
Enhancing my Cloud Skills - Week 3 - System Design Applications
The focus for this week is broad, covering topics from fundamental architectural types to the intricacies of cloud storage, caching, and load balancing. I will explore critical architectural patterns like monolithic, microservices, and serverless architectures, understand how APIs function as communication bridges, and examine the three-tier architecture model that lays the foundation for scalable and maintainable applications.
This multifaceted approach not only helps in consolidating my cloud knowledge but also offers hands-on experience through practical projects.
As I mentioned in my previous article, I come from a background in cloud computing and software engineering, so throughout my learning journey, I will be marking new concepts with the hashtag #new. This will help highlight what’s new to me and offer readers a clearer idea of where they might find additional value — whether they’re revisiting familiar concepts or encountering fresh material themselves.
Stay tuned as I continue to document my learning process and share practical takeaways from each module!
1 - Monolitic Architecture
2 - Microservices Architecture
3 - Serverless Architecture
4 - API
5 - Three Tier Architecture
6 - Cloud Storage Options
7 - Caching
8 - Load Balancer vs API gateway
9 - Server vs Serverless Scaling
10 - Project | Design an Architecture for an E-commerce application
11 - Project | Design an Architecture for Youtube
1 —Architecture Types
It exists three major types of architecture, which are :
- Monolithic Architecture is a traditional software design where the entire application is built as a single, unified unit. This architecture typically comprises three main components: the User Interface (UI), Business Logic (Backend), and Data Interface. While it is straightforward to develop, maintain, and deploy, it presents challenges when the application needs to scale or evolve. Changes to one part of the system can affect the entire application, and scaling often requires replicating the entire monolith, leading to inefficient use of resources.
- Microservices Architecture breaks down the application into smaller, independent services. Each microservice is responsible for a specific business function, such as user authentication, product management, or payment processing. These services communicate through APIs and manage their own databases, promoting loose coupling and independent scalability. Microservices allow different teams to work on different services simultaneously, offering greater flexibility and agility. However, they also introduce complexity in terms of service coordination, data consistency, and operational overhead, requiring robust strategies for communication, security, and monitoring.
- Serverless Architecture shifts the focus from managing servers to managing individual functions. In this model, cloud providers handle the infrastructure, allowing developers to deploy event-driven functions that scale automatically in response to demand. Serverless architectures are cost-efficient because you only pay for the compute time used when a function is actively running. This model is particularly well-suited for applications with variable or unpredictable traffic patterns, such as event-driven workloads, real-time data processing, or backend APIs. However, serverless functions are stateless, which can complicate state management across executions, and they may suffer from latency issues due to cold starts.
Use Cases
- Monolithic Architecture: Ideal for small-scale applications, startups, or legacy systems where simplicity and a quick time-to-market are more critical than scalability and flexibility.
- Microservices Architecture: Use Cases: Best suited for large, complex applications that require high availability, independent scaling, and continuous deployment. Examples include e-commerce platforms, social media sites, and large-scale SaaS applications.
- Serverless Architecture: Use Cases: Ideal for event-driven applications, real-time data processing, and applications with variable workloads like chatbots, IoT backends, or video processing services.
Advantages and Drawbacks
Monolithic Architecture Advantages:
- Simplicity: Single codebase, easy to understand and manage.
- Unified Environment: Streamlined debugging, testing, and deployment processes.
- Centralized Management: Suitable for small teams where centralized decision-making is possible.
Monolithic Architecture Drawbacks:
- Scalability: Vertical scaling is limited and can become expensive. Horizontal scaling requires duplicating the entire application.
- Lack of Flexibility: Tight coupling makes it difficult to implement changes or new features without affecting the entire system.
- Deployment Complexity: Deploying updates requires redeploying the entire application, increasing the risk of downtime.
Microservices Architecture Advantages:
- Scalability: Services can be scaled independently, allowing for optimized resource allocation.
- Flexibility: Each service can use different technologies, languages, and databases suited to its needs.
