher Quality Products
Continuous feedback loops, automated testing, and constant monitoring help teams ensure that the software meets user expectations. The iterative nature of DevOps allows teams to respond quickly to changes and deliver better-quality software.
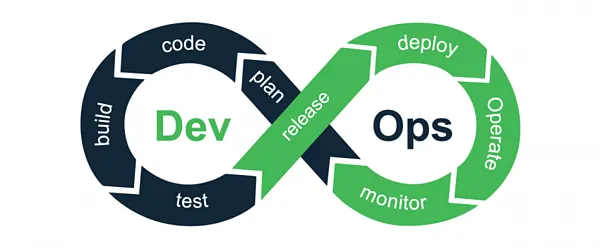
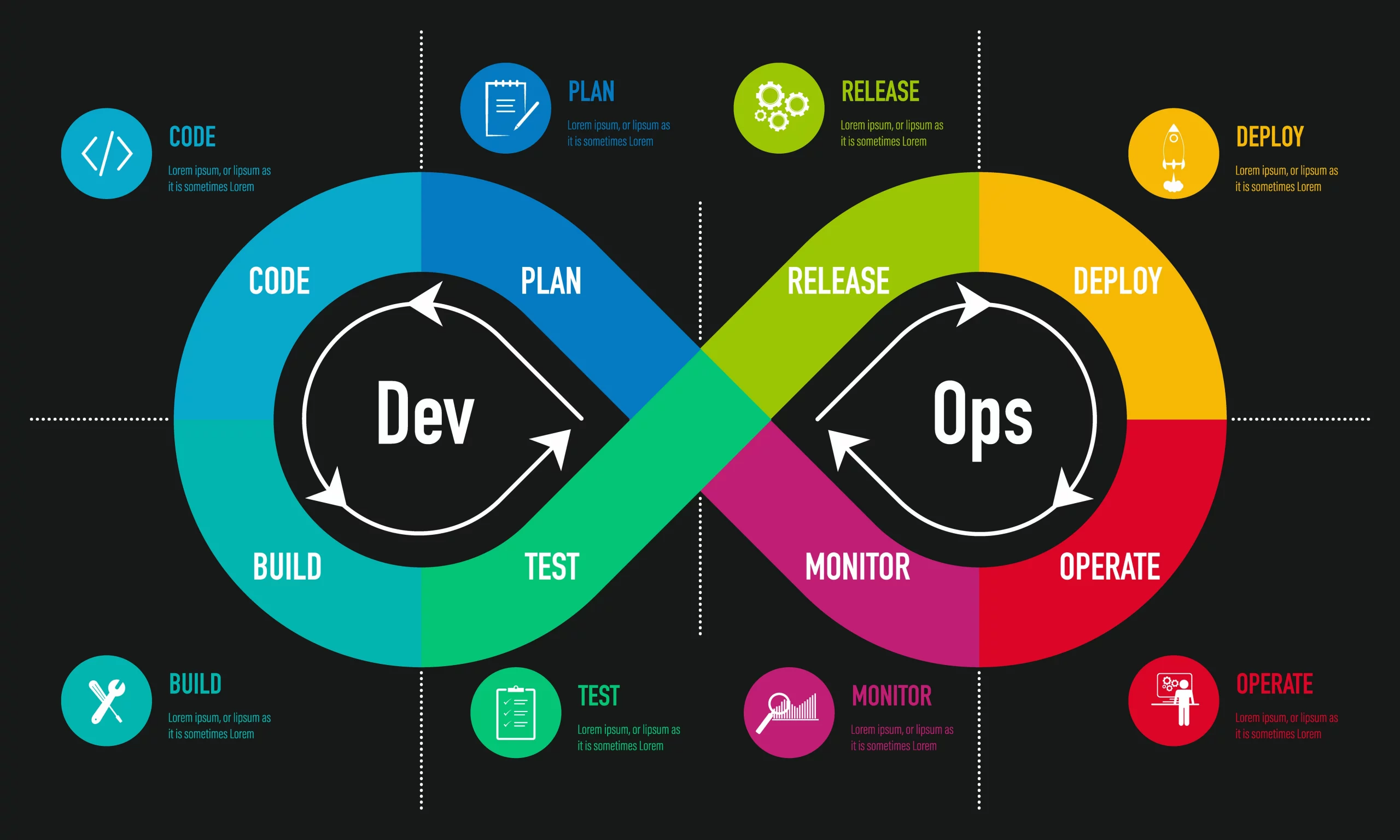
DevOps Lifecycle
The DevOps lifecycle is often represented as a continuous loop that reflects the core processes of development, integration, deployment, operations, and feedback. This lifecycle is designed to enable rapid iteration and continuous improvement.
Key Stages of the DevOps Lifecycle:
-
Plan: Teams collaborate to define new features, updates, and improvements based on business needs and customer feedback.
-
Code: Developers write the code for the new features or bug fixes. Code is stored in version control systems like Git.
-
Build: Automated build tools compile the code into a deployable format (e.g., binaries or container images).
-
Test: Automated tests (unit, integration, regression) are run to ensure that the code works as expected.
-
Release: Once tested, the code is released to production through an automated process.
-
Deploy: The new version of the application is deployed to the production environment using tools such as Jenkins, Kubernetes, or AWS CodeDeploy.
-
Operate: The system is monitored in production to ensure it is functioning properly. Teams also handle scaling, troubleshooting, and performance optimization during this phase.
-
Monitor: Monitoring and feedback loops are essential for identifying issues in real-time, ensuring the system’s health, and capturing insights for continuous improvement.
-
Feedback & Continuous Improvement: Feedback from customers and system performance data is analyzed, driving future improvements and updates to the software.
3 - CI/CD
Continuous Integration (CI)
Continuous Integration (CI) is the practice of automating the integration of code changes from multiple developers into a shared repository several times a day. Each change is automatically tested to ensure it doesn’t break the software. CI helps to identify bugs early and ensure that the codebase is always in a deployable state.
- Key Benefits of CI:
- Early Bug Detection: By merging code frequently, teams can detect and fix bugs early, reducing the risk of finding issues late in the process.
- Faster Feedback: Developers receive quick feedback from automated tests, allowing them to fix issues while they are still fresh.
Continuous Delivery (CD)
Continuous Delivery (CD) is the next step after CI, where the code is automatically prepared for release into staging environments. CD ensures that the application is always in a deployable state and that new features or bug fixes can be released at any time with minimal manual intervention.
- Key Benefits of CD:
- Faster Release Cycles: The ability to deploy code quickly and easily reduces the time between development and delivery to the end-user.
- Lower Risk: Because deployments are more frequent and smaller in scope, there’s less risk of major system failures.