- Resilience: Isolated failures prevent cascading issues across the system.
- Agility: Faster development cycles with independent service updates.
Microservices Architecture Drawbacks:
- Complexity: Requires careful management of inter-service communication, data consistency, and distributed transactions.
- Operational Overhead: Multiple services mean more deployment pipelines, monitoring tools, and infrastructure to manage.
- Security and Testing: Requires robust security measures and complex testing strategies to ensure all services work seamlessly together.
Serverless Architecture Advantages:
- Cost Efficiency: Pay-per-execution model reduces costs, especially for applications with variable traffic.
- Automatic Scaling: Scales automatically based on demand without manual intervention.
- No Infrastructure Management: Cloud provider manages scaling, patching, and server provisioning.
- Faster Development: Focus on business logic rather than server management, supporting rapid iteration and deployment.
Serverless Architecture Drawbacks:
- Cold Starts: Functions may experience delays when first invoked after being idle.
- Execution Time Limits: Not suitable for long-running processes.
- Statelessness: Requires external services for state management.
- Vendor Lock-In: Reliance on specific cloud providers can make migration difficult.
How can it helps ?
Understanding the strengths and weaknesses of each architecture is crucial for making informed decisions. The right choice depends on factors like application complexity, expected traffic patterns, development team size, and long-term scalability needs. By evaluating these aspects, architects can select the most appropriate architecture to build scalable, resilient, and efficient systems.
2 — API
An API (Application Programming Interface) is a communication bridge that allows different software applications to interact. It defines a set of rules for accessing and utilizing the features of an application, service, or system. APIs function similarly to a server in a restaurant, where the API takes requests (orders) from clients (users or applications), communicates with the backend (kitchen), and returns responses (meals).
Key Elements of an API
- Actions or Operations: APIs provide endpoints for actions like GET (retrieve data), POST (submit data), PUT (update data), and DELETE (remove data), defining how developers can interact with the application.
- API Documentation: Acts as a guide, detailing available endpoints, HTTP methods, required parameters, and possible responses, often in formats like JSON or XML.
- Request and Response Cycle: The API receives a request from the client, processes it through the backend, and returns the appropriate response.
Importance of APIs
- Efficient Communication: APIs ensure structured and consistent data exchange between different systems.
- Customization and Flexibility: Developers can customize their requests to retrieve or modify specific data, allowing tailored integrations.
- Seamless Integration: In complex architectures like microservices or cloud systems, APIs enable various components to work together seamlessly.
Types of APIs
- Web APIs (HTTP/REST APIs): Commonly used in web development, these APIs communicate over HTTP and are stateless, making them simple and scalable.
- SOAP APIs: Use XML for requests and responses, providing strict security and transaction standards, suitable for sectors like banking.
- GraphQL APIs: Allow clients to specify exactly what data is needed, reducing data over-fetching or under-fetching.
- Internal APIs: Used within organizations for internal communication between systems, improving processes without public exposure.
Benefits of Using APIs
- Modular Development: Enables independent development and maintenance of different application components, facilitating scalability.
- Interoperability: Allows applications built with different technologies to communicate, crucial in environments with diverse technology stacks.
- Faster Development: By using existing APIs, developers can quickly integrate functionalities like authentication or payment processing.
- Innovation and Collaboration: APIs allow external developers to extend a product’s functionality, fostering collaboration and innovation.
Why it matters ?
APIs are essential in modern software development, serving as a bridge between systems, applications, and services. They abstract the complexity of backend systems and provide developers with tools to build flexible, scalable, and interoperable applications. Whether it’s a REST API for web communication, a SOAP API for secure transactions, or a GraphQL API for tailored data retrieval, APIs are crucial for efficient integration and scalability in today’s digital landscape.
3 — Three Tier Architecture #new
Three-tier architecture is a software design pattern that divides an application into three layers: the presentation layer, application (business logic) layer, and data layer. This structure is commonly used in various architectural models, including monolithic, microservices, and serverless architectures, to create scalable and maintainable applications.
The Three Tiers
- Presentation Tier (UI Layer): This is the front end where users interact with the application, such as web interfaces or mobile apps. It handles the display of data and user input, communicating with the backend to process requests.
- Application Tier (Business Logic Layer): Also known as the middle layer, this tier processes business logic and rules. It manages requests from the presentation layer, performs computations, and interacts with the data layer.
- Database Tier (Data Layer): This layer is responsible for data storage, management, and retrieval. It uses databases (relational or NoSQL) to store persistent data and ensures data integrity and security.
Benefits of Three-Tier Architecture
- Scalability: Each tier can be scaled independently. For instance, more servers can be added to the presentation layer to handle increased user traffic or to the application layer to process more complex business logic.
- Maintainability: Clear separation of concerns makes it easier to update or modify one layer without affecting the others, enhancing the system’s maintainability.
- Reusability: Components like the business logic layer can be reused across different interfaces (e.g., web and mobile apps), reducing code duplication.
- Flexibility: Each layer can use different technologies, providing flexibility in choosing the most suitable tools for each part of the system.
How It Works
- User Interaction: Users interact with the frontend (presentation layer) by making requests (e.g., submitting forms).
- Processing Requests: The application layer receives and processes these requests, applying business logic and, if needed, interacting with the data layer.
- Data Management: The database layer stores or retrieves data as instructed by the application layer.
- Response: The application layer sends the processed data back to the presentation layer, which displays it to the user.
Why it matters ?
Three-tier architecture offers a structured approach for building scalable, maintainable, and flexible applications. By separating the application into three distinct layers, developers can create modular systems that can evolve and scale independently. This architecture is particularly suitable for web, enterprise, and cloud-based applications where scalability and maintainability are essential.
4 — Cloud Storage Options
Within the cloud, there are several storage options available, each designed to meet different types of data storage needs. The three main types of cloud storage include file storage, block storage, and object storage. Each offers unique advantages, use cases, and trade-offs in terms of performance, scalability, and cost.
File Storage
File storage is a method of storing data in a hierarchical structure of files and folders. This structure resembles traditional file systems used on physical servers or personal computers. Data is organized into directories and subdirectories, making it familiar and easy to navigate for many users and applications.
When to Use File Storage?
- Shared file systems: Ideal when applications need to access a shared file system across multiple instances.
- User directories: Suitable for user directories, such as home directories where users store personal files.
- Structured hierarchy: Perfect for storing files and folders in a well-defined, structured hierarchy.
- Legacy applications: Useful for older applications designed to work with traditional file systems.
Advantages of File Storage
- Familiar structure: File storage follows the same directory-based organization most users are accustomed to.
- File-level operations: It supports file-level operations such as open, close, read, write, and navigation through the directory structure.
- Ease of use: Easy to integrate with applications that already depend on file systems.
Drawbacks of File Storage
- Scalability limitations: File storage is generally less scalable compared to object storage, especially when dealing with massive amounts of data.
- Performance degradation: The performance can degrade when there are high numbers of files or multiple users accessing the system simultaneously.
Example: Amazon EFS (Elastic File System) — A scalable file storage solution for use with Amazon EC2 instances.
Block Storage
Block storage stores data in fixed-size blocks, each with a unique identifier. These blocks are managed individually, and multiple blocks can be combined to form a larger storage volume. Block storage is typically used in Storage Area Networks (SANs) and is ideal for applications requiring high performance and low latency.
When to Use Block Storage ?
- Databases and transactional data: Best suited for databases or transactional applications that require high input/output (I/O) operations.
- Virtual machines and containers: Essential for running virtual machines or containers that need direct access to a file system.
- Raw, unformatted storage: Useful for applications that require raw storage, as block storage behaves like a physical hard drive.
Advantages :
- High performance: Block storage is known for delivering high performance with low latency, making it suitable for demanding workloads.
- Control: Provides granular control over storage, as each block can be managed independently, like an individual hard drive.