Continuous Deployment
Continuous Deployment takes Continuous Delivery a step further by automatically deploying every change that passes all tests directly to production. It eliminates the need for manual approval in the deployment process.
- Key Benefits of Continuous Deployment:
- Rapid Delivery of Features: New features and fixes are deployed to production as soon as they are ready.
- Reduced Manual Work: Fully automated deployments reduce the need for human intervention, allowing teams to focus on development and innovation.
Steps
A typical CI/CD pipeline includes a series of automated steps that take code from development to production. These steps ensure that code is continuously integrated, tested, and deployed.
1. Code
- Developers write and commit code to a version control system (e.g., Git). The CI/CD pipeline is triggered every time code is pushed to the repository.
2. Build
- The code is automatically compiled and built into executable artifacts (e.g., binaries or Docker images). The build process also checks for any issues, such as missing dependencies or broken configurations.
3. Test
- Automated unit tests, integration tests, and functional tests are run to ensure that the code behaves as expected. If any tests fail, the pipeline stops, and the developer is notified to fix the issues before proceeding.
4. Deploy to Staging
- Once the code has passed all tests, it is deployed to a staging environment. This environment mimics the production environment and allows teams to conduct additional testing, such as performance tests or security tests.
5. Acceptance Testing
- In the staging environment, user acceptance testing (UAT) is performed. This step ensures that the software meets the business requirements and functions as expected for the end-user.
6. Deploy to Production
- After successful acceptance testing, the code is deployed to the production environment. If the pipeline follows the Continuous Deployment model, this deployment is fully automated, and no manual intervention is required.
4 - Continuous Integration
Key Concepts of Continuous Integration
Continuous Integration (CI) is a practice in software development where developers frequently integrate their code into a shared repository. This process is automated and followed by builds and tests to detect integration issues early and maintain code quality.
Frequent Code Integration
- Developers frequently commit their code changes to a shared version control repository (e.g., Git). Integrating code more frequently reduces the number of integration problems and allows for early bug detection.
Automated Builds & Tests
- CI pipelines automatically build the code and run automated tests every time a change is pushed to the repository. This ensures that issues are caught early and code is always in a deployable state.
Version Control
- CI relies heavily on version control systems (VCS) like Git to track code changes and ensure proper collaboration among team members. Version control allows teams to work on different branches, test features independently, and integrate those changes into the main branch.
Automated Testing
Automated testing is a key aspect of CI, allowing teams to ensure code quality and functionality with minimal manual intervention. While no application is ever truly bug-free, automated testing helps catch and fix as many issues as possible before the user experiences them.
Unit Tests
- Unit tests check individual components or functions in the code in isolation. They are typically fast and numerous and are the first line of defense against bugs.
- Goal: Ensure that each individual part of the code works as expected.
Integration Tests
- Integration tests check how different components or services interact with one another. These tests ensure that dependencies and interactions between modules are functioning correctly.
- Goal: Verify that components work well together in an integrated system.
End-to-End (E2E) Tests
- End-to-end tests simulate real user interactions and test the entire application flow, from start to finish. E2E tests are more comprehensive but also the slowest to run. These are usually reserved for testing on the main branch or major releases.
- Goal: Ensure the entire application, from frontend to backend, behaves as expected for end users.
Popular CI Tools
The choice depends on :
- the existing infrastructure
- the team preferences
- the specific project needs
Below are some of the most popular CI tools, each with its own strengths:
Jenkins
- Jenkins is an open-source automation server known for its extensive plugin ecosystem. It is highly customizable, making it a popular choice for enterprises that need to adapt the tool to their specific needs.
- Strengths: Flexibility, large community, extensive plugin support.
GitLab CI
- GitLab CI is an integrated CI/CD solution within GitLab. It offers built-in Docker support and seamless integration with GitLab repositories, allowing for smooth automation of builds and tests.
- Strengths: GitLab integration, built-in Docker support, simple setup.
GitHub Actions
- GitHub Actions is GitHub’s native CI/CD solution. It is tightly integrated with GitHub repositories, providing a straightforward way to automate workflows and setup pipelines directly from the GitHub platform.
- Strengths: Native integration with GitHub, easy workflow automation, user-friendly interface.
CI Pipeline Architecture
A CI pipeline is a series of automated steps that help ensure code quality and seamless integration into the main codebase. These pipelines ensure that changes are properly integrated, tested, and reported before moving to production or other environments.
1. Source Control
- The first step in the pipeline is integrating the CI tools into the source control system (e.g., Git). This allows the CI tool to automatically detect changes in the codebase when developers push code to the repository.
2. Build
- The next step is to compile the code, resolve dependencies, and create artifacts (e.g., binaries, containers) necessary for deployment. The build process is fully automated and ensures that the code is in a deployable state.
3. Test
- After the build step, the pipeline automatically triggers the test stage. Unit tests, integration tests, and other automated tests are run to ensure that the code behaves as expected. If any tests fail, the pipeline stops and notifies the developers.
4. Report
- Once the tests are complete, the pipeline generates a report. The status of the build and test stages is shared with the team, ensuring that the right people are notified (via email, Slack, or other channels) of the pipeline’s success or failure.
5 - Continuous Delivery and Deployment
Continuous Delivery (CD) and Continuous Deployment (CD) are key practices within DevOps that ensure software is always in a deployable state and can be released to production reliably and quickly.
Continuous Delivery
Continuous Delivery ensures that the application is always in a deployable state, meaning that every code change passes through a series of automated tests and is ready to be released to production at any time. However, in this model, the deployment to production requires manual approval. This provides an extra layer of control, allowing teams to decide when the release is made.
- Key Aspect: Every change is tested and integrated but waits for manual intervention before being deployed to production.
Continuous Deployment
Continuous Deployment takes automation one step further by automatically deploying every change that passes through all stages of the pipeline to production without manual approval. This practice ensures that new features, updates, and bug fixes are delivered to end-users as soon as they are ready.
- Key Aspect: Changes are automatically pushed to production without any manual approval, ensuring a fast and constant stream of updates.
Key Concepts in Continuous Delivery and Deployment
Both Continuous Delivery and Continuous Deployment aim to enhance software delivery through automation, reliability, and speed. Here are the core concepts:
Automation of the Release Process
- The entire pipeline, from code integration to testing and deployment, is automated. This reduces the chances of human error and increases the speed of delivering software.
- Continuous Delivery automates the process up to the production stage but requires manual approval for the final release.
- Continuous Deployment automates the entire process, from code changes to deployment in production.
2. Deployment Pipeline
- A deployment pipeline is the set of automated processes that take code from development through testing and into production. Every change to the code is automatically tested, validated, and, depending on the model, deployed into production.
- The pipeline ensures that only changes that pass all tests and validations make it to production, increasing the reliability of the releases.
3. Production-like Environments
- Continuous Delivery and Deployment require a staging or production-like environment where code changes can be tested before deployment. This ensures that code is tested under real-world conditions, reducing the risk of bugs or issues in production.
4. Continuous Monitoring and Feedback
- Once the code is in production, it is essential to continuously monitor the system for any issues. Automated monitoring tools are used to detect performance bottlenecks, bugs, or failures.
- The feedback loop is crucial, as it provides data that can be used to improve the software and the pipeline itself.
Continuous Delivery vs. Continuous Deployment
| Key Differences | Continuous Delivery | Continuous Deployment |
|---|---|---|
| Definition | Ensures code is always in a deployable state but requires manual approval for production releases. | Automatically deploys every change that passes the pipeline to production. |
| Manual Approval | Yes, manual approval is required before production deployment. | No, fully automated. Changes are deployed directly to production. |
| Deployment Frequency | Frequent, but not necessarily after every code change. | Can happen multiple times a day, after each successful build. |
| Use Case | Teams that want control over production releases but still automate the testing and integration phases. | Teams that want to automate the entire pipeline and deliver changes as soon as they are ready. |
| Risk | Lower risk, as changes can be manually reviewed before production. | Slightly higher risk, but mitigated by frequent, small releases and extensive testing. |
6 - CI VS CD Pipeline
CD Extends CI to automate the entire software release process.
Stage => Deploy in an environment that closely mimics the productions one. Review => Manual Aprovement
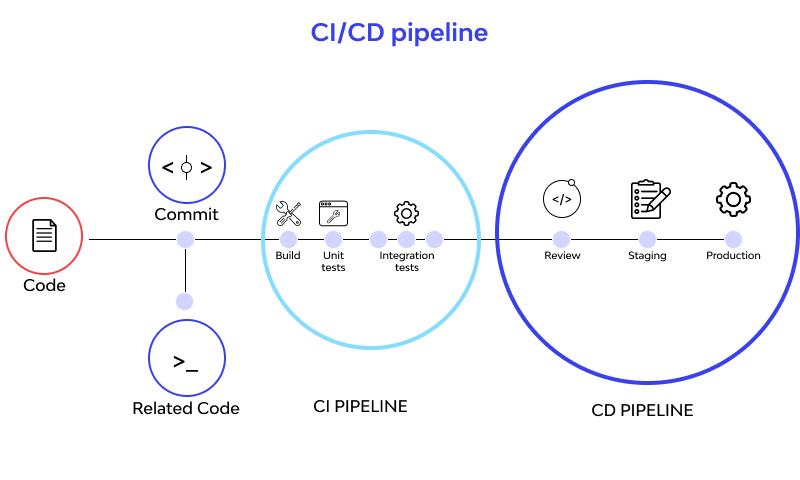
https://blog.openreplay.com/what-is-a-ci-cd-pipeline/
7 - Deployment Strategies
Deployment strategies determine how new code changes are released to a live production environment. Choosing the right strategy depends on several factors, including:
- The nature of the application: How critical is uptime, and how sensitive is the application to updates?
- The client’s risk tolerance: How much disruption can be tolerated by the user base during deployment?
- The infrastructure’s architecture: Does the infrastructure support multiple environments, and can it handle rolling updates?
Each strategy has its strengths and trade-offs, making it important to choose the right one for your specific use case.
Blue-Green Deployment
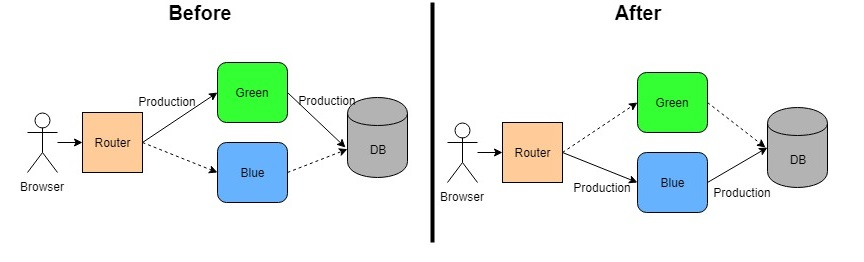 https://dzone.com/articles/blue-green-deployment-for-cloud-native-application
https://dzone.com/articles/blue-green-deployment-for-cloud-native-application
Definition
Switch between two identical envrionements. One serves traffic while the other is updated.Blue-Green Deployment involves switching between two identical environments, blue and green, for production traffic. At any given time, one environment serves live traffic while the other is updated. Once the new environment is tested and confirmed to be stable, the router switches traffic to it.
- The Blue environment serves production traffic.
- The Green environment is where updates are applied and tested.
Once the green environment is fully prepared and tested, the router switches all traffic to the green environment, making it the new live environment. If issues are detected post-switch, the router can be reverted back to the blue environment for immediate rollback.
Advantages
- Zero downtime during deployment: Since both environments are live, switching traffic happens instantly with no service disruption.
- Easy rollback: If any issues are found in the new environment, you can switch back to the original environment almost immediately, minimizing downtime and risk.
Drawbacks
- Resource-heavy: Requires double the infrastructure since you need to maintain two production-like environments, which increases costs and resource utilization.
Canary Deployment
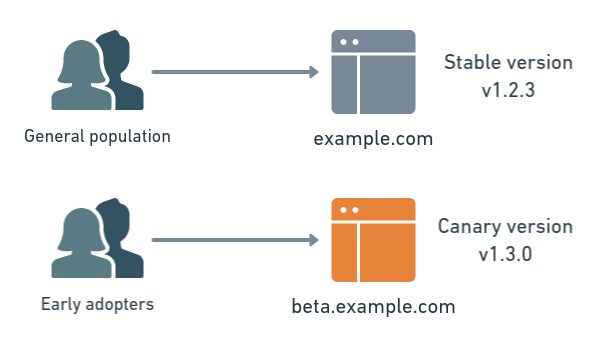 https://semaphoreci.com/blog/what-is-canary-deployment
https://semaphoreci.com/blog/what-is-canary-deployment
Definition
Release to a small subset of servers or users, then gradually increaseCanary Deployment releases new changes to a small subset of users or servers first. The idea is to gradually introduce the update. If everything works as expected, the new version is gradually rolled out to more users or servers until the entire user base is using the new version.
- Initially, only 10% of the users or servers might receive the new version.
- If no issues are found, more servers or users are updated until 100% deployment is reached.
If any issues are detected during this gradual rollout, the deployment can be stopped, and the previous version can be rolled back, preventing the issue from affecting the entire user base.
Advantages
- Risk mitigation: Since only a small portion of the user base or servers receive the update initially, it allows for early detection of issues before they impact everyone.
- Controlled feedback: This gradual release provides useful feedback from real users without exposing the entire application to potential bugs or failures.