- Customizable: Blocks can be combined or partitioned as needed to create specific storage structures.
Drawbacks :
- Higher cost: Block storage is typically more expensive than file or object storage due to its high performance and specialized use cases.
- Less scalable: It does not scale as efficiently as object storage in terms of both capacity and management.
- Management overhead: Block storage often requires manual management to scale, which can introduce additional complexity and operational overhead.
Example: Amazon EBS (Elastic Block Store) — A high-performance block storage solution for use with Amazon EC2 instances.
Object Storage
Object storage is designed for managing unstructured data as objects. Each object contains the data itself, along with associated metadata and a unique identifier. This makes object storage particularly well-suited for storing large volumes of unstructured data such as media files, backups, and archives.
When to Use Object Storage ?
- Unstructured data: Ideal for storing large amounts of unstructured data like photos, videos, and logs.
- Web content: Suitable for content that needs to be accessed via HTTP/HTTPS, such as static files for websites.
- Archiving and backups: Well-suited for archiving or backing up data due to its unlimited scalability.
Advantages ?
- Highly scalable: Object storage can scale horizontally without limits, making it perfect for growing data sets.
- Unlimited capacity: Supports virtually unlimited storage capacity, ideal for cloud-native applications and big data.
- Accessibility: Data can be accessed from anywhere, enabling global access to stored objects.
- Metadata: Objects can store rich metadata, which can be used for search and analytics purposes, making it a powerful tool for indexing and managing large datasets.
Drawbacks ?
- Not suitable for traditional file systems: Object storage does not provide the hierarchical structure needed for applications that rely on file systems or require frequent, complex updates.
- Higher latencies: Object storage generally has higher latencies than block storage, making it less ideal for real-time or high-performance applications.
Example: Amazon S3 (Simple Storage Service) — A highly scalable object storage service designed for storing and retrieving any amount of data at any time.
Choosing the Right Storage Option
Selecting the right cloud storage option depends on several factors, including:
- Application requirements: Does the application need structured data storage (file storage), high-performance transactional data storage (block storage), or scalable unstructured data storage (object storage)?
- Performance needs: If low latency and high throughput are critical, block storage might be the best option. If scalability is the primary concern, object storage is likely the right choice.
- Scalability: Object storage provides the highest scalability, while block storage is more limited in this regard.
- Cost considerations: Block storage tends to be the most expensive due to its high performance, while object storage offers more cost-effective scalability for large data sets.
5 — Caching
Caching is a technique that temporarily stores data in a cache, a temporary storage location, to enable faster data retrieval. Instead of fetching data from the primary storage location (like a database or external API) every time it is requested, caching stores frequently accessed data closer to the application. This significantly improves efficiency and performance by reducing the time it takes to access data and lowering the load on the main storage system.
In short, caching saves time and resources by avoiding unnecessary trips to the primary data source, making it ideal for improving the performance of systems that frequently access the same data.
Why is Caching Important?
Caching plays a critical role in enhancing both the performance and scalability of systems, especially in data-intensive applications. Here are the main reasons why caching is important:
Performance Improvement :
Caching improves response times and reduces latency, making applications much faster. In high-traffic systems or data-heavy applications, even a few milliseconds of delay can impact user satisfaction.
- Example: A web application that frequently queries a database for the same data can use caching to speed up data retrieval and improve user experience.
Scalability :
By reducing the number of trips to the backend (like databases or APIs), caching helps decrease the load on the system, making it more scalable. Caching allows systems to handle more concurrent users without degrading performance.
Cost Savings :
In cloud environments, every resource usage incurs operational costs. Caching helps save money by reducing the need for frequent access to high-computation resources. Accessing data from cache requires less compute power, reducing costs related to:
- Data transfer
- Storage I/O (input/output) operations
- Compute resources
Caching can also reduce data transfer costs and I/O costs by minimizing read and write operations to the primary database.