Drawbacks
- Slower deployment: The incremental nature of Canary Deployments can make the overall deployment process slower compared to Blue-Green or Direct Deployments.
- Complex traffic management: It can be challenging to manage traffic and allocate different percentages of users or servers dynamically during rollout and rollback scenarios.
Direct Production Deployment

Definition
Deploy changed directly to production after passing all tests.In Direct Production Deployment, code changes are deployed directly to the live production environment once they pass all tests. This is a straightforward approach where changes are instantly applied to the production system without deploying to a staging environment first.
This strategy is often used in simpler applications or when resources are limited, making it the fastest and most resource-efficient method.
Advantages
- Fastest deployment: No need for additional environments or complex traffic management, making this the quickest way to get new code into production.
- Lower infrastructure costs: Since there are no parallel environments to maintain, this method requires fewer resources.
Drawbacks
- High risk: Since changes go live immediately, any issues in the new code can cause significant disruptions in production. There’s also no easy rollback without downtime.
- No safety net: In the event of failure, there’s no backup environment to switch to, making recovery more challenging.
Conclusion
Different strategies suit different types of applications, infrastructures, and business needs. In practice, many companies use a combination of these strategies based on the scale and impact of the release.
- Blue-Green Deployment is ideal for major releases that require zero downtime and minimal risk of rollback. It’s often used for mission-critical systems where uptime is paramount.
- Canary Deployment is preferable when you want to validate the new code with real users and closely monitor how it interacts with the application. This is typically used in systems where user experience is crucial, and any impact should be minimal.
- Direct Production Deployment is best for small teams or startups with limited resources or for applications that are low-risk and easy to roll back if issues arise. It’s fast, simple, and cost-effective.
| Strategy | Use Case | Advantages | Drawbacks |
|---|---|---|---|
| Blue-Green | Major releases, mission-critical systems | Zero downtime, easy rollback | Requires double the infrastructure, higher resource cost |
| Canary | Gradual release, user feedback validation | Risk mitigation, early issue detection | Slower process, complex traffic management |
| Direct Production | Small projects, low-risk changes | Fast, cost-effective | High risk, no easy rollback |
By tailoring the deployment strategy to the specific needs of your system and application, teams can minimize risks while ensuring fast, reliable software releases.
8 - GitHub Actions
GitHub Actions is an automation platform that allows you to automate your entire software development workflow directly from your GitHub repositories. It goes beyond being just a CI/CD tool, offering a full suite of automation capabilities to handle various phases of the development lifecycle.
GitHub Actions integrates seamlessly with the entire development process, enabling you to automate everything from planning and coding to deployment and monitoring.
Software Workflow
Plan
- GitHub Actions can integrate with tools like Trello or Jira to automate the management of tasks. It can automatically create tasks, update project boards, or trigger notifications based on repository events like issue creation or pull request merges.
Code
- Automate code reviews using pre-built actions for code analysis and linting.
- GitHub Actions can autoformat code upon commit, ensuring code consistency and quality from the start.
- It runs linters to detect potential errors and improve the overall quality of the codebase before it’s even built.
Build
- GitHub Actions automatically compiles the code, runs unit tests, and creates build artifacts. This ensures the codebase is always in a buildable state and that broken builds are caught early.
- It supports building projects in various languages and frameworks, allowing for flexible configurations.
Test
- Automate testing on every push or pull request, ensuring that every change is thoroughly tested before being merged into the main codebase. This includes running unit tests, integration tests, and end-to-end tests.
Deploy
- GitHub Actions handles automated deployments to different environments, making the process consistent and repeatable. Whether deploying to AWS, Azure, Google Cloud, or self-hosted environments, GitHub Actions simplifies the release process.
Operate
- Helps manage infrastructure by integrating with tools like Terraform or Ansible. It ensures your Infrastructure as Code (IaC) is always up-to-date, maintaining consistency across environments.
Monitor
- GitHub Actions integrates with monitoring tools to trigger automated responses to incidents. It can create issues for flagged instances, automatically respond to alerts, or even roll back deployments when necessary.
Key Features
Integrated CI/CD
GitHub Actions allows you to build complex CI/CD pipelines directly within your repository. You can automate the entire development lifecycle, from code integration to testing and deployment, all in one place.
Workflow Automation
Automate workflows in response to specific repository events like pull requests, pushes, or issue creation. This level of automation enhances productivity by reducing manual tasks.
Multi-environment support
GitHub Actions supports running workflows on different operating systems (Linux, macOS, Windows) and different software versions, enabling comprehensive testing across multiple environments.
Reusable Actions
Use pre-built actions from the GitHub Marketplace or create your own custom actions to enhance workflow efficiency. These reusable actions help speed up development by automating repetitive tasks.
Secure Secrets Management
Safely store and use sensitive information like API keys, passwords, and tokens within workflows without exposing them. Secrets are encrypted and only made available to the workflows that need them.
Workflow Components
GitHub Actions workflows consist of several key components that determine how and when automation is triggered.
Events
When should this workflow run ?Events are triggers that define when a workflow should run. For example, you can set a workflow to trigger:
- When a commit is pushed to a specific branch.
- When a pull request is opened or merged.
- On a scheduled basis, like nightly builds.
Jobs
Jobs are a set of steps that execute on the same runner. A job represents a unit of work within a workflow.
- For example, you can have separate jobs for building, testing, and deploying an application.
- Jobs can be run sequentially or in parallel depending on dependencies between them.
Runners
Runners are the execution environments where the jobs run. They provide the necessary computing resources (CPU, memory, etc.) to execute the workflows.
- GitHub offers self-hosted runners or GitHub-hosted runners (cloud-based).
- You can choose to run workflows on specific platforms (Linux, macOS, or Windows).
Steps
Steps are the individual tasks that run within a job. They are executed in a specified order, and steps can share data and artifacts between each other.
- Examples include checking out code, setting up environments, running commands, and saving artifacts.
- Each step can either use an action or run a shell command directly.
Actions
Actions are reusable units of code designed to perform specific tasks. They act as the building blocks of GitHub workflows and can be created by anyone or obtained from the GitHub Marketplace.
- Examples of actions include running tests, deploying code, or sending notifications.
9 - GitHub Actions Workflow Example
The Workflow must be defined in a GitHub repo inside .github/workflows/main.yaml
name: My GitHub Actions Workflow
on: [push]
jobs:
testing_github:
runs-on: ubuntu-latest
steps:
- name: Hello
run: echo "Hello, world!"