Types of Caching
Different types of caching are used to address specific performance bottlenecks in modern applications:
- Browser Caching : Browser caching stores files such as HTML, CSS, JavaScript, and images locally on the user’s browser. When a user revisits a webpage, the browser retrieves these files from the local cache instead of downloading them again from the server.
- Content Delivery Network (CDN) Caching : A Content Delivery Network (CDN) is a distributed network of servers that store cached copies of content geographically closer to the user. CDNs cache static content (such as images, videos, and web pages) in multiple locations worldwide to reduce the time it takes to deliver content.
- In-Memory Caching : In-memory caching stores data directly in the RAM (Random Access Memory) of the server, making data retrieval much faster than reading from disk storage. This type of caching is ideal for data that requires frequent access but doesn’t need permanent storage.
- Database Caching : Database caching involves temporarily storing the results of expensive database queries. When a query is executed, the system first checks the cache to see if the result is already stored. If not, it fetches the data from the database and stores it in the cache for future use.
- Application Caching : Application caching stores user session data or user preferences at the application level. This type of caching can be implemented within the application’s code or through external caching systems.
Why Caching Matters ?
Caching is a powerful technique that helps applications achieve better performance, scalability, and cost-efficiency by temporarily storing frequently accessed data closer to where it is needed. Whether it’s through browser caching, CDN caching, in-memory caching, database caching, or application caching, the strategic use of caches can:
- Optimize resource usage
- Reduce costs
- Improve overall system performance
In cloud environments, caching can significantly reduce operational costs and improve response times, making it an essential component of modern system design.
6 — Load Balancer
A load balancer is designed to distribute incoming network traffic across multiple servers, ensuring no single server becomes overwhelmed by requests. This not only optimizes resource utilization but also improves the system’s overall reliability, availability, and performance.
How Load Balancers Work
- Traffic Routing: Load balancers use various algorithms to route incoming requests to the most suitable server. Common routing algorithms include : (Round-robin, Least connection, IP Hash…)
- Scaling Resources: Load balancers can dynamically scale server resources in response to traffic spikes. This ensures efficient utilization during high demand and conserves resources during low traffic periods by scaling down the server count.
- Application Delivery Features: Modern load balancers, often part of an Application Delivery Controller (ADC), offer additional features such as caching and compression, improving performance further.
Benefits of Load Balancers
- Improved Reliability: Distributes traffic across multiple servers, reducing the risk of any single point of failure.
- High Availability: Ensures that the application remains available even if some servers are down or under maintenance.
- Enhanced Performance: Balances the load to prevent server overloads, thereby reducing latency and improving response times.
Types of Load Balancers
- Hardware Load Balancers: Deployed as physical devices in a data center.
- Software Load Balancers: Virtualized instances that run on cloud or on-premise environments.
Use Cases
Load balancers are essential in scenarios where you need to distribute traffic evenly across servers to maintain high availability, especially in distributed systems or cloud-based applications.
7 — API Gateway
An API Gateway acts as a single entry point for all client requests destined for various backend services. In microservices architectures, an API Gateway plays a crucial role by decoupling the client interface from the backend, managing and routing requests to the appropriate microservice.
How API Gateways Work
- Request Routing and Aggregation: The API Gateway can aggregate multiple client requests and route them to the appropriate microservices. This is particularly useful when a client action requires data or services from multiple microservices.
- Security and Authentication: API Gateways enforce security policies such as authentication, authorization, and rate limiting to control traffic and protect backend services. They also handle SSL termination, reducing the burden on backend servers.
- Traffic Management: In addition to routing requests, API Gateways manage API-level traffic, including rate limiting (to avoid abuse) and logging (for monitoring and analytics).
Benefits of API Gateways
- Simplifies Client Interactions: Clients interact with a single, unified API endpoint, while the gateway handles communication with the multiple backend services.
- Enhanced Security: The API Gateway can act as a security layer, managing authentication and preventing unauthorized access, while hiding internal services from direct exposure to clients.