- name: Display repo name
run: echo "This repo is $GITHUB_REPOSITORY"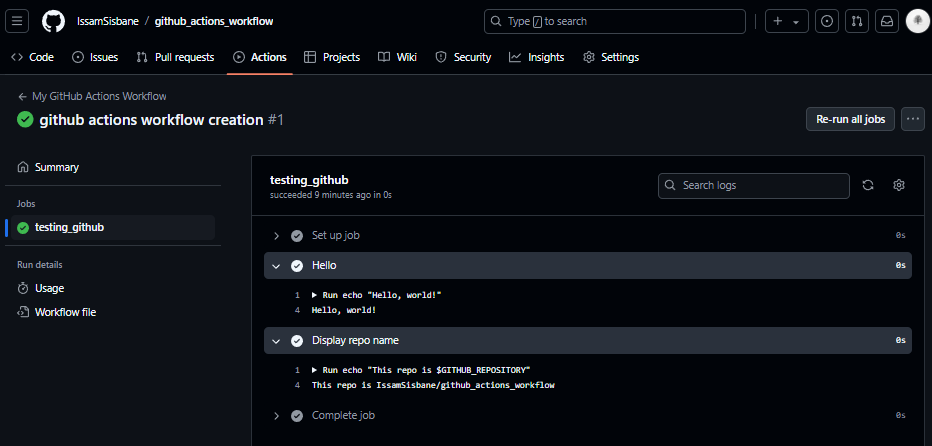
This is a very simple workflow, running some echo command in the runner cli.
10 - Project | CI/CD Pipeline For a Lambda Function
1 - Overview
The goal of this project is to update an existing lambda Function when code is push in a repository. Secrets will be used to authenticate github actions to AWS to deploy our lambda function.
Runner :
- Checks out the code from the repository
- Setup python envrionement and install dependencies
- Configure aws credentials
- Package up our lambda
- Deploy the lambda to aws
We will create the lambda from aws console to speed up things.
2 - Steps
1 - Create a new GitHub repo
Using GitHub website.
2 - Create a new actions secret
We need to securely store our aws credentials to authenticate our pipeline with aws.
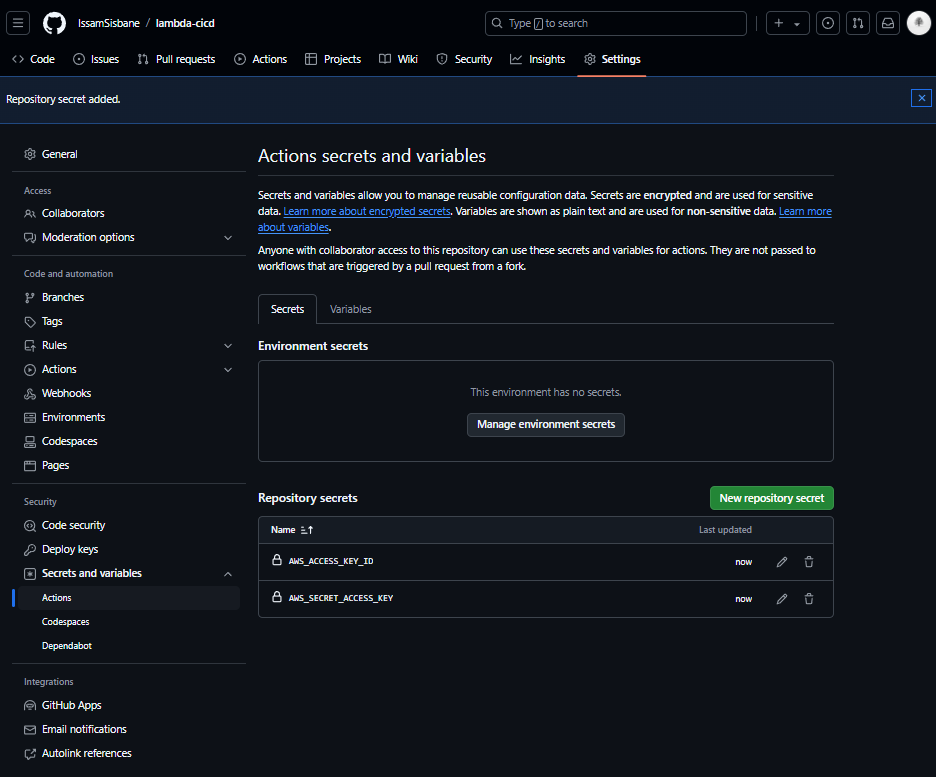
3 - Create the lambda function
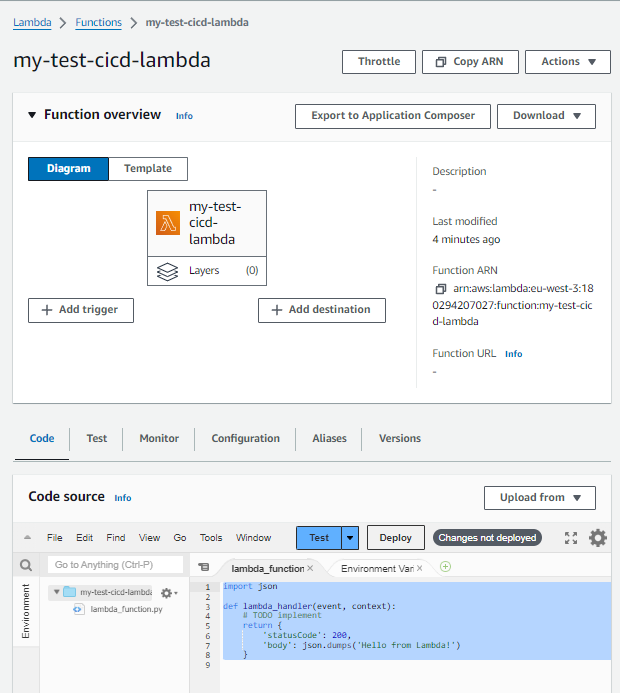
4 - Add code to our repo for the lambda
Initially, the code of the lambda simply print “Hello from Lambda” in response of HTTP Request. We want to change this behavior using our pipeline to update the code.
import json
def lambda_handler(event, context):
# TODO implement
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}Best practice is to always include a requirements.txt file for python dependencies.
We add the code for our pipeline in .github/workflows/lambda.yaml
name: Deploy AWS Lambda
on:
push:
branches:
- main
paths:
- "lambda/*"
jobs:
deploy-lambda: # Job name
runs-on: ubuntu-latest # Specify the runner
steps:
# 1 - Checkout and get the code in the runner environment
- uses: actions/checkout@v2
# 2 - Set up Python environment
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: "3.12"
# 3 - Install dependencies
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r lambda/requirements.txt
# 4 - Setup AWS credentials
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@v2
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: eu-west-3
# 5 - Zips the lambda code and updates the lambda function
- name: Deploy Lambda
run: |
cd lambda
zip -r lambda.zip .
aws lambda update-function-code --function-name my-test-cicd-lambda --zip-file fileb://lambda.zipWe can update our code to :
import json
def lambda_handler(event, context):
# TODO implement
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda changes made from vscode!')
}5 - Commit & Push
We commit and pushes the changes which will trigger the pipeline :
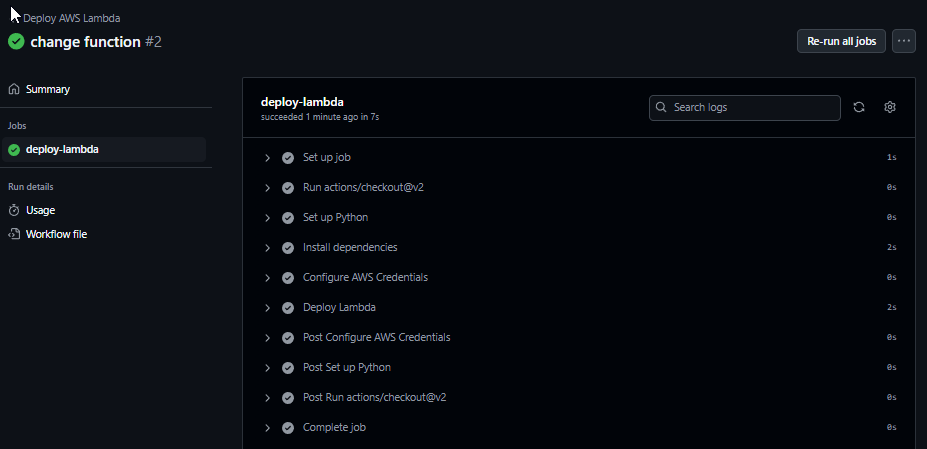
3 - Verification
Then if we go to the aws console we can seen that the code has been updated :
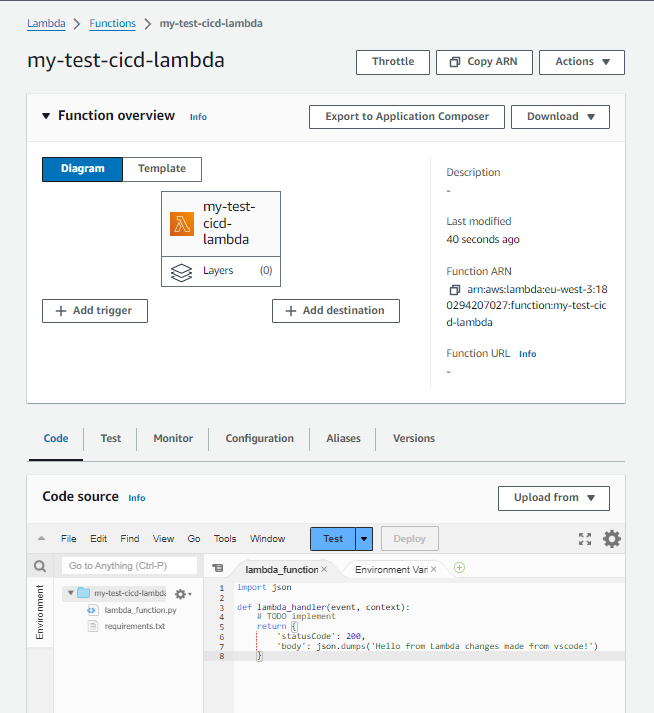
It’s a success, we updated our function using GitHub Actions Pipeline. We can now delete our function.
11 - Project | Testing IaC CloudFormation Template using GitHub Actions
1 - Overview
This project is focused on creating a GitHub Actions Workflow that automates the process of creating an S3 bucket using a CloudFormation template and testing it within a Pull Request (PR). The goal is to validate if the CloudFormation template is correctly written and functional before merging the PR into the main branch.
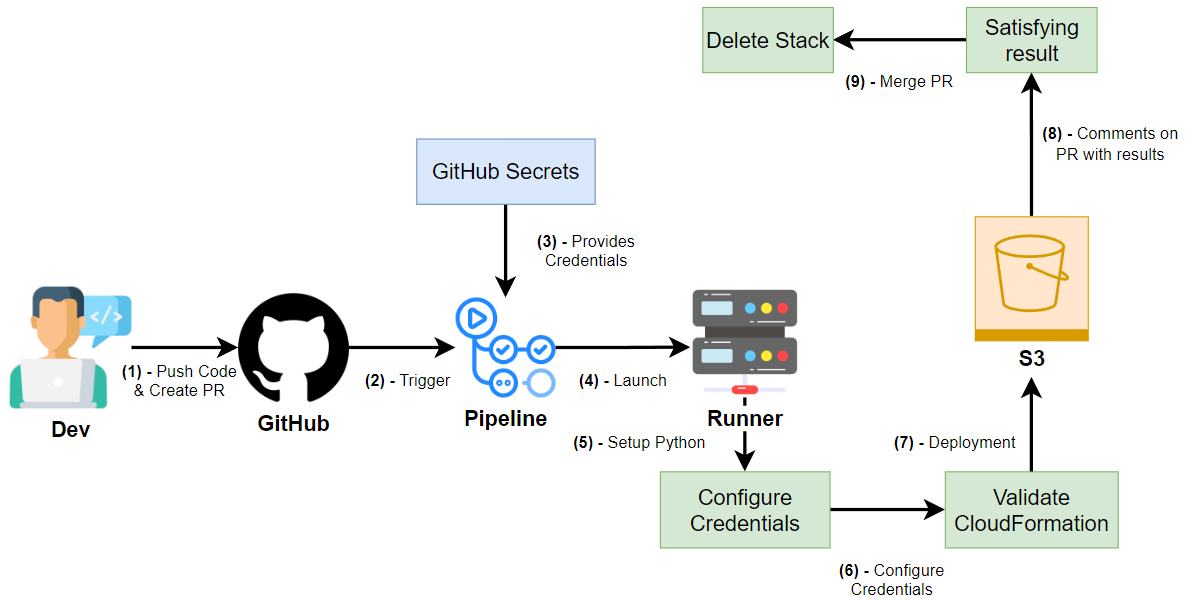
- Once the developer creates a pull request to merge into the main branch, the workflow will:
- Use the CloudFormation template to create an S3 bucket.
- Post the result of the CloudFormation operations in the PR discussion, along with the bucket name.
- Upon merging the PR, the workflow will delete the stack (and the S3 bucket), cleaning up the resources.
This workflow allows us to test the CloudFormation code within the pull request before it’s merged into the main branch. It ensures that the infrastructure code is working properly and prevents errors from being deployed in production.
In a production environment, a separate workflow triggered on the main branch would handle deploying the stack to the production environment.
We will be using the GitHub repository as our previous project.
2 - Steps
Step 1: Creating a Pull Request
Once a new branch is created, the developer will create a pull request (PR). This triggers the workflow to start, which will attempt to create an S3 bucket using the provided CloudFormation template.