- Rate Limiting and Traffic Control: The gateway can throttle requests to prevent overloading backend services and improve scalability.
Use Cases for API Gateways
- Microservices Architectures: API Gateways are especially useful in microservices environments, where they simplify interactions between the client and numerous backend services.
- Security Management: They centralize security enforcement, ensuring that all client requests adhere to the same access controls and policies.
- Request Handling: Aggregating multiple requests into one reduces the number of client-server interactions, improving efficiency and performance.
8 — Load Balancers vs API Gateways
Although load balancers and API gateways both manage traffic, they have distinct purposes and capabilities:
Primary Focus
- Load Balancer: Focuses on traffic distribution, ensuring that requests are evenly routed to backend servers to optimize resource usage and prevent overloading.
- API Gateway: Focuses on API management, routing API requests to the appropriate microservices while managing authentication, rate limiting, and aggregating requests.
Implementation
- Load Balancer: Typically operates at the network or transport layer (Layer 4 or Layer 7), distributing traffic between multiple servers.
- API Gateway: Operates at the application layer (Layer 7), specifically managing API requests and handling API-level functionality such as security, logging, and transformation of data.
Traffic Management
- Load Balancer: Manages general traffic routing by distributing incoming requests across multiple servers using various algorithms.
- API Gateway: Handles API-specific requests by routing them to the correct microservice, while also performing additional functions like rate limiting, caching, and logging.
Capabilities
- Load Balancer: Primarily focused on distributing traffic and scaling resources.
- API Gateway: Provides a wider range of functionality, including security enforcement, request aggregation, and traffic control.
Service Exposure
- Load Balancer: Primarily focused on backend traffic distribution across servers, it does not expose specific backend services to clients.
- API Gateway: Acts as the public-facing interface for microservices, enabling external clients to interact with the backend through a single API entry point.
Conclusion
Both load balancers and API gateways are essential tools in modern distributed systems, but they serve different purposes:
- Load balancers ensure high availability, reliability, and performance by distributing traffic across servers, preventing overloads, and maintaining system uptime.
- API gateways provide a centralized way to manage API traffic, enhance security, and simplify client interactions with complex backend services, particularly in microservices architectures.
Understanding the distinct roles of each helps organizations design systems that are scalable, secure, and resilient, optimizing both backend performance and user experience.
In modern cloud architectures, scaling is a crucial factor in ensuring that applications can handle varying amounts of traffic efficiently. Servers (virtual machines) and serverless functions represent two distinct approaches to scaling, each with its own advantages and challenges. Understanding the differences between vertical scaling, horizontal scaling, and serverless scaling is essential for choosing the right strategy for your application.
9 — Vertical Scaling (Servers)
Vertical scaling refers to increasing the capacity of a single server (or virtual machine) by adding more resources, such as CPU, memory, or storage.
How does Vertical Scaling Works ?
- To scale a virtual machine, you typically stop the server and switch to a more powerful instance type that offers more resources.
- Once the new instance is ready, you redirect the traffic to the updated machine.
Key Benefits
- Simplicity: Vertical scaling is straightforward, as it involves simply increasing the resources available to a single server.
- Quick and Easy: For small or medium workloads, this method is quick to implement since you are only working with a single machine.
Limitations
- Resource Limits: Vertical scaling is limited by the maximum capacity of the server or instance type. There’s a finite limit to how much CPU and memory you can add.
- Downtime: The process typically involves stopping the machine and launching a new one, which can introduce downtime and impact availability.
- Repeated Process: Every time the server reaches capacity, you need to repeat this process, and eventually, you will reach the physical or virtual limits of the server.
Use Case
- Vertical scaling is ideal for smaller applications or systems with predictable workloads that don’t require massive scaling or where simplicity is prioritized.
10 — Horizontal Scaling (Servers)
Horizontal scaling, also known as scaling out, involves adding more servers to distribute the load rather than increasing the capacity of a single server. This is the preferred method for large, distributed systems.
How Horizontal Scaling Works
- Instead of upgrading a single server, you add more servers to a scaling group.