Step 2: Error Handling
During the first run of the workflow, an error was detected in the CloudFormation template due to incorrect indentation.
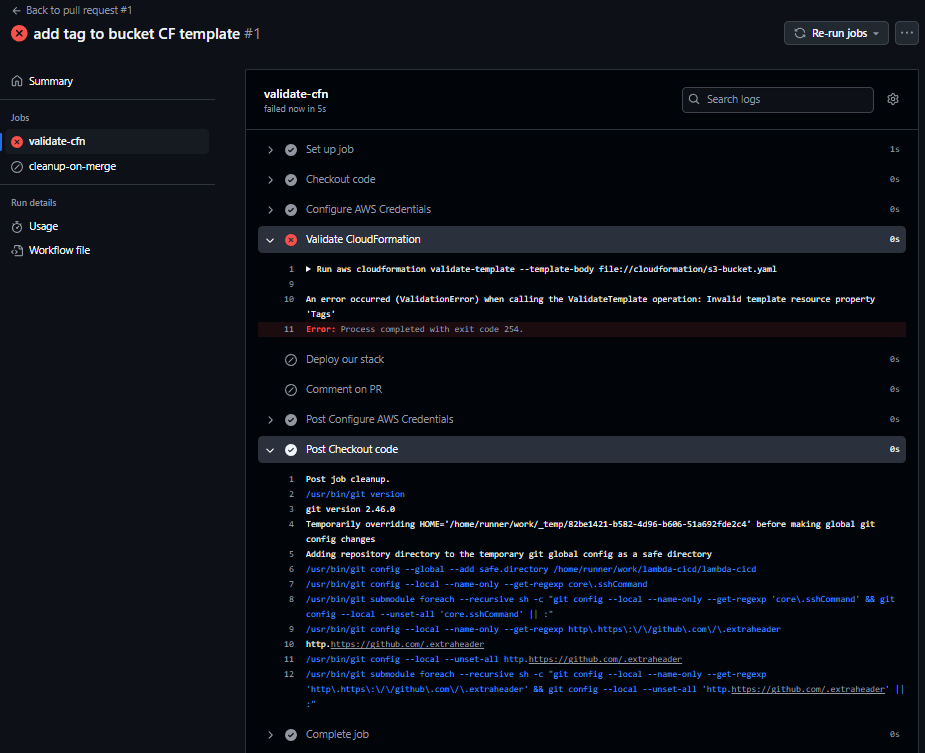
- The error logs indicated a problem in the template’s structure, and after fixing the indentation issue, the workflow was triggered again.
Step 3: Successful Validation and Creation
After correcting the error, the pipeline executed smoothly. The S3 bucket was successfully created, and the PR discussion was updated with the validation results, including the name of the bucket created.
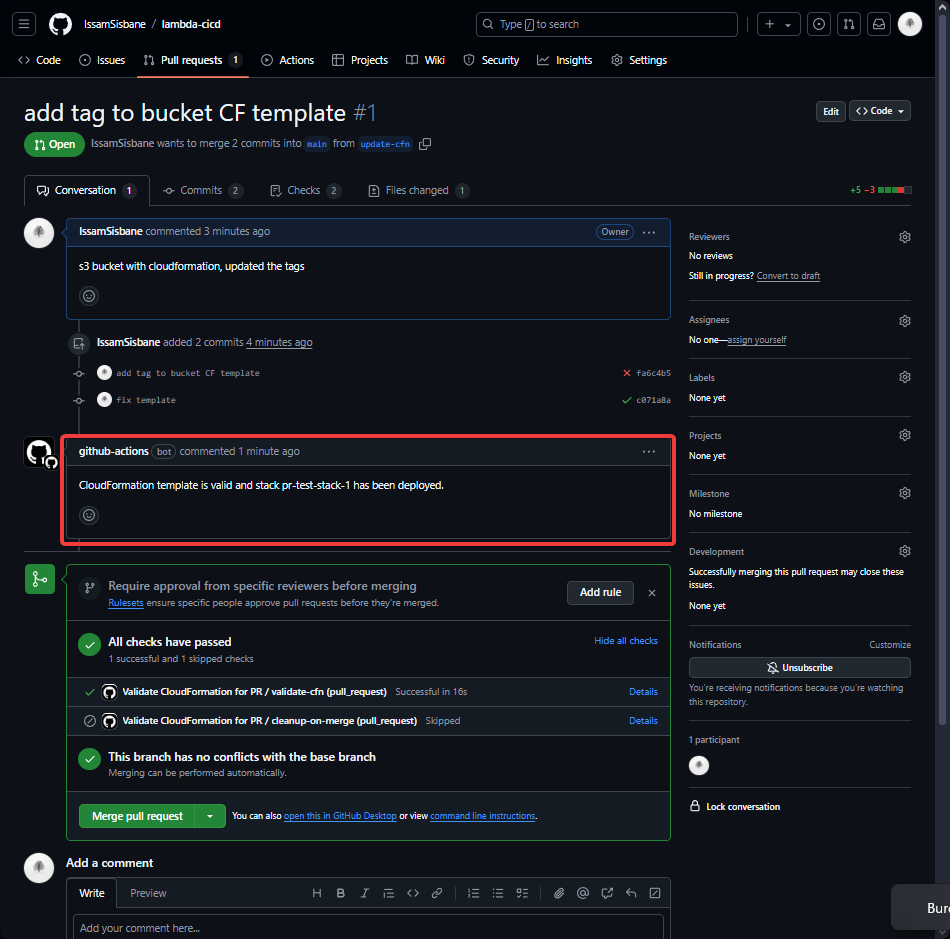
- CloudFormation Stack created successfully:
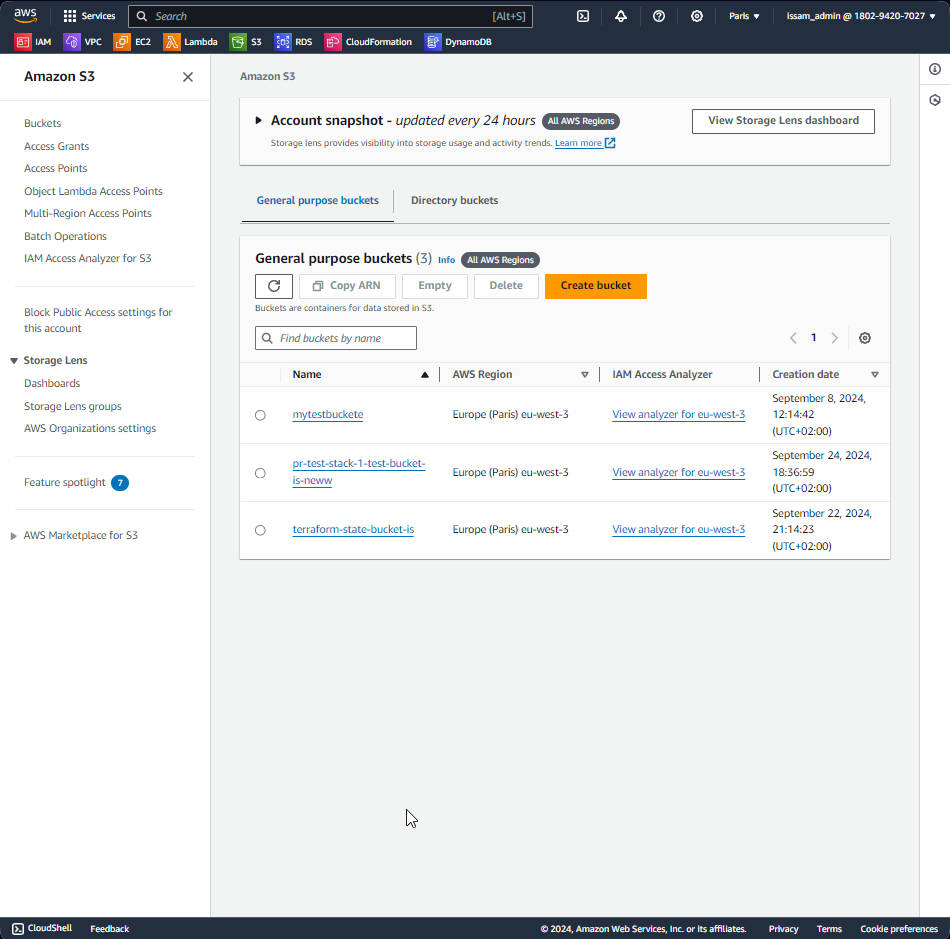
- S3 Bucket created as expected:
Step 4: Cleanup Process Fails to Trigger
However, we noticed that after merging the pull request, the cleanup job (responsible for deleting the stack and the S3 bucket) did not run. To resolve this, we had to update the workflow configuration.
Step 5: Workflow Configuration Update
To fix the issue and ensure that the cleanup job runs after merging the PR, we added the following configuration to the workflow file:
on:
pull_request:
paths:
- "cloudformation/**"
types: [opened, synchronize, reopened, closed]This ensures that the workflow triggers on specific PR events (opened, synchronized, reopened, and closed) and only for files in the cloudformation/ directory.
Step 6: Preventing the Validation Job from Running on Merge
Additionally, we updated the validate-cfn job to avoid running the CloudFormation validation when the PR is merged. We added the following condition to skip this step when the PR is merged:
jobs:
validate-cfn:
if: github.event.pull_request.merged == falseThis ensures that the validation job only runs for unmerged PRs, preventing unnecessary execution after the code is already merged.
Step 7: Successful Cleanup Job Execution
After applying the fixes, the workflow executed correctly, and the cleanup job successfully ran after merging the PR. The stack and S3 bucket were deleted as expected.
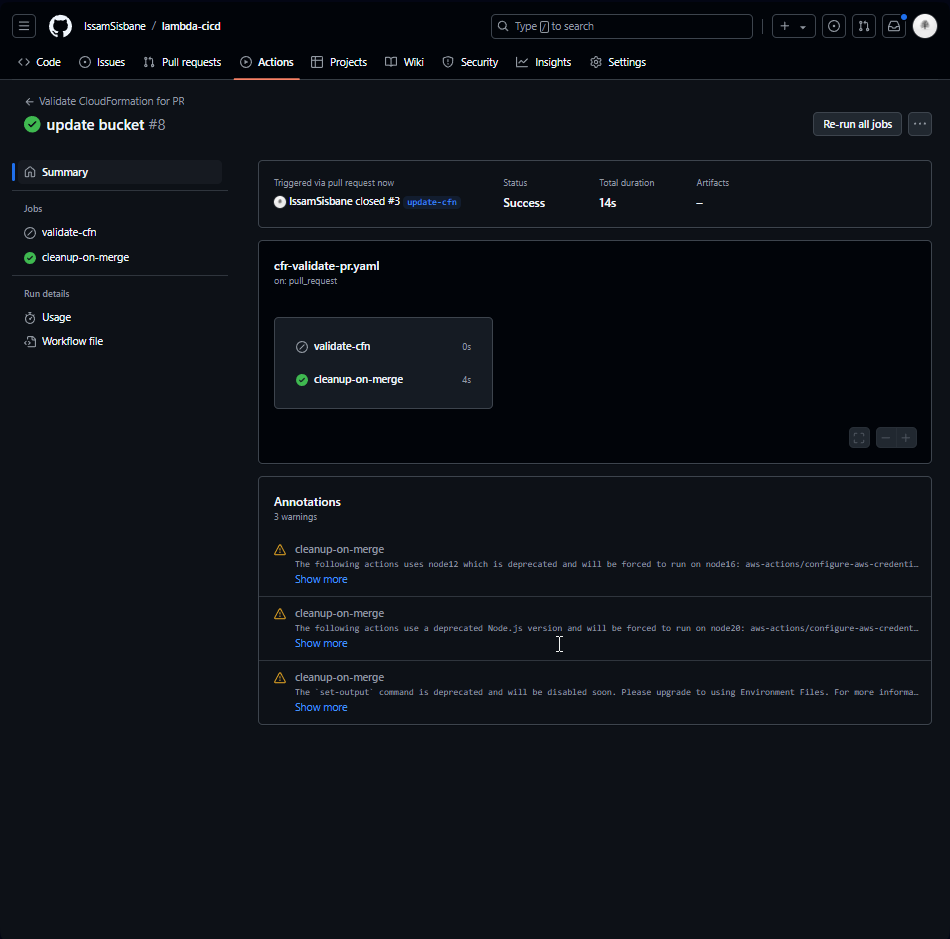
Finally, everything worked as intended, and the resources were cleaned up once the pull request was merged. After creating a new branch and create a pull request, our workflow started and found an error in our Cloudformation template.
3 - Conclusion
This project showcases the power and flexibility of GitHub Actions when combined with CloudFormation for automating infrastructure tasks. By integrating this workflow into the development process, we can:
- Validate infrastructure code within pull requests.
- Ensure infrastructure correctness before merging into the main branch.
- Automatically create and delete resources, keeping the environment clean.
In a real production environment, we would likely use a more robust deployment strategy with separate workflows for staging and production environments, ensuring a smooth and reliable infrastructure deployment process.
This setup also demonstrates how automating infrastructure validation and cleanup processes can help ensure that infrastructure changes are safe, repeatable, and manageable across different environments.
It was interesting to see how we can validate IaC before merging to the main branch. I never thought of this way before.