- Traffic is automatically balanced between these servers, effectively removing capacity limits, as more machines can be added as needed.
Key Benefits
- Unlimited Scalability: Horizontal scaling removes the physical limitations of a single machine, allowing you to scale out infinitely by adding more servers to handle increased traffic.
- Fault Tolerance: By distributing traffic across multiple servers, you increase the system’s resilience, as the failure of one machine does not impact the entire system.
- Automated Scaling: In modern cloud environments, horizontal scaling can be automated using autoscaling groups that dynamically add or remove servers based on real-time demand.
Limitations
- Increased Complexity: Managing a large number of servers introduces more complexity in terms of orchestration, maintenance, and monitoring.
- Cost: Adding more servers to handle traffic spikes can increase operational costs, especially if traffic is inconsistent or unpredictable.
Use Case
- Horizontal scaling is ideal for large-scale applications that require high availability, resilience, and the ability to handle high traffic volumes, such as e-commerce websites or video streaming platforms.
11 — Serverless Scaling
Serverless scaling is fundamentally different from traditional server-based scaling. In a serverless environment, the cloud provider automatically manages the scaling of resources based on incoming requests, without the need for manual intervention or predefined capacity limits.
How Serverless Scaling Works
- Each incoming request triggers a new instance of a serverless function (such as AWS Lambda, Google Cloud Functions, or Azure Functions).
- The cloud provider handles the scaling seamlessly, ensuring that the application can handle any amount of traffic by automatically spinning up new instances as needed.
- Each instance operates independently and is short-lived, handling a single task before terminating.
Key Benefits
- Seamless Scalability: Serverless architectures can scale to handle virtually any traffic volume without the need for manual intervention. This makes it ideal for applications with unpredictable or bursty traffic.
- No Infrastructure Management: Developers don’t need to worry about managing servers or capacity planning — scaling is fully automated and managed by the provider.
- Cost Efficiency: In a serverless model, you only pay for the execution time of each function. When no requests are being processed, no resources are consumed, making serverless highly cost-effective for applications with sporadic workloads.
Limitations
- Cold Starts: Serverless functions may experience cold start latency, where there’s a slight delay when the function is invoked after being idle for a while. This can impact performance in applications requiring low-latency responses.
- Execution Limits: Serverless functions typically have execution time limits (e.g., AWS Lambda has a maximum execution time of 15 minutes), which can be a limitation for long-running processes.
- Limited Control: With serverless, you have less control over the underlying infrastructure, which can make certain customizations or configurations more challenging.
Use Case
- Serverless scaling is ideal for event-driven applications, APIs, and services that experience sporadic traffic or unpredictable loads. It’s especially beneficial for workloads where traffic fluctuates or where cost optimization is a priority.
12 — Server vs Serverless Scaling
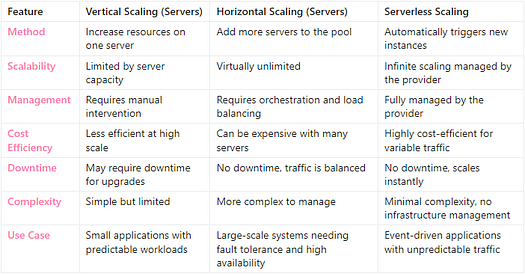
Choosing Between Server and Serverless Scaling
- Vertical Scaling is suited for small applications or systems with predictable workloads where simplicity is more important than scalability.
- Horizontal Scaling is essential for large applications that need to handle high traffic volumes and require fault tolerance and resilience.
- Serverless Scaling offers the best solution for event-driven or unpredictable workloads, providing seamless scaling and cost efficiency without the need to manage infrastructure.
Each approach has its advantages and limitations, and the choice depends on the specific requirements of your application, including performance needs, scalability, and cost considerations.
13 — Project | Design an Architecture for an E-commerce application
This project can be found here.
14 — Project | Design an Architecture for Youtube
This project can be found here